Department of Molecular Biology, Princeton University, Princeton, NJ, USA.
BMC Bioinformatics. 2011 Mar 31;12:90. doi: 10.1186/1471-2105-12-90.
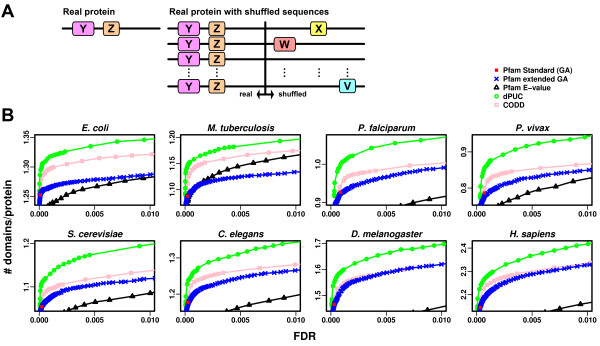
Identifying domains in protein sequences is an important step in protein structural and functional annotation. Existing domain recognition methods typically evaluate each domain prediction independently of the rest. However, the majority of proteins are multidomain, and pairwise domain co-occurrences are highly specific and non-transitive.
Here, we demonstrate how to exploit domain co-occurrence to boost weak domain predictions that appear in previously observed combinations, while penalizing higher confidence domains if such combinations have never been observed. Our framework, Domain Prediction Using Context (dPUC), incorporates pairwise "context" scores between domains, along with traditional domain scores and thresholds, and improves domain prediction across a variety of organisms from bacteria to protozoa and metazoa. Among the genomes we tested, dPUC is most successful at improving predictions for the poorly-annotated malaria parasite Plasmodium falciparum, for which over 38% of the genome is currently unannotated. Our approach enables high-confidence annotations in this organism and the identification of orthologs to many core machinery proteins conserved in all eukaryotes, including those involved in ribosomal assembly and other RNA processing events, which surprisingly had not been previously known.
Overall, our results demonstrate that this new context-based approach will provide significant improvements in domain and function prediction, especially for poorly understood genomes for which the need for additional annotations is greatest. Source code for the algorithm is available under a GPL open source license at http://compbio.cs.princeton.edu/dpuc/. Pre-computed results for our test organisms and a web server are also available at that location.
在蛋白质结构和功能注释中,识别蛋白质序列中的结构域是一个重要步骤。现有的结构域识别方法通常独立地评估每个结构域预测。然而,大多数蛋白质都是多结构域的,并且结构域的成对共现具有高度的特异性和非传递性。
在这里,我们展示了如何利用结构域共现来增强在以前观察到的组合中出现的弱结构域预测,同时对从未观察到这种组合的更高置信度结构域进行惩罚。我们的框架,即使用上下文进行结构域预测(Domain Prediction Using Context,dPUC),结合了结构域之间的成对“上下文”得分,以及传统的结构域得分和阈值,从而提高了从细菌到原生动物和后生动物等各种生物体的结构域预测。在我们测试的基因组中,dPUC 最成功地改进了对注释较差的疟原虫 Plasmodium falciparum 的预测,目前该寄生虫基因组中超过 38%的区域未被注释。我们的方法可以在该生物体中实现高置信度的注释,并鉴定出与所有真核生物中保守的许多核心机制蛋白的同源物,包括参与核糖体组装和其他 RNA 处理事件的蛋白,这些蛋白令人惊讶的是以前并不知道。
总的来说,我们的结果表明,这种新的基于上下文的方法将在结构域和功能预测方面提供显著的改进,特别是对于那些需要额外注释的理解较差的基因组,这些注释的需求最为迫切。该算法的源代码可在 GPL 开源许可证下在 http://compbio.cs.princeton.edu/dpuc/ 获得。我们测试的生物体的预计算结果和一个网络服务器也可在该位置获得。