Department of Biostatistics, University of Washington, Seattle, Washington 98195, USA.
Environ Health Perspect. 2013 Sep;121(9):1017-25. doi: 10.1289/ehp.1206010. Epub 2013 Jun 11.
Studies estimating health effects of long-term air pollution exposure often use a two-stage approach: building exposure models to assign individual-level exposures, which are then used in regression analyses. This requires accurate exposure modeling and careful treatment of exposure measurement error.
To illustrate the importance of accounting for exposure model characteristics in two-stage air pollution studies, we considered a case study based on data from the Multi-Ethnic Study of Atherosclerosis (MESA).
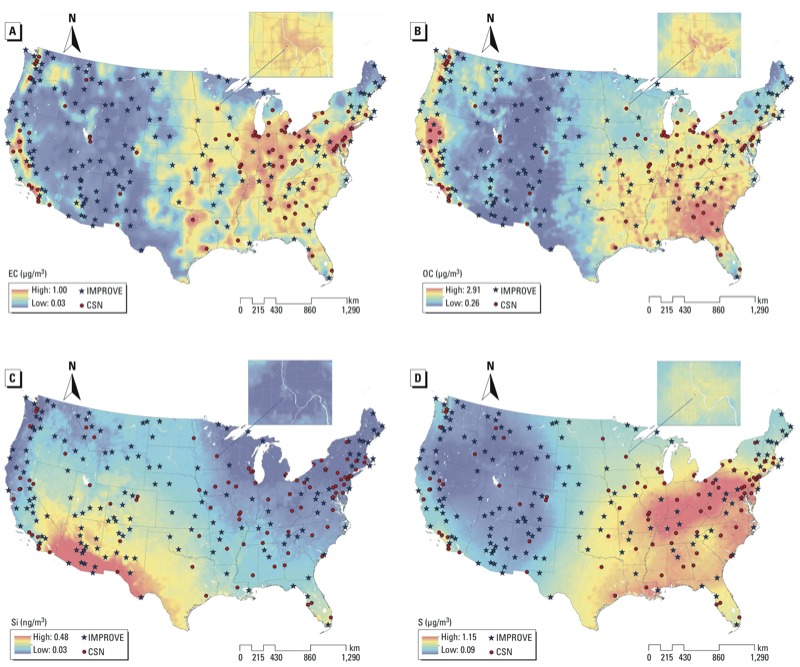
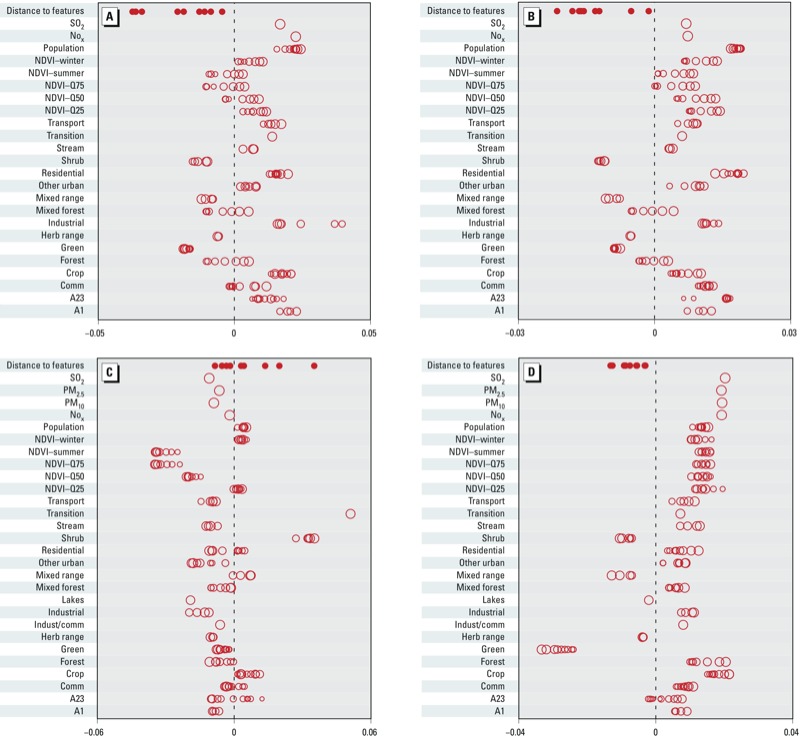
We built national spatial exposure models that used partial least squares and universal kriging to estimate annual average concentrations of four PM2.5 components: elemental carbon (EC), organic carbon (OC), silicon (Si), and sulfur (S). We predicted PM2.5 component exposures for the MESA cohort and estimated cross-sectional associations with carotid intima-media thickness (CIMT), adjusting for subject-specific covariates. We corrected for measurement error using recently developed methods that account for the spatial structure of predicted exposures.
Our models performed well, with cross-validated R2 values ranging from 0.62 to 0.95. Naïve analyses that did not account for measurement error indicated statistically significant associations between CIMT and exposure to OC, Si, and S. EC and OC exhibited little spatial correlation, and the corrected inference was unchanged from the naïve analysis. The Si and S exposure surfaces displayed notable spatial correlation, resulting in corrected confidence intervals (CIs) that were 50% wider than the naïve CIs, but that were still statistically significant.
The impact of correcting for measurement error on health effect inference is concordant with the degree of spatial correlation in the exposure surfaces. Exposure model characteristics must be considered when performing two-stage air pollution epidemiologic analyses because naïve health effect inference may be inappropriate.
研究长期空气污染暴露对健康的影响通常采用两阶段方法:构建暴露模型以分配个体水平的暴露,然后在回归分析中使用。这需要准确的暴露建模和仔细处理暴露测量误差。
为了说明在两阶段空气污染研究中考虑暴露模型特征的重要性,我们考虑了一个基于动脉粥样硬化多民族研究(MESA)数据的案例研究。
我们构建了全国空间暴露模型,使用偏最小二乘法和通用克里金法来估计四种 PM2.5 成分的年平均浓度:元素碳(EC)、有机碳(OC)、硅(Si)和硫(S)。我们预测了 MESA 队列的 PM2.5 成分暴露,并调整了个体特异性协变量,估计了与颈动脉内膜中层厚度(CIMT)的横断面关联。我们使用最近开发的方法来校正测量误差,这些方法考虑了预测暴露的空间结构。
我们的模型表现良好,交叉验证的 R2 值范围从 0.62 到 0.95。没有考虑测量误差的盲目分析表明,CIMT 与 OC、Si 和 S 暴露之间存在统计学显著关联。EC 和 OC 之间的空间相关性很小,校正后的推断与盲目分析一致。Si 和 S 暴露面显示出明显的空间相关性,导致校正后的置信区间(CI)比盲目 CI 宽 50%,但仍具有统计学意义。
校正测量误差对健康效应推断的影响与暴露面的空间相关性程度一致。在进行两阶段空气污染流行病学分析时,必须考虑暴露模型特征,因为盲目健康效应推断可能不合适。