Shanghai American School Pudong, 1600 Ling Bai Rd, Pudong District, Shanghai, 201201, China.
Int J Infect Dis. 2020 Jul;96:582-589. doi: 10.1016/j.ijid.2020.04.085. Epub 2020 May 4.
As the coronavirus disease 2019 (COVID-19) pandemic continues to proliferate globally, this paper shares the findings of modelling the outbreak in China at both provincial and national levels. This paper examines the applicability of the logistic growth model, with implications for the study of the COVID-19 pandemic and other infectious diseases.
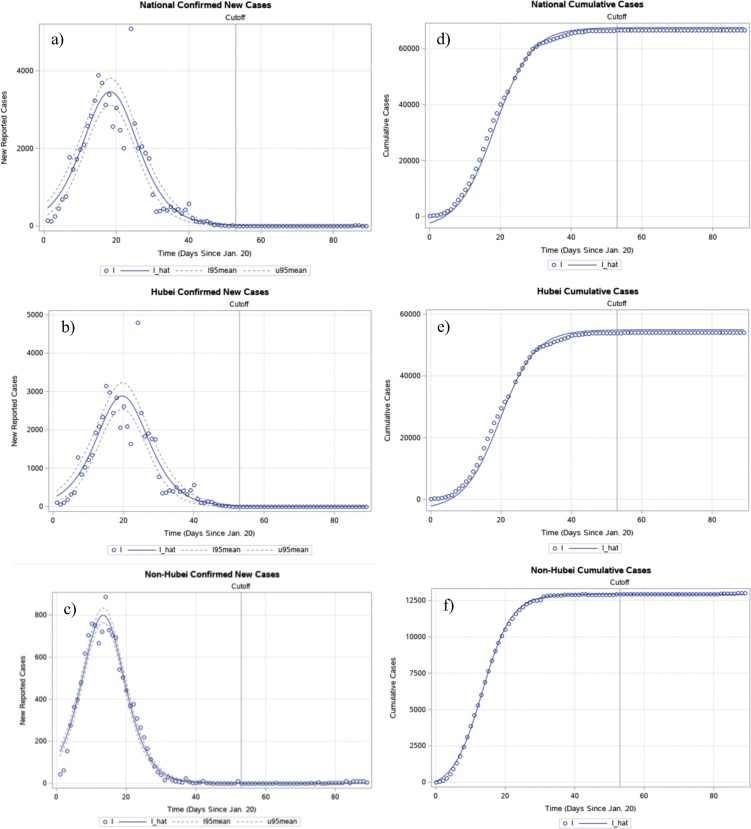
An NLS (Non-Linear Least Squares) method was employed to estimate the parameters of a differentiated logistic growth function using new daily COVID-19 cases in multiple regions in China and in other selected countries. The estimation was based upon training data from January 20, 2020 to March 13, 2020. A restriction test was subsequently implemented to examine whether a designated parameter was identical among regions or countries, and the diagnosis of residuals was also conducted. The model's goodness of fit was checked using testing data from March 14, 2020 to April 18, 2020.
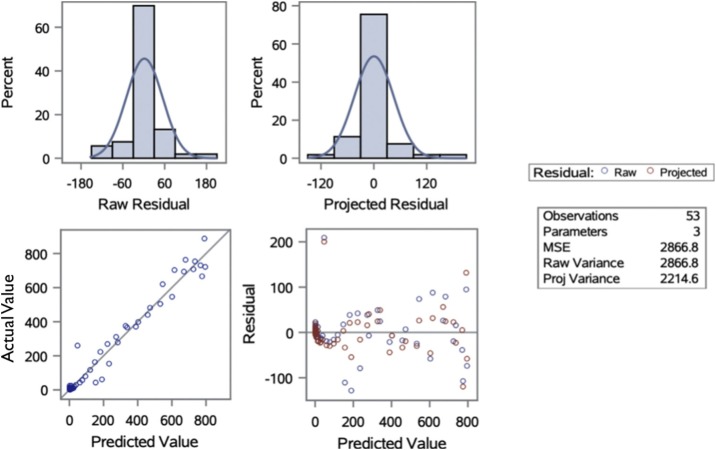
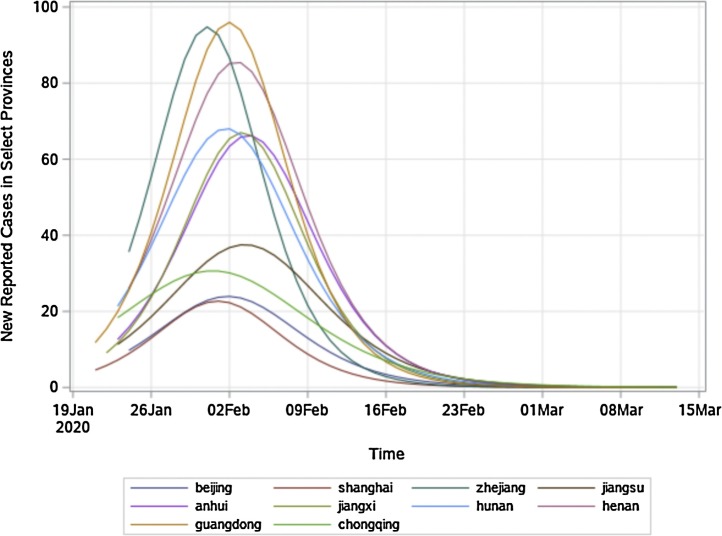
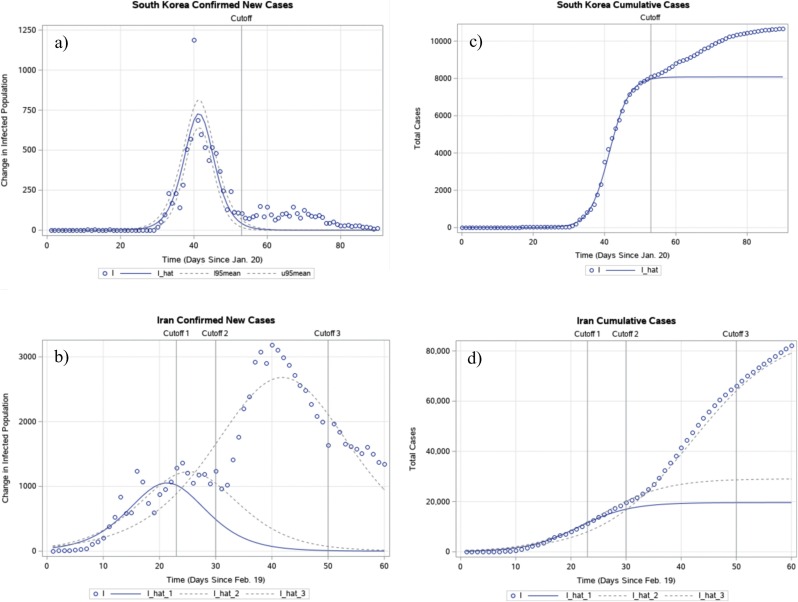
The model presented in this paper fitted time-series data exceedingly well for the whole of China, its eleven selected provinces and municipalities, and two other countries - South Korea and Iran - and provided estimates of key parameters. This study rejected the null hypothesis that the growth rates of outbreaks were the same among ten selected non-Hubei provinces in China, as well as between South Korea and Iran. The study found that the model did not provide reliable estimates for countries that were in the early stages of outbreaks. Furthermore, this study concured that the R values might vary and mislead when compared between different portions of the same non-linear curve. In addition, the study identified the existence of heteroskedasticity and positive serial correlation within residuals in some provinces and countries.
The findings suggest that there is potential for this model to contribute to better public health policy in combatting COVID-19. The model does so by providing a simple logistic framework for retrospectively analyzing outbreaks in regions that have already experienced a maximal proliferation in cases. Based upon statistical findings, this study also outlines certain challenges in modelling and their implications for the results.
随着 2019 年冠状病毒病(COVID-19)在全球范围内持续蔓延,本文分享了对中国省级和国家级疫情建模的结果。本文检验了逻辑斯蒂增长模型的适用性,这对 COVID-19 大流行和其他传染病的研究具有重要意义。
采用非线性最小二乘法(NLS)方法,利用中国多个地区和其他选定国家的新的每日 COVID-19 病例数据,对差异化逻辑斯蒂增长函数的参数进行估计。估计是基于 2020 年 1 月 20 日至 3 月 13 日的训练数据进行的。随后进行了限制检验,以检验指定参数在地区或国家之间是否相同,并对残差进行了诊断。使用 2020 年 3 月 14 日至 4 月 18 日的测试数据检查模型的拟合优度。
本文提出的模型非常适合中国、11 个选定的省、直辖市以及韩国和伊朗这两个其他国家的时间序列数据,提供了关键参数的估计值。该研究拒绝了中国十个非湖北省份、韩国和伊朗之间爆发增长率相同的零假设。研究发现,对于处于疫情早期阶段的国家,该模型无法提供可靠的估计。此外,本研究还认为,当比较同一非线性曲线上的不同部分时,R 值可能会有所不同,并产生误导。此外,研究还发现,一些省份和国家的残差中存在异方差和正序列相关性。
研究结果表明,该模型有可能为应对 COVID-19 提供更好的公共卫生政策。该模型通过为已经经历过病例最大扩散的地区提供一个简单的逻辑斯蒂框架来实现这一目标。基于统计发现,本研究还概述了建模中存在的某些挑战及其对结果的影响。