Department of Computer Science, Iowa State University, Ames, IA 50011, USA.
BMC Bioinformatics. 2011 Jun 17;12:244. doi: 10.1186/1471-2105-12-244.
Although homology-based methods are among the most widely used methods for predicting the structure and function of proteins, the question as to whether interface sequence conservation can be effectively exploited in predicting protein-protein interfaces has been a subject of debate.
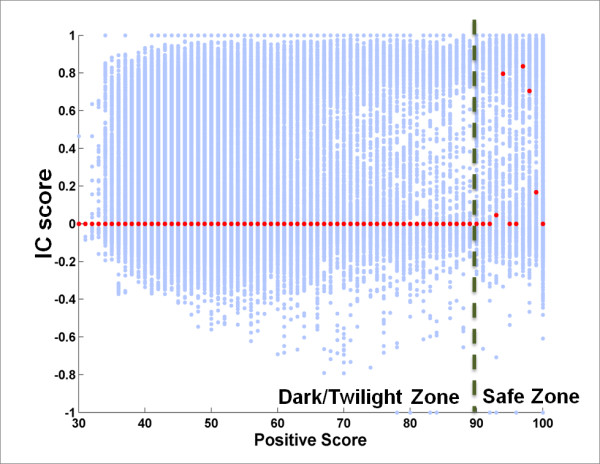
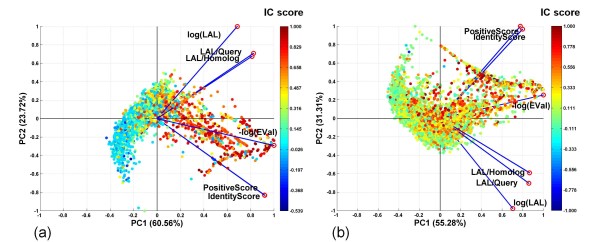
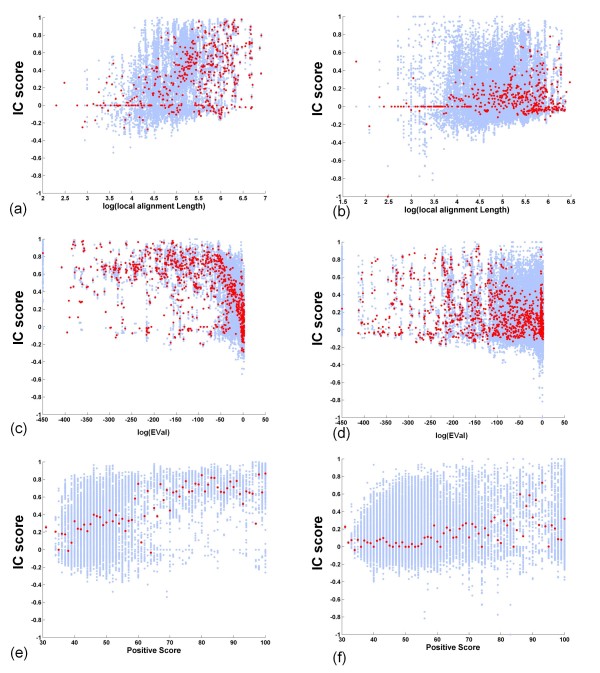
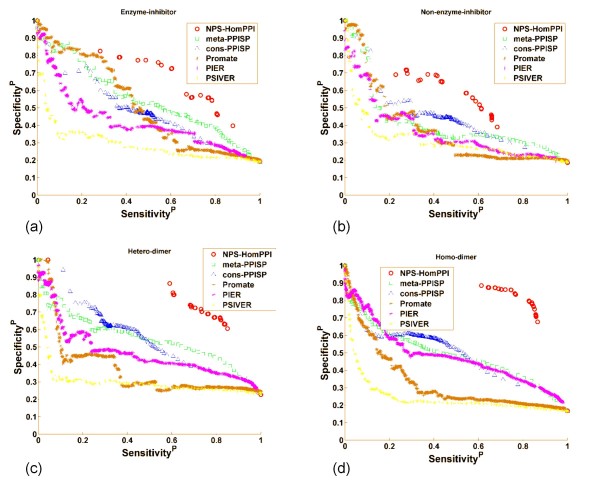
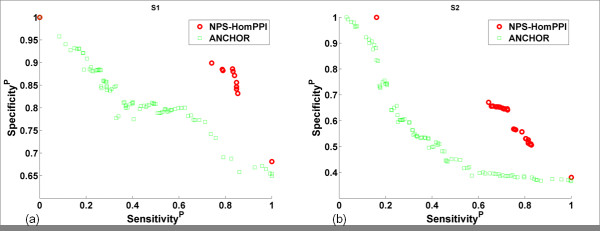
We studied more than 300,000 pair-wise alignments of protein sequences from structurally characterized protein complexes, including both obligate and transient complexes. We identified sequence similarity criteria required for accurate homology-based inference of interface residues in a query protein sequence.Based on these analyses, we developed HomPPI, a class of sequence homology-based methods for predicting protein-protein interface residues. We present two variants of HomPPI: (i) NPS-HomPPI (Non partner-specific HomPPI), which can be used to predict interface residues of a query protein in the absence of knowledge of the interaction partner; and (ii) PS-HomPPI (Partner-specific HomPPI), which can be used to predict the interface residues of a query protein with a specific target protein.Our experiments on a benchmark dataset of obligate homodimeric complexes show that NPS-HomPPI can reliably predict protein-protein interface residues in a given protein, with an average correlation coefficient (CC) of 0.76, sensitivity of 0.83, and specificity of 0.78, when sequence homologs of the query protein can be reliably identified. NPS-HomPPI also reliably predicts the interface residues of intrinsically disordered proteins. Our experiments suggest that NPS-HomPPI is competitive with several state-of-the-art interface prediction servers including those that exploit the structure of the query proteins. The partner-specific classifier, PS-HomPPI can, on a large dataset of transient complexes, predict the interface residues of a query protein with a specific target, with a CC of 0.65, sensitivity of 0.69, and specificity of 0.70, when homologs of both the query and the target can be reliably identified. The HomPPI web server is available at http://homppi.cs.iastate.edu/.
Sequence homology-based methods offer a class of computationally efficient and reliable approaches for predicting the protein-protein interface residues that participate in either obligate or transient interactions. For query proteins involved in transient interactions, the reliability of interface residue prediction can be improved by exploiting knowledge of putative interaction partners.
尽管基于同源性的方法是预测蛋白质结构和功能最广泛使用的方法之一,但界面序列保守性是否可以有效地用于预测蛋白质-蛋白质界面的问题一直存在争议。
我们研究了来自结构特征化蛋白质复合物的超过 300,000 对蛋白质序列的两两比对,包括必需的和瞬时的复合物。我们确定了准确同源推断查询蛋白质序列中界面残基所需的序列相似性标准。基于这些分析,我们开发了 HomPPI,这是一类基于序列同源性的预测蛋白质-蛋白质界面残基的方法。我们提出了 HomPPI 的两种变体:(i)NPS-HomPPI(非伙伴特异性 HomPPI),可用于在不知道相互作用伙伴的情况下预测查询蛋白质的界面残基;和(ii)PS-HomPPI(伙伴特异性 HomPPI),可用于预测具有特定靶蛋白的查询蛋白质的界面残基。我们在必需同源二聚体复合物的基准数据集上的实验表明,当可以可靠地识别查询蛋白质的序列同源物时,NPS-HomPPI 可以可靠地预测给定蛋白质中的蛋白质-蛋白质界面残基,平均相关系数(CC)为 0.76,灵敏度为 0.83,特异性为 0.78。NPS-HomPPI 还可靠地预测了无规卷曲蛋白质的界面残基。我们的实验表明,NPS-HomPPI 与包括利用查询蛋白质结构的接口预测服务器在内的几种最先进的接口预测服务器具有竞争力。特定于伙伴的分类器 PS-HomPPI 可以在大量瞬时复合物数据集上预测具有特定靶标的查询蛋白质的界面残基,当可以可靠地识别查询和靶标的同源物时,CC 为 0.65,灵敏度为 0.69,特异性为 0.70。HomPPI 网络服务器可在 http://homppi.cs.iastate.edu/ 上获得。
基于序列同源性的方法为预测参与必需或瞬时相互作用的蛋白质-蛋白质界面残基提供了一类计算效率高且可靠的方法。对于涉及瞬时相互作用的查询蛋白质,通过利用潜在相互作用伙伴的知识可以提高界面残基预测的可靠性。