EMBL-European Bioinformatics Institute, Wellcome Trust Genome Campus, Hinxton, Cambridge CB10 1SD, UK.
Database (Oxford). 2013 Apr 19;2013:bat023. doi: 10.1093/database/bat023. Print 2013.
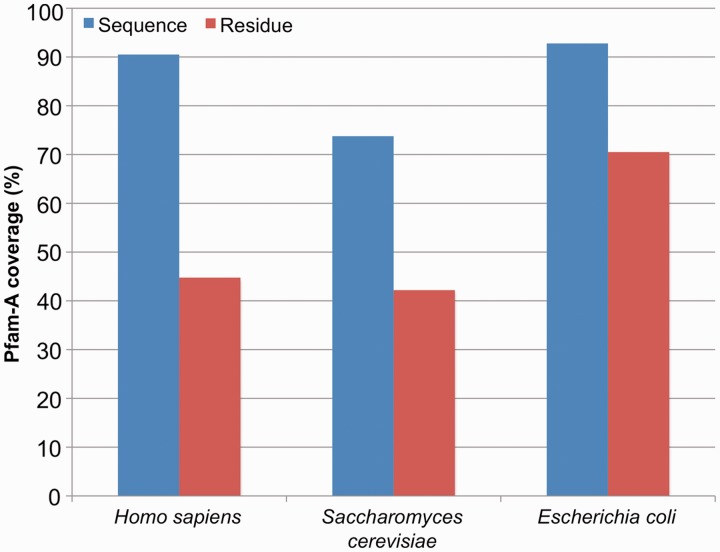
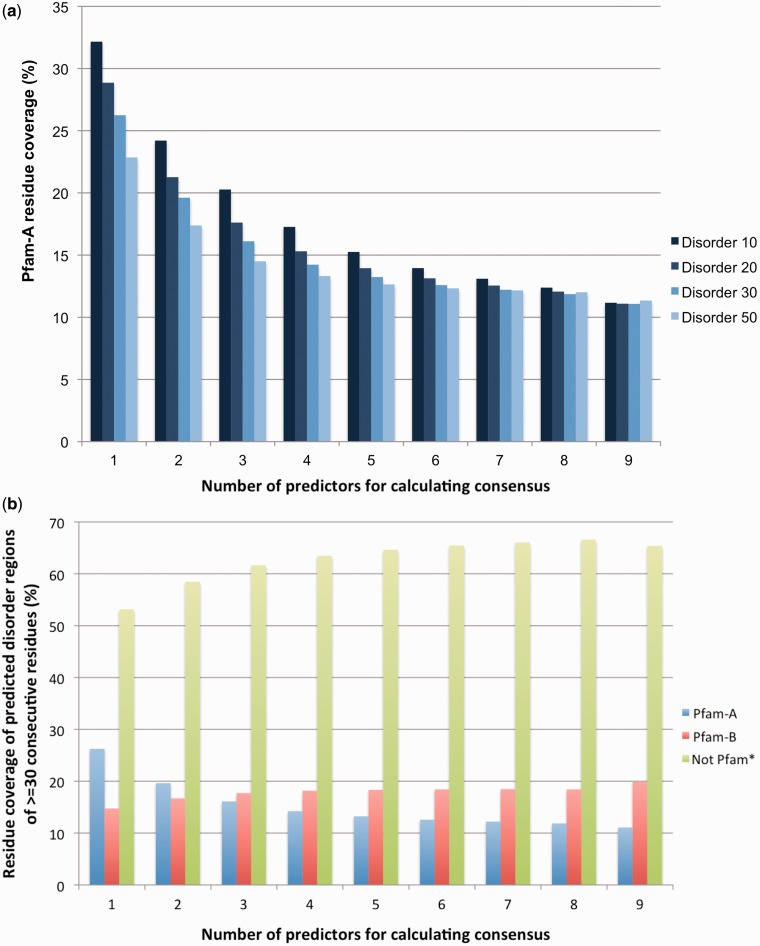
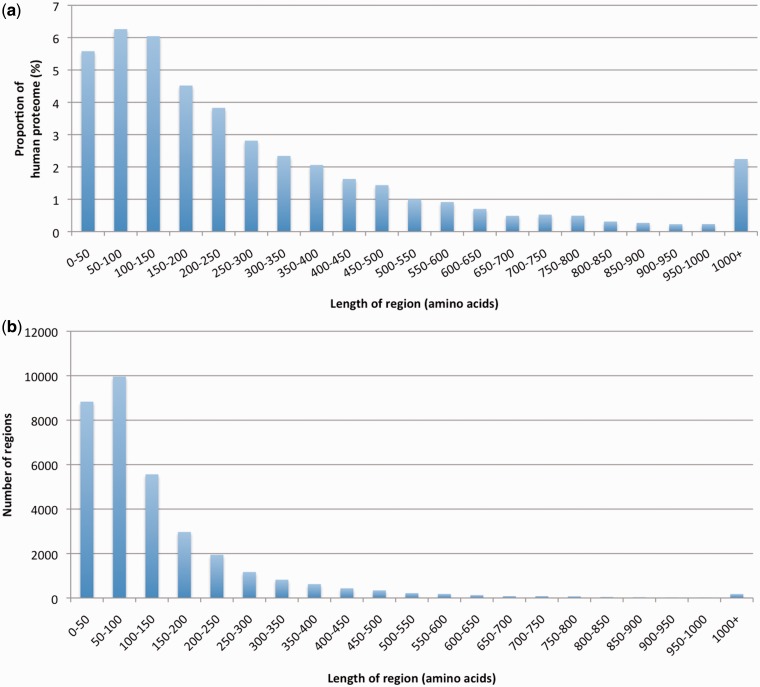
It is a worthy goal to completely characterize all human proteins in terms of their domains. Here, using the Pfam database, we asked how far we have progressed in this endeavour. Ninety per cent of proteins in the human proteome matched at least one of 5494 manually curated Pfam-A families. In contrast, human residue coverage by Pfam-A families was <45%, with 9418 automatically generated Pfam-B families adding a further 10%. Even after excluding predicted signal peptide regions and short regions (<50 consecutive residues) unlikely to harbour new families, for ∼38% of the human protein residues, there was no information in Pfam about conservation and evolutionary relationship with other protein regions. This uncovered portion of the human proteome was found to be distributed over almost 25 000 distinct protein regions. Comparison with proteins in the UniProtKB database suggested that the human regions that exhibited similarity to thousands of other sequences were often either divergent elements or N- or C-terminal extensions of existing families. Thirty-four per cent of regions, on the other hand, matched fewer than 100 sequences in UniProtKB. Most of these did not appear to share any relationship with existing Pfam-A families, suggesting that thousands of new families would need to be generated to cover them. Also, these latter regions were particularly rich in amino acid compositional bias such as the one associated with intrinsic disorder. This could represent a significant obstacle toward their inclusion into new Pfam families. Based on these observations, a major focus for increasing Pfam coverage of the human proteome will be to improve the definition of existing families. New families will also be built, prioritizing those that have been experimentally functionally characterized. Database URL: http://pfam.sanger.ac.uk/
从结构域的角度对所有人类蛋白质进行全面描述是一项有价值的目标。在这里,我们使用 Pfam 数据库来了解我们在这方面的进展程度。人类蛋白质组中的 90%的蛋白质至少与 5494 个手动注释的 Pfam-A 家族中的一个相匹配。相比之下,Pfam-A 家族对人类残基的覆盖率<45%,而 9418 个自动生成的 Pfam-B 家族又增加了 10%。即使在排除预测的信号肽区域和不太可能包含新家族的<50 个连续残基的短区域后,对于约 38%的人类蛋白质残基,Pfam 中仍没有关于与其他蛋白质区域的保守性和进化关系的信息。在 Pfam 中未发现的这部分人类蛋白质组被发现分布在近 25000 个不同的蛋白质区域中。与 UniProtKB 数据库中的蛋白质进行比较表明,与数千个其他序列具有相似性的人类区域通常是现有家族的发散元件或 N-或 C-末端延伸。另一方面,34%的区域在 UniProtKB 中与少于 100 个序列匹配。其中大多数似乎与现有的 Pfam-A 家族没有任何关系,这表明需要生成数千个新家族来覆盖它们。此外,这些区域特别富含氨基酸组成偏向性,例如与内在无序性相关的偏向性。这可能是将它们纳入新的 Pfam 家族的一个重大障碍。基于这些观察结果,增加 Pfam 对人类蛋白质组的覆盖范围的主要重点将是改进现有家族的定义。也将构建新的家族,优先考虑那些已经经过实验功能表征的家族。数据库网址:http://pfam.sanger.ac.uk/