Alberta Research Centre for Health Evidence, Department of Pediatrics, University of Alberta, 11405-87 Avenue NW, Edmonton, Alberta, T6G 1C9, Canada.
Syst Rev. 2018 Mar 12;7(1):45. doi: 10.1186/s13643-018-0707-8.
Machine learning tools can expedite systematic review (SR) processes by semi-automating citation screening. Abstrackr semi-automates citation screening by predicting relevant records. We evaluated its performance for four screening projects.
We used a convenience sample of screening projects completed at the Alberta Research Centre for Health Evidence, Edmonton, Canada: three SRs and one descriptive analysis for which we had used SR screening methods. The projects were heterogeneous with respect to search yield (median 9328; range 5243 to 47,385 records; interquartile range (IQR) 15,688 records), topic (Antipsychotics, Bronchiolitis, Diabetes, Child Health SRs), and screening complexity. We uploaded the records to Abstrackr and screened until it made predictions about the relevance of the remaining records. Across three trials for each project, we compared the predictions to human reviewer decisions and calculated the sensitivity, specificity, precision, false negative rate, proportion missed, and workload savings.
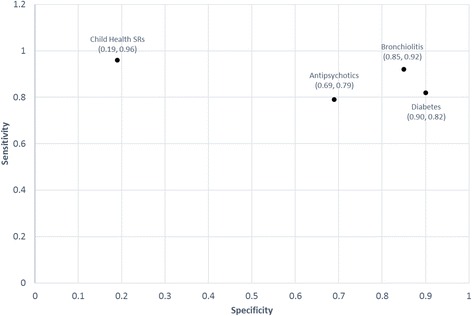
Abstrackr's sensitivity was > 0.75 for all projects and the mean specificity ranged from 0.69 to 0.90 with the exception of Child Health SRs, for which it was 0.19. The precision (proportion of records correctly predicted as relevant) varied by screening task (median 26.6%; range 14.8 to 64.7%; IQR 29.7%). The median false negative rate (proportion of records incorrectly predicted as irrelevant) was 12.6% (range 3.5 to 21.2%; IQR 12.3%). The workload savings were often large (median 67.2%, range 9.5 to 88.4%; IQR 23.9%). The proportion missed (proportion of records predicted as irrelevant that were included in the final report, out of the total number predicted as irrelevant) was 0.1% for all SRs and 6.4% for the descriptive analysis. This equated to 4.2% (range 0 to 12.2%; IQR 7.8%) of the records in the final reports.
Abstrackr's reliability and the workload savings varied by screening task. Workload savings came at the expense of potentially missing relevant records. How this might affect the results and conclusions of SRs needs to be evaluated. Studies evaluating Abstrackr as the second reviewer in a pair would be of interest to determine if concerns for reliability would diminish. Further evaluations of Abstrackr's performance and usability will inform its refinement and practical utility.
机器学习工具可以通过半自动引用筛选来加速系统评价 (SR) 流程。Abstrackr 通过预测相关记录来半自动筛选引用。我们评估了它在四个筛选项目中的性能。
我们使用了加拿大埃德蒙顿艾伯塔省健康证据研究中心完成的筛选项目的便利样本:三个 SR 和一个描述性分析,我们使用了 SR 筛选方法。这些项目在搜索结果(中位数 9328;范围 5243 至 47385 条记录;四分位距 (IQR) 15688 条记录)、主题(抗精神病药、细支气管炎、糖尿病、儿童健康 SR)和筛选复杂性方面存在异质性。我们将记录上传到 Abstrackr 并进行筛选,直到它对剩余记录的相关性做出预测。在每个项目的三个试验中,我们将预测与人类审查员的决策进行比较,并计算敏感性、特异性、精度、假阴性率、遗漏率和工作量节省。
Abstrackr 的敏感性对于所有项目均>0.75,平均特异性范围为 0.69 至 0.90,儿童健康 SR 除外,其特异性为 0.19。精度(正确预测为相关的记录比例)因筛选任务而异(中位数 26.6%;范围 14.8 至 64.7%;IQR 29.7%)。假阴性率(错误预测为不相关的记录比例)中位数为 12.6%(范围 3.5 至 21.2%;IQR 12.3%)。工作量节省通常很大(中位数 67.2%;范围 9.5 至 88.4%;IQR 23.9%)。遗漏率(预测为不相关但包含在最终报告中的记录比例,占预测为不相关的总记录数)对于所有 SR 为 0.1%,对于描述性分析为 6.4%。这相当于最终报告中记录的 4.2%(范围 0 至 12.2%;IQR 7.8%)。
Abstrackr 的可靠性和工作量节省因筛选任务而异。工作量节省是以潜在遗漏相关记录为代价的。这可能会如何影响 SR 的结果和结论需要进行评估。评估 Abstrackr 作为双人审查员中的第二位的研究将有助于确定对可靠性的担忧是否会减少。对 Abstrackr 性能和可用性的进一步评估将为其改进和实际应用提供信息。