Kopelman Naama M, Mayzel Jonathan, Jakobsson Mattias, Rosenberg Noah A, Mayrose Itay
Department of Molecular Biology and Ecology of Plants, Tel Aviv University, Ramat Aviv, 69978, Israel.
Department of Evolutionary Biology and SciLife Lab, Uppsala University, Uppsala, 75236, Sweden.
Mol Ecol Resour. 2015 Sep;15(5):1179-91. doi: 10.1111/1755-0998.12387. Epub 2015 Feb 27.
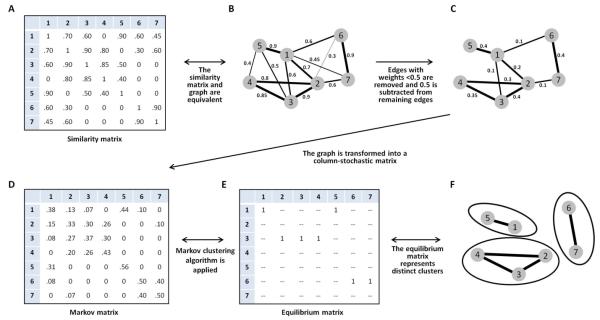
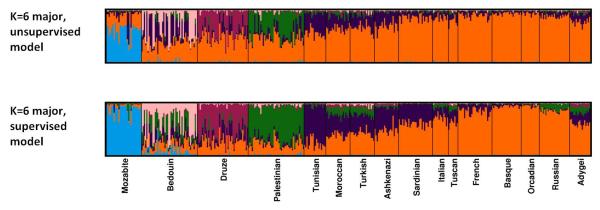
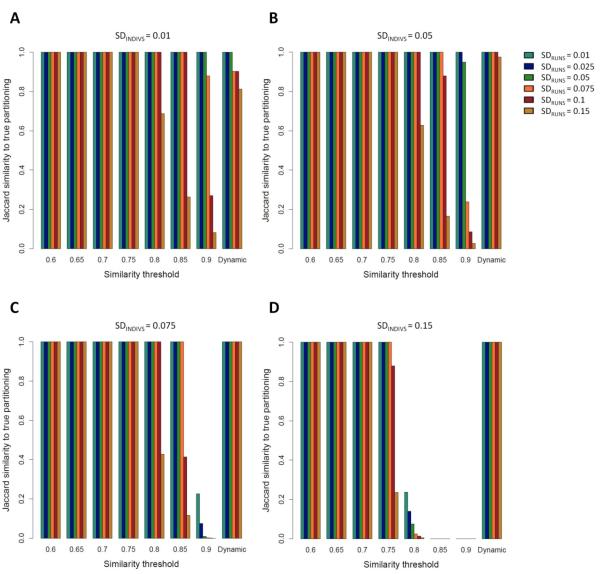
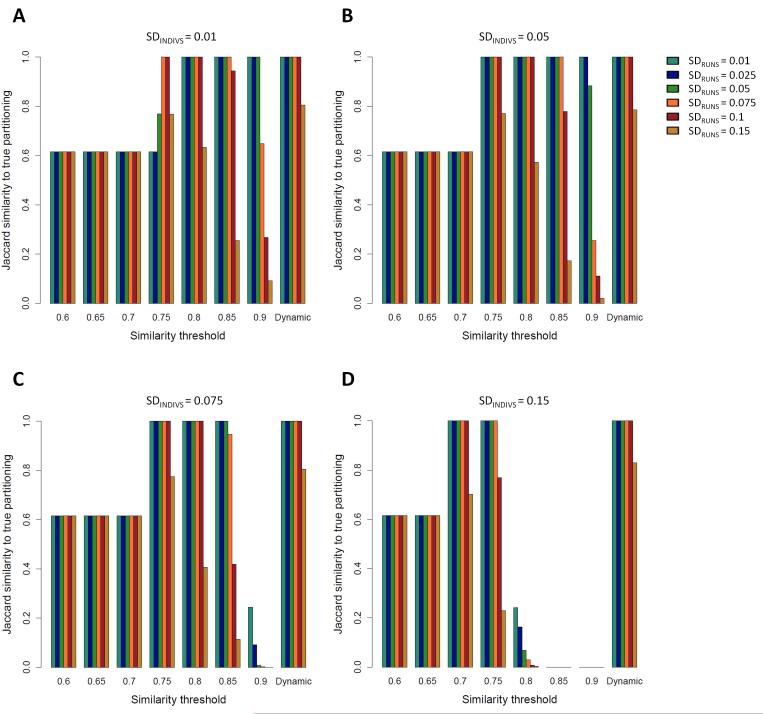
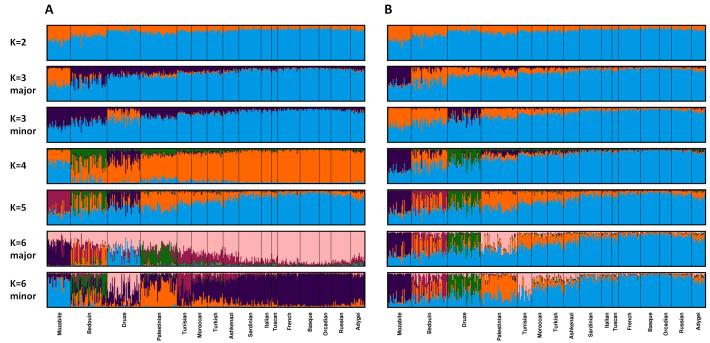
The identification of the genetic structure of populations from multilocus genotype data has become a central component of modern population-genetic data analysis. Application of model-based clustering programs often entails a number of steps, in which the user considers different modelling assumptions, compares results across different predetermined values of the number of assumed clusters (a parameter typically denoted K), examines multiple independent runs for each fixed value of K, and distinguishes among runs belonging to substantially distinct clustering solutions. Here, we present Clumpak (Cluster Markov Packager Across K), a method that automates the postprocessing of results of model-based population structure analyses. For analysing multiple independent runs at a single K value, Clumpak identifies sets of highly similar runs, separating distinct groups of runs that represent distinct modes in the space of possible solutions. This procedure, which generates a consensus solution for each distinct mode, is performed by the use of a Markov clustering algorithm that relies on a similarity matrix between replicate runs, as computed by the software Clumpp. Next, Clumpak identifies an optimal alignment of inferred clusters across different values of K, extending a similar approach implemented for a fixed K in Clumpp and simplifying the comparison of clustering results across different K values. Clumpak incorporates additional features, such as implementations of methods for choosing K and comparing solutions obtained by different programs, models, or data subsets. Clumpak, available at http://clumpak.tau.ac.il, simplifies the use of model-based analyses of population structure in population genetics and molecular ecology.
从多位点基因型数据识别群体的遗传结构已成为现代群体遗传学数据分析的核心组成部分。基于模型的聚类程序的应用通常需要多个步骤,在此过程中用户要考虑不同的建模假设,比较不同预设假定聚类数(通常用参数K表示)下的结果,检查每个固定K值的多次独立运行结果,并区分属于截然不同聚类解决方案的运行结果。在此,我们介绍Clumpak(跨K的聚类马尔可夫打包程序),这是一种可自动对基于模型的群体结构分析结果进行后处理的方法。对于在单个K值下分析多次独立运行结果,Clumpak可识别高度相似的运行结果集,分离代表可能解决方案空间中不同模式的不同运行结果组。此过程通过使用马尔可夫聚类算法为每个不同模式生成一个共识解决方案,该算法依赖于由软件Clumpp计算的重复运行之间的相似性矩阵。接下来,Clumpak可识别不同K值下推断聚类的最优比对,扩展了Clumpp中针对固定K值实施的类似方法,并简化了不同K值下聚类结果的比较。Clumpak还包含其他功能,如选择K值以及比较不同程序、模型或数据子集获得的解决方案的方法的实现。可在http://clumpak.tau.ac.il获取的Clumpak简化了群体遗传学和分子生态学中基于模型的群体结构分析的使用。