Department of Computer Science, Dartmouth College, Hanover, New Hampshire, United States of America.
PLoS One. 2011 Feb 8;6(2):e16431. doi: 10.1371/journal.pone.0016431.
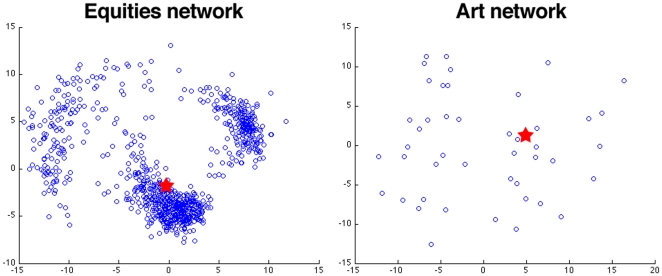
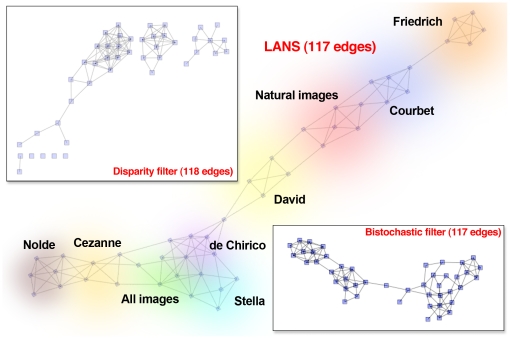
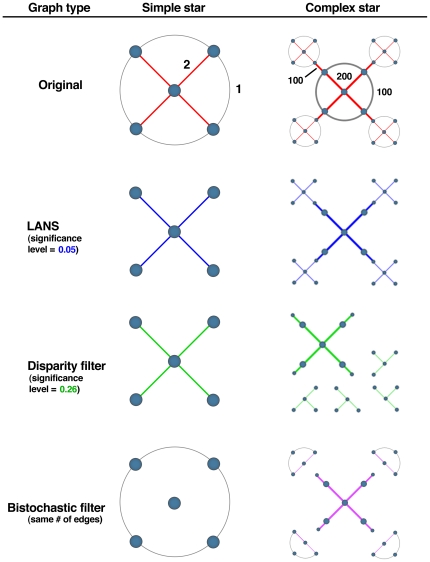
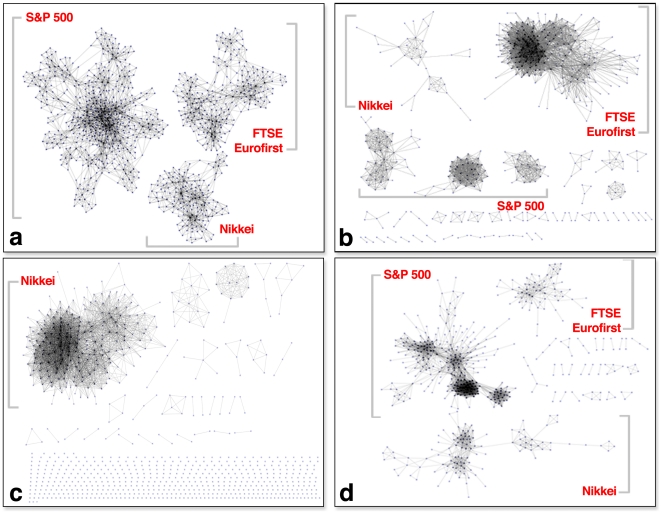
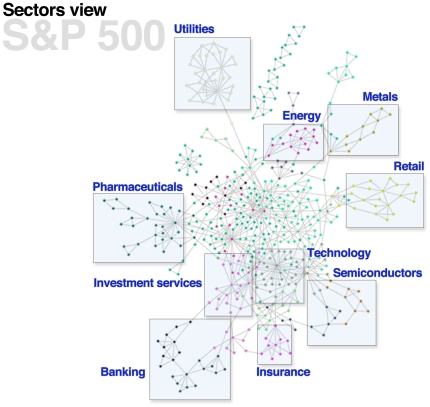
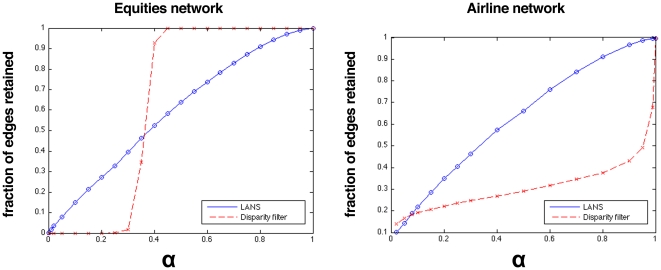
Many real-world networks tend to be very dense. Particular examples of interest arise in the construction of networks that represent pairwise similarities between objects. In these cases, the networks under consideration are weighted, generally with positive weights between any two nodes. Visualization and analysis of such networks, especially when the number of nodes is large, can pose significant challenges which are often met by reducing the edge set. Any effective "sparsification" must retain and reflect the important structure in the network. A common method is to simply apply a hard threshold, keeping only those edges whose weight exceeds some predetermined value. A more principled approach is to extract the multiscale "backbone" of a network by retaining statistically significant edges through hypothesis testing on a specific null model, or by appropriately transforming the original weight matrix before applying some sort of threshold. Unfortunately, approaches such as these can fail to capture multiscale structure in which there can be small but locally statistically significant similarity between nodes. In this paper, we introduce a new method for backbone extraction that does not rely on any particular null model, but instead uses the empirical distribution of similarity weight to determine and then retain statistically significant edges. We show that our method adapts to the heterogeneity of local edge weight distributions in several paradigmatic real world networks, and in doing so retains their multiscale structure with relatively insignificant additional computational costs. We anticipate that this simple approach will be of great use in the analysis of massive, highly connected weighted networks.
许多真实世界的网络往往非常密集。在构建表示对象之间成对相似性的网络时,会出现特别感兴趣的示例。在这些情况下,所考虑的网络是加权的,通常在任何两个节点之间具有正权重。这些网络的可视化和分析,特别是当节点数量很大时,可能会带来重大挑战,通常通过减少边集来应对。任何有效的“稀疏化”都必须保留和反映网络中的重要结构。一种常见的方法是简单地应用硬阈值,只保留那些权重超过某个预定值的边。一种更有原则的方法是通过在特定的零模型上进行假设检验来保留统计上显著的边,或者在应用某种阈值之前适当地转换原始权重矩阵,从而提取网络的多尺度“主干”。不幸的是,这些方法可能无法捕捉到具有节点之间小但局部统计显著相似性的多尺度结构。在本文中,我们引入了一种新的主干提取方法,该方法不依赖于任何特定的零模型,而是使用相似性权重的经验分布来确定并保留统计上显著的边。我们表明,我们的方法适应了几个范例现实世界网络中局部边权重分布的异质性,并且在这样做的过程中,以相对较小的额外计算成本保留了它们的多尺度结构。我们预计这种简单的方法将在大规模、高度连接的加权网络的分析中非常有用。