Advanced Analytics Institute, Faculty of Engineering and Information Technology, University of Technology Sydney, 15 Broadway Ultimo, Sydney, 2007, Australia.
Discipline of Business Analytics, The University of Sydney, Darlington, Sydney, 2006, Australia.
BMC Bioinformatics. 2018 Dec 31;19(Suppl 19):517. doi: 10.1186/s12859-018-2520-8.
Early and accurate identification of potential adverse drug reactions (ADRs) for combined medication is vital for public health. Existing methods either rely on expensive wet-lab experiments or detecting existing associations from related records. Thus, they inevitably suffer under-reporting, delays in reporting, and inability to detect ADRs for new and rare drugs. The current application of machine learning methods is severely impeded by the lack of proper drug representation and credible negative samples. Therefore, a method to represent drugs properly and to select credible negative samples becomes vital in applying machine learning methods to this problem.
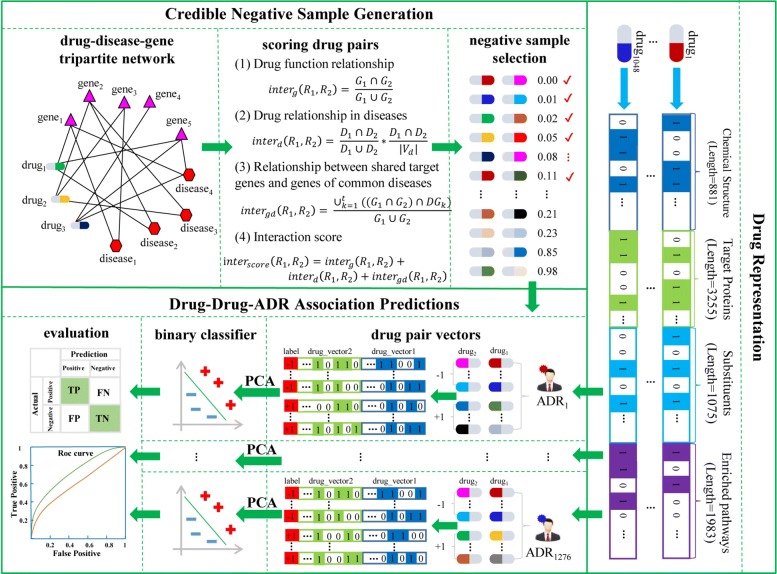
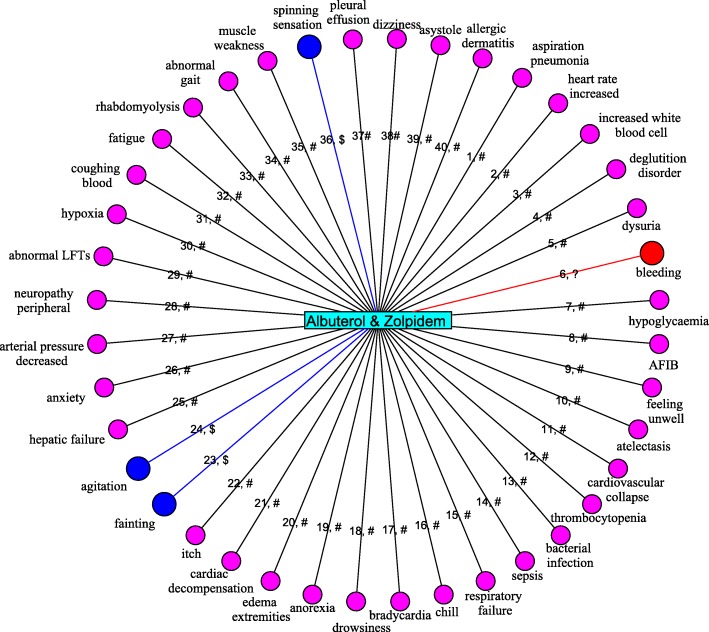
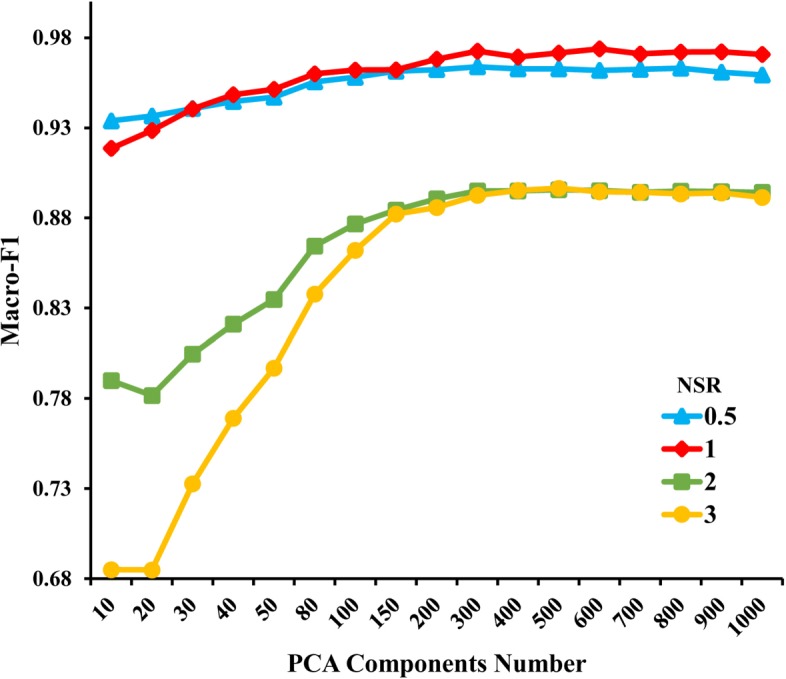
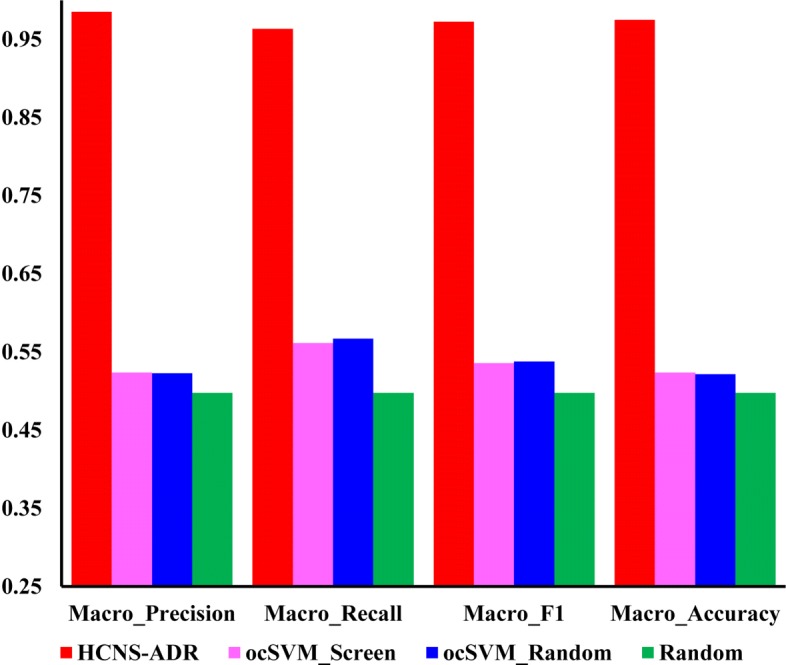
In this work, we propose a machine learning method to predict ADRs of combined medication from pharmacologic databases by building up highly-credible negative samples (HCNS-ADR). Specifically, we fuse heterogeneous information from different databases and represent each drug as a multi-dimensional vector according to its chemical substructures, target proteins, substituents, and related pathways first. Then, a drug-pair vector is obtained by appending the vector of one drug to the other. Next, we construct a drug-disease-gene network and devise a scoring method to measure the interaction probability of every drug pair via network analysis. Drug pairs with lower interaction probability are preferentially selected as negative samples. Following that, the validated positive samples and the selected credible negative samples are projected into a lower-dimensional space using the principal component analysis. Finally, a classifier is built for each ADR using its positive and negative samples with reduced dimensions. The performance of the proposed method is evaluated on simulative prediction for 1276 ADRs and 1048 drugs, comparing using four machine learning algorithms and with two baseline approaches. Extensive experiments show that the proposed way to represent drugs characterizes drugs accurately. With highly-credible negative samples selected by HCNS-ADR, the four machine learning algorithms achieve significant performance improvements. HCNS-ADR is also shown to be able to predict both known and novel drug-drug-ADR associations, outperforming two other baseline approaches significantly.
The results demonstrate that integration of different drug properties to represent drugs are valuable for ADR prediction of combined medication and the selection of highly-credible negative samples can significantly improve the prediction performance.
早期准确识别联合用药的潜在药物不良反应(ADR)对公共健康至关重要。现有的方法要么依赖昂贵的湿实验室实验,要么从相关记录中检测现有关联。因此,它们不可避免地存在报告不足、报告延迟以及无法检测新的和罕见药物的 ADR 的问题。由于缺乏适当的药物表示和可靠的负样本,当前机器学习方法的应用受到严重阻碍。因此,在将机器学习方法应用于该问题时,一种适当表示药物和选择可靠负样本的方法变得至关重要。
在这项工作中,我们提出了一种通过构建高度可信的负样本(HCNS-ADR)从药理学数据库中预测联合用药 ADR 的机器学习方法。具体来说,我们首先融合来自不同数据库的异质信息,并根据药物的化学结构、靶蛋白、取代基和相关途径将每种药物表示为多维向量。然后,通过将一种药物的向量附加到另一种药物的向量上来获得药物对向量。接下来,我们构建了一个药物-疾病-基因网络,并设计了一种评分方法通过网络分析来测量每对药物的相互作用概率。相互作用概率较低的药物对被优先选为负样本。之后,使用主成分分析将验证的阳性样本和选择的可信负样本投影到低维空间中。最后,使用降维后的阳性和阴性样本为每个 ADR 构建一个分类器。使用四种机器学习算法和两种基线方法对 1276 种 ADR 和 1048 种药物进行模拟预测,评估了所提出方法的性能。
实验结果表明,通过整合不同的药物特性来表示药物,对联合用药的 ADR 预测具有重要价值,而选择高度可信的负样本可以显著提高预测性能。