Department of Statistics, Rajshahi University, Rajshahi, Bangladesh.
Bioinformatics Lab, Department of Statistics, Bangabandhu Sheikh Mujibur Rahman Science and Technology University, Gopalganj, Bangladesh.
BMC Bioinformatics. 2018 Apr 11;19(1):128. doi: 10.1186/s12859-018-2117-2.
The identification of differential metabolites in metabolomics is still a big challenge and plays a prominent role in metabolomics data analyses. Metabolomics datasets often contain outliers because of analytical, experimental, and biological ambiguity, but the currently available differential metabolite identification techniques are sensitive to outliers.
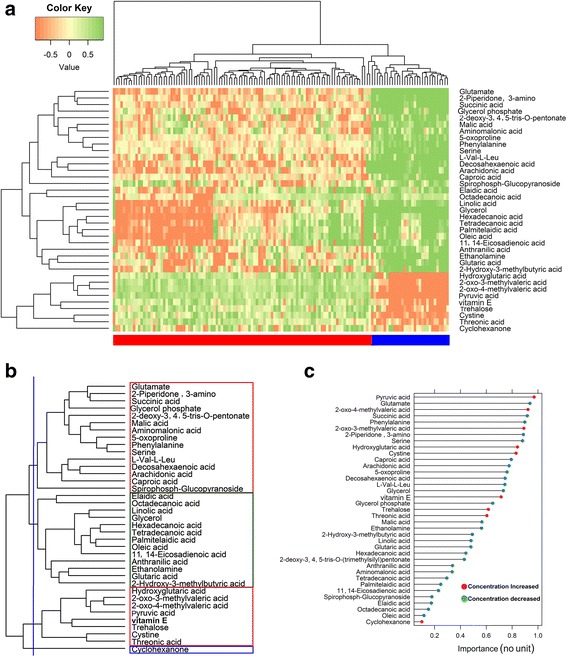
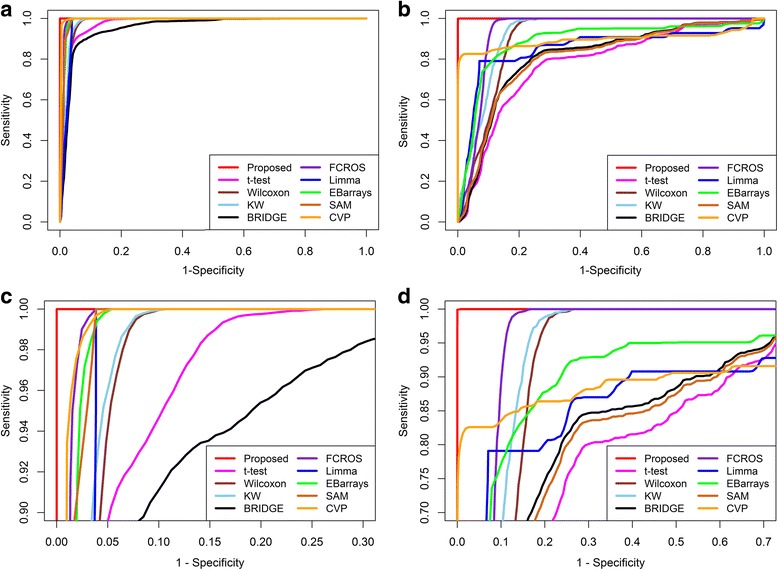
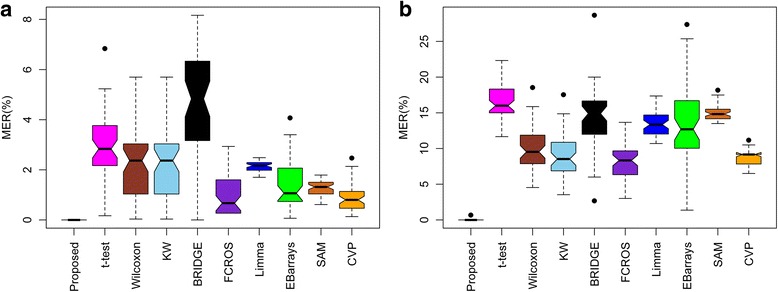
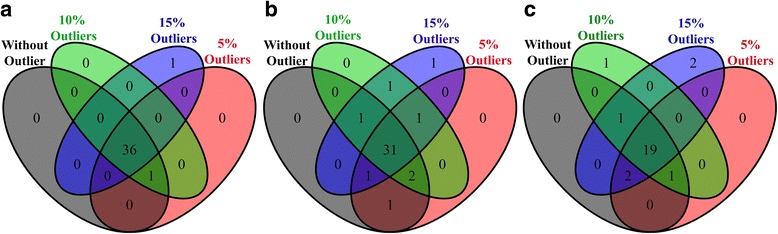
We propose a kernel weight based outlier-robust volcano plot for identifying differential metabolites from noisy metabolomics datasets. Two numerical experiments are used to evaluate the performance of the proposed technique against nine existing techniques, including the t-test and the Kruskal-Wallis test. Artificially generated data with outliers reveal that the proposed method results in a lower misclassification error rate and a greater area under the receiver operating characteristic curve compared with existing methods. An experimentally measured breast cancer dataset to which outliers were artificially added reveals that our proposed method produces only two non-overlapping differential metabolites whereas the other nine methods produced between seven and 57 non-overlapping differential metabolites.
Our data analyses show that the performance of the proposed differential metabolite identification technique is better than that of existing methods. Thus, the proposed method can contribute to analysis of metabolomics data with outliers. The R package and user manual of the proposed method are available at https://github.com/nishithkumarpaul/Rvolcano .
代谢组学中差异代谢物的鉴定仍然是一个巨大的挑战,在代谢组学数据分析中起着突出的作用。由于分析、实验和生物上的不确定性,代谢组学数据集通常包含离群值,但目前可用的差异代谢物识别技术对离群值很敏感。
我们提出了一种基于核权重的稳健火山图,用于从嘈杂的代谢组学数据集中识别差异代谢物。我们使用了两个数值实验来评估该技术与九种现有技术(包括 t 检验和 Kruskal-Wallis 检验)的性能。带有离群值的人为生成的数据表明,与现有方法相比,该方法的错误分类率更低,接收者操作特征曲线下的面积更大。对添加了人为离群值的实验测量的乳腺癌数据集进行的分析表明,我们提出的方法仅产生了两个非重叠的差异代谢物,而其他九种方法产生了 7 到 57 个非重叠的差异代谢物。
我们的数据分析表明,所提出的差异代谢物识别技术的性能优于现有方法。因此,该方法可以有助于分析存在离群值的代谢组学数据。该方法的 R 包和用户手册可在 https://github.com/nishithkumarpaul/Rvolcano 上获得。