Xu Yan, Li Yeshu, Shen Zhengyang, Wu Ziwei, Gao Teng, Fan Yubo, Lai Maode, Chang Eric I-Chao
State Key Laboratory of Software Development Environment and Key Laboratory of Biomechanics and Mechanobiology of Ministry of Education and Research Institute of Beihang University in Shenzhen, Beijing, China.
Microsoft Research Asia, Beijing, China.
BMC Bioinformatics. 2017 Aug 3;18(1):360. doi: 10.1186/s12859-017-1768-8.
Histopathology images are critical for medical diagnosis, e.g., cancer and its treatment. A standard histopathology slice can be easily scanned at a high resolution of, say, 200,000×200,000 pixels. These high resolution images can make most existing imaging processing tools infeasible or less effective when operated on a single machine with limited memory, disk space and computing power.
In this paper, we propose an algorithm tackling this new emerging "big data" problem utilizing parallel computing on High-Performance-Computing (HPC) clusters. Experimental results on a large-scale data set (1318 images at a scale of 10 billion pixels each) demonstrate the efficiency and effectiveness of the proposed algorithm for low-latency real-time applications.
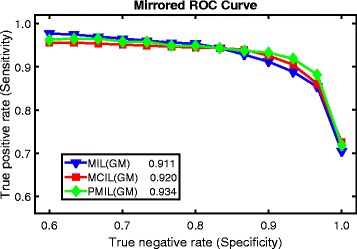
The framework proposed an effective and efficient system for extremely large histopathology image analysis. It is based on the multiple instance learning formulation for weakly-supervised learning for image classification, segmentation and clustering. When a max-margin concept is adopted for different clusters, we obtain further improvement in clustering performance.
组织病理学图像对于医学诊断至关重要,例如癌症及其治疗。一张标准的组织病理学切片可以轻松地以高分辨率进行扫描,比如说200,000×200,000像素。当在一台内存、磁盘空间和计算能力有限的单机上运行时,这些高分辨率图像会使大多数现有的图像处理工具变得不可行或效率降低。
在本文中,我们提出了一种算法,利用高性能计算(HPC)集群上的并行计算来解决这个新出现的“大数据”问题。在一个大规模数据集(1318张图像,每张图像规模达100亿像素)上的实验结果证明了所提算法在低延迟实时应用中的效率和有效性。
所提出的框架为超大型组织病理学图像分析提供了一个高效且有效的系统。它基于多实例学习公式,用于图像分类、分割和聚类的弱监督学习。当对不同簇采用最大间隔概念时,我们在聚类性能上获得了进一步提升。