Eugene Bell Center for Regenerative Biology and Tissue Engineering, Marine Biological Laboratory, 7 MBL Street, Woods Hole, MA 02543, USA.
Department of Computer Science and Center for Computational Molecular Biology, Brown University, 115 Waterman Street, Box 1910, Providence, RI 02912, USA.
Evodevo. 2013 Jun 3;4:16. doi: 10.1186/2041-9139-4-16. eCollection 2013.
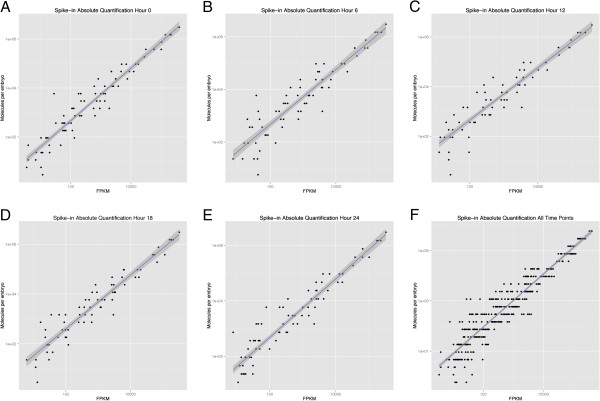
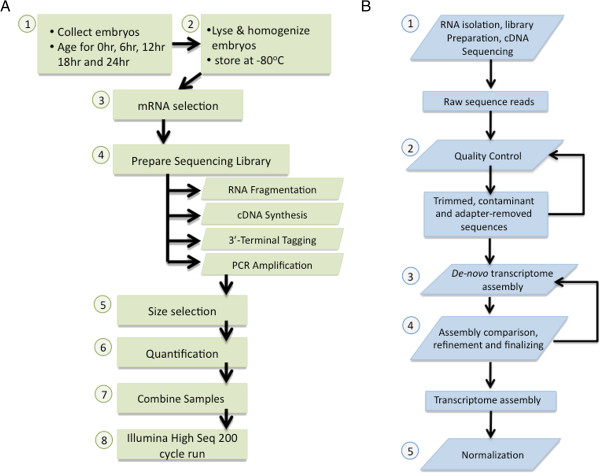
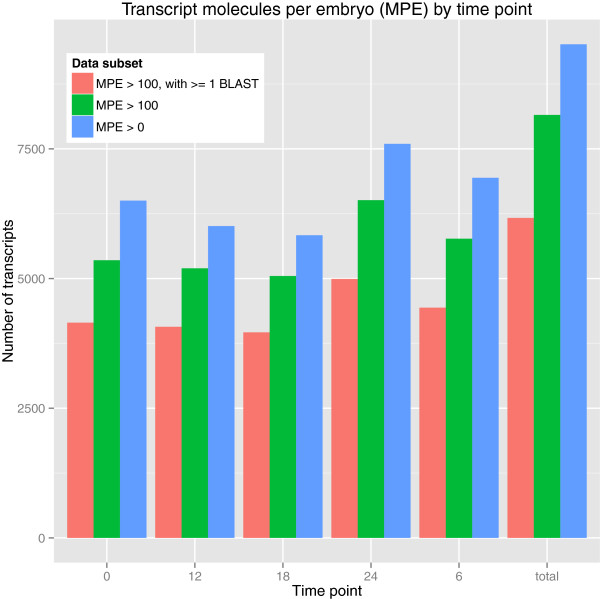
The de novo assembly of transcriptomes from short shotgun sequences raises challenges due to random and non-random sequencing biases and inherent transcript complexity. We sought to define a pipeline for de novo transcriptome assembly to aid researchers working with emerging model systems where well annotated genome assemblies are not available as a reference. To detail this experimental and computational method, we used early embryos of the sea anemone, Nematostella vectensis, an emerging model system for studies of animal body plan evolution. We performed RNA-seq on embryos up to 24 h of development using Illumina HiSeq technology and evaluated independent de novo assembly methods. The resulting reads were assembled using either the Trinity assembler on all quality controlled reads or both the Velvet and Oases assemblers on reads passing a stringent digital normalization filter. A control set of mRNA standards from the National Institute of Standards and Technology (NIST) was included in our experimental pipeline to invest our transcriptome with quantitative information on absolute transcript levels and to provide additional quality control.
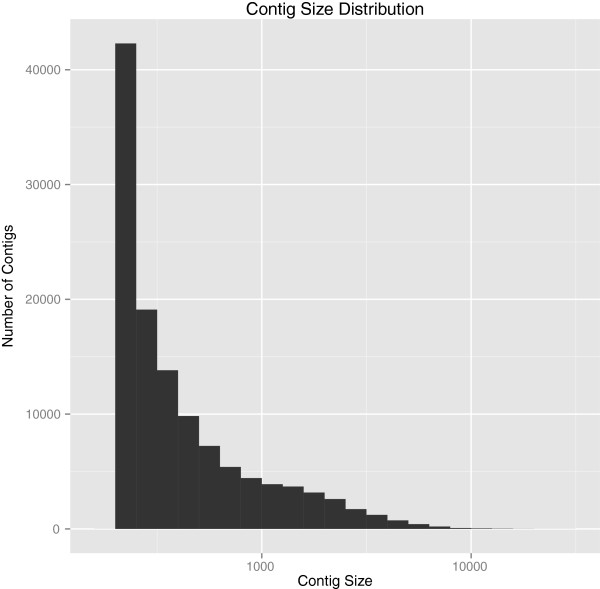
We generated >200 million paired-end reads from directional cDNA libraries representing well over 20 Gb of sequence. The Trinity assembler pipeline, including preliminary quality control steps, resulted in more than 86% of reads aligning with the reference transcriptome thus generated. Nevertheless, digital normalization combined with assembly by Velvet and Oases required far less computing power and decreased processing time while still mapping 82% of reads. We have made the raw sequencing reads and assembled transcriptome publically available.
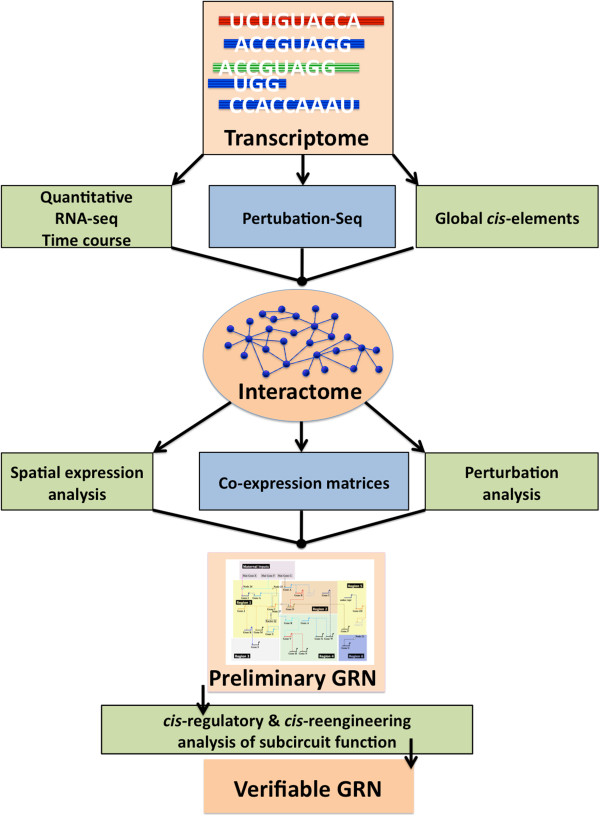
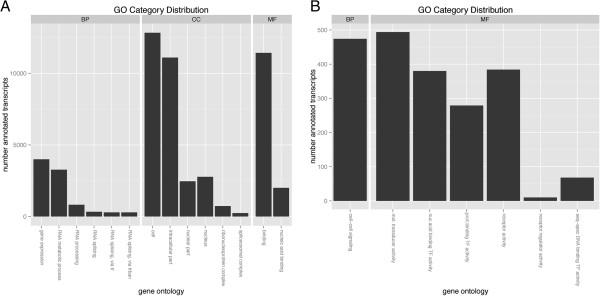
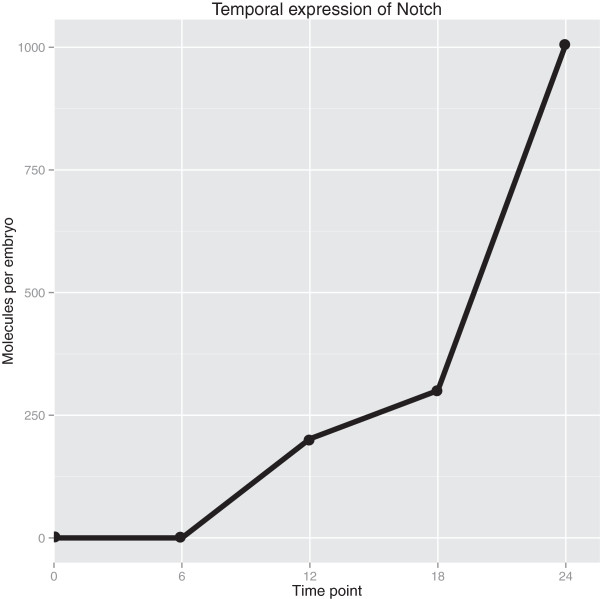
Nematostella vectensis was chosen for its strategic position in the tree of life for studies into the origins of the animal body plan, however, the challenge of reference-free transcriptome assembly is relevant to all systems for which well annotated gene models and independently verified genome assembly may not be available. To navigate this new territory, we have constructed a pipeline for library preparation and computational analysis for de novo transcriptome assembly. The gene models defined by this reference transcriptome define the set of genes transcribed in early Nematostella development and will provide a valuable dataset for further gene regulatory network investigations.
从头组装转录组的短 shotgun 序列由于随机和非随机测序偏倚以及固有转录复杂性而带来挑战。我们试图定义一个从头转录组组装管道,以帮助研究人员使用新兴的模型系统,这些系统中没有可用的注释基因组组装作为参考。为了详细说明这种实验和计算方法,我们使用了海葵 Nematostella vectensis 的早期胚胎,这是一个新兴的模型系统,用于研究动物体节进化。我们使用 Illumina HiSeq 技术对发育至 24 小时的胚胎进行了 RNA-seq,并评估了独立的从头组装方法。将经过质量控制的所有读取使用 Trinity 组装器进行组装,或者将通过严格数字归一化过滤器的读取使用 Velvet 和 Oases 组装器进行组装。我们的实验管道中包含来自国家标准与技术研究院(NIST)的一组 mRNA 标准品作为对照,以赋予转录组关于绝对转录水平的定量信息,并提供额外的质量控制。
我们从代表超过 200 Gb 序列的定向 cDNA 文库中生成了超过 2 亿对末端读取。包括初步质量控制步骤的 Trinity 组装器管道导致超过 86%的读取与由此产生的参考转录组匹配。尽管如此,数字归一化与 Velvet 和 Oases 的组装相结合,所需的计算能力要少得多,处理时间也缩短了,而仍然可以映射 82%的读取。我们已经公开了原始测序读取和组装的转录组。
选择海葵 Nematostella vectensis 是因为它在动物体节起源研究的生命之树中的战略位置,然而,无参考转录组组装的挑战与所有没有良好注释基因模型和独立验证基因组组装的系统都有关。为了应对这一新领域,我们构建了一个用于从头转录组组装的文库制备和计算分析管道。该参考转录组定义的基因模型定义了早期 Nematostella 发育过程中转录的基因集,并将为进一步的基因调控网络研究提供有价值的数据集。