Department of Physiology, Ajou University School of Medicine, Suwon, South Korea.
Department of Biological Sciences, Louisiana State University, Baton Rouge, LA, United States.
Front Immunol. 2018 Jul 27;9:1695. doi: 10.3389/fimmu.2018.01695. eCollection 2018.
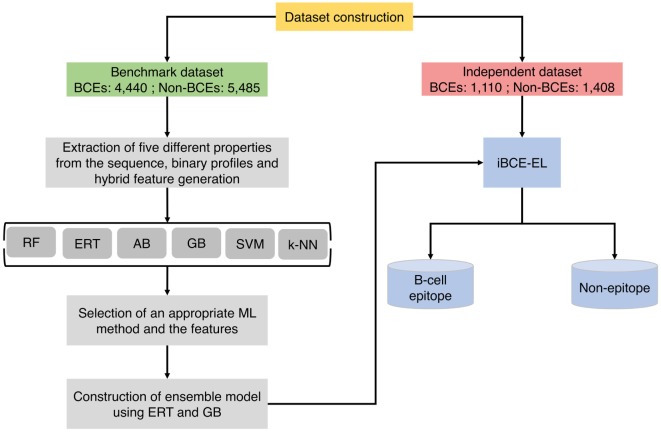
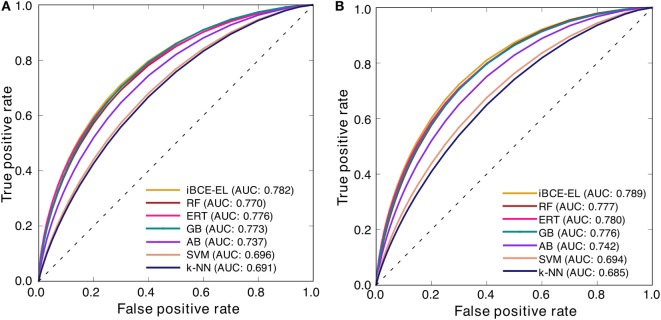
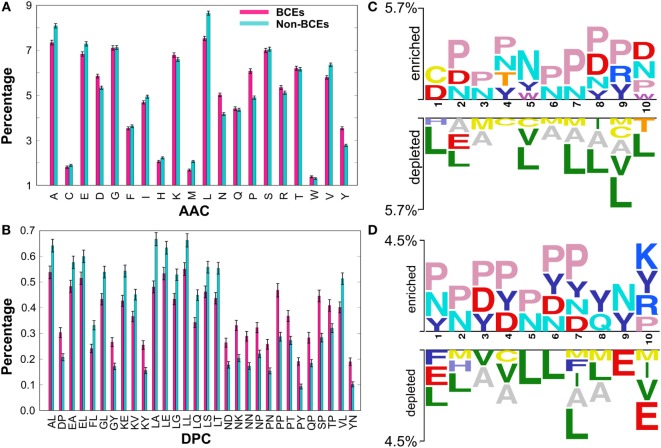
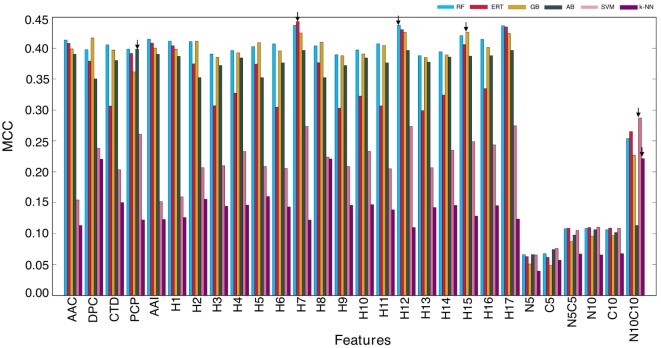
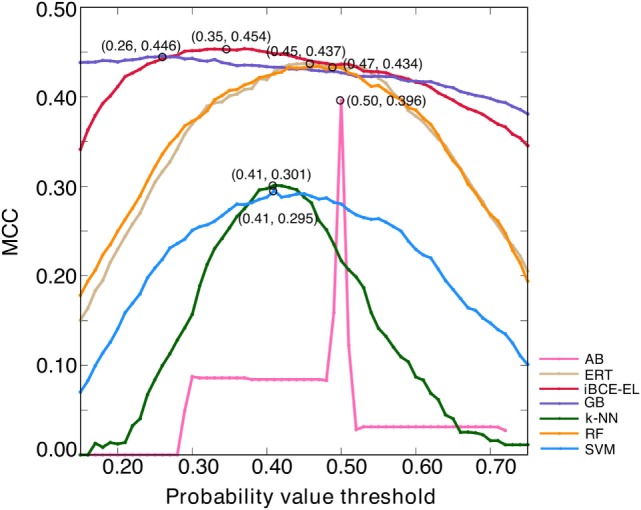
Identification of B-cell epitopes (BCEs) is a fundamental step for epitope-based vaccine development, antibody production, and disease prevention and diagnosis. Due to the avalanche of protein sequence data discovered in postgenomic age, it is essential to develop an automated computational method to enable fast and accurate identification of novel BCEs within vast number of candidate proteins and peptides. Although several computational methods have been developed, their accuracy is unreliable. Thus, developing a reliable model with significant prediction improvements is highly desirable. In this study, we first constructed a non-redundant data set of 5,550 experimentally validated BCEs and 6,893 non-BCEs from the Immune Epitope Database. We then developed a novel ensemble learning framework for improved linear BCE predictor called iBCE-EL, a fusion of two independent predictors, namely, extremely randomized tree (ERT) and gradient boosting (GB) classifiers, which, respectively, uses a combination of physicochemical properties (PCP) and amino acid composition and a combination of dipeptide and PCP as input features. Cross-validation analysis on a benchmarking data set showed that iBCE-EL performed better than individual classifiers (ERT and GB), with a Matthews correlation coefficient (MCC) of 0.454. Furthermore, we evaluated the performance of iBCE-EL on the independent data set. Results show that iBCE-EL significantly outperformed the state-of-the-art method with an MCC of 0.463. To the best of our knowledge, iBCE-EL is the first ensemble method for linear BCEs prediction. iBCE-EL was implemented in a web-based platform, which is available at http://thegleelab.org/iBCE-EL. iBCE-EL contains two prediction modes. The first one identifying peptide sequences as BCEs or non-BCEs, while later one is aimed at providing users with the option of mining potential BCEs from protein sequences.
B 细胞表位 (BCE) 的鉴定是基于表位疫苗开发、抗体生产以及疾病预防和诊断的基础步骤。由于在后基因组时代发现了大量的蛋白质序列数据,因此开发一种自动化的计算方法来快速、准确地识别大量候选蛋白质和肽中的新型 BCE 至关重要。尽管已经开发了几种计算方法,但它们的准确性不可靠。因此,开发一个具有显著预测改进的可靠模型是非常需要的。在这项研究中,我们首先构建了一个非冗余数据集,其中包含 5550 个经实验验证的 BCE 和 6893 个非 BCE,这些数据来自免疫表位数据库。然后,我们开发了一种新的集成学习框架,用于提高线性 BCE 预测器,称为 iBCE-EL,它融合了两个独立的预测器,即极端随机树 (ERT) 和梯度提升 (GB) 分类器,它们分别使用物理化学性质 (PCP) 和氨基酸组成的组合以及二肽和 PCP 的组合作为输入特征。在基准数据集上的交叉验证分析表明,iBCE-EL 的性能优于单个分类器 (ERT 和 GB),马修斯相关系数 (MCC) 为 0.454。此外,我们在独立数据集上评估了 iBCE-EL 的性能。结果表明,iBCE-EL 以 MCC 为 0.463 的优势显著优于最先进的方法。据我们所知,iBCE-EL 是第一个用于线性 BCE 预测的集成方法。iBCE-EL 已在基于网络的平台上实现,可在 http://thegleelab.org/iBCE-EL 上获得。iBCE-EL 包含两种预测模式。第一种是识别肽序列是 BCE 还是非 BCE,而第二种是为用户提供从蛋白质序列中挖掘潜在 BCE 的选项。