NHLBI Integrated Cardiovascular Data Science Training Program at University of California (UCLA), Los Angeles, USA; Departments of Physiology and Medicine (Cardiology) at UCLA School of Medicine, USA; Institute of Informatics, Faculty of Mathematics, Informatics and Mechanics University of Warsaw, Warsaw, Poland.
NHLBI Integrated Cardiovascular Data Science Training Program at University of California (UCLA), Los Angeles, USA; Departments of Physiology and Medicine (Cardiology) at UCLA School of Medicine, USA; Bioinformatics and Medical Informatics at UCLA School of Engineering, Los Angeles, CA 90095, USA; Scalable Analytics Institute (ScAi) at UCLA School of Engineering, Los Angeles, CA 90095, USA.
J Mol Cell Cardiol. 2020 Aug;145:54-58. doi: 10.1016/j.yjmcc.2020.05.020. Epub 2020 Jun 3.
During cardiovascular disease progression, molecular systems of myocardium (e.g., a proteome) undergo diverse and distinct changes. Dynamic, temporally-regulated alterations of individual molecules underlie the collective response of the heart to pathological drivers and the ultimate development of pathogenesis. Advances in high-throughput omics technologies have enabled cost-effective, temporal profiling of targeted systems in animal models of human diseases. However, computational analysis of temporal patterns from omics data remains challenging. In particular, bioinformatic pipelines involving unsupervised statistical approaches to support cardiovascular investigations are lacking, which hinders one's ability to extract biomedical insights from these complex datasets.
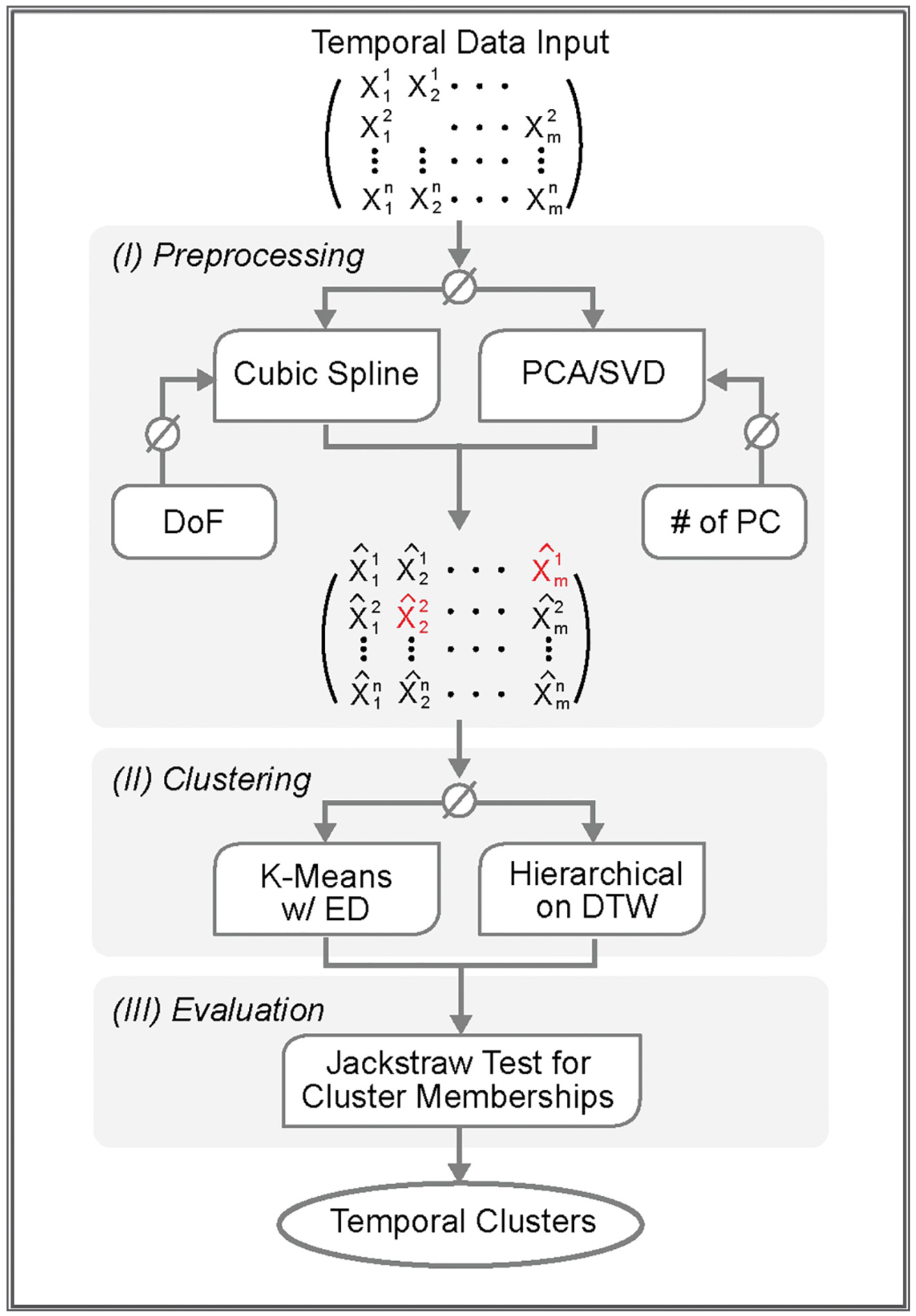
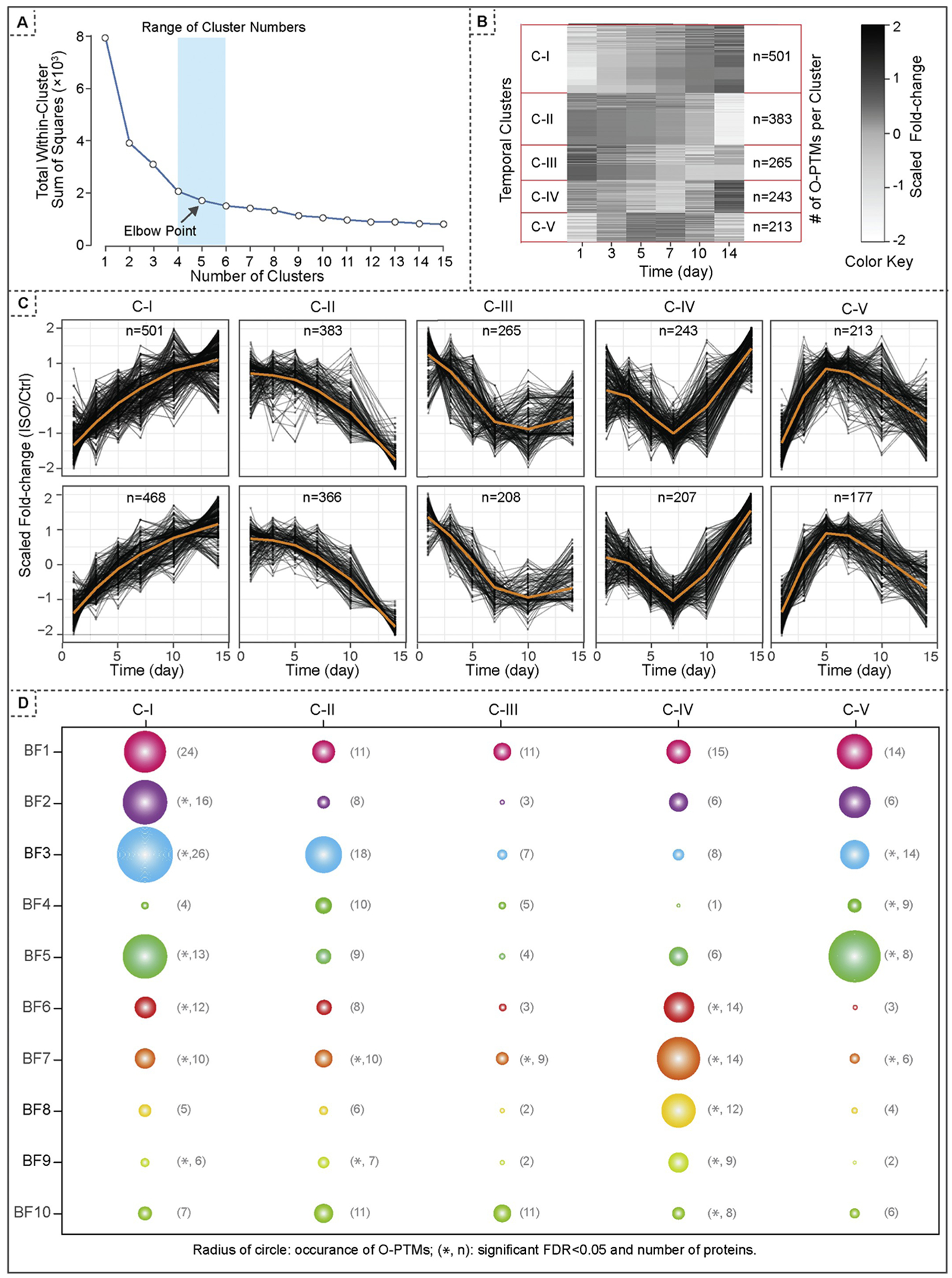
We developed a non-parametric data analysis platform to resolve computational challenges unique to temporal omics datasets. Our platform consists of three modules. Module I preprocesses the temporal data using either cubic splines or principal component analysis (PCA), and it simultaneously accomplishes the tasks on missing data imputation and denoising. Module II performs an unsupervised classification by K-means or hierarchical clustering. Module III evaluates and identifies biological entities (e.g., molecular events) that exhibit strong associations to specific temporal patterns. The jackstraw method for cluster membership has been applied to estimate p-values and posterior inclusion probabilities (PIPs), both of which guided feature selection. To demonstrate the utility of the analysis platform, we employed a temporal proteomics dataset that captured the proteome-wide dynamics of oxidative stress induced post-translational modifications (O-PTMs) in mouse hearts undergoing isoproterenol (ISO)-induced hypertrophy.
We have created a platform, CV.Signature.TCP, to identify distinct temporal clusters in omics datasets. We presented a cardiovascular use case to demonstrate its utility in unveiling biological insights underlying O-PTM regulations in cardiac remodeling. This platform is implemented in an open source R package (https://github.com/UCLA-BD2K/CV.Signature.TCP).
在心血管疾病进展过程中,心肌的分子系统(例如蛋白质组)会发生多种不同的变化。个体分子的动态、时变调节变化是心脏对病理驱动因素的集体反应和发病机制最终发展的基础。高通量组学技术的进步使得在人类疾病的动物模型中对靶向系统进行具有成本效益的、时变的分析成为可能。然而,组学数据的时间模式的计算分析仍然具有挑战性。特别是,缺乏涉及无监督统计方法的生物信息学管道来支持心血管研究,这阻碍了人们从这些复杂数据集提取生物医学见解的能力。
我们开发了一种非参数数据分析平台,以解决时间组学数据集特有的计算挑战。我们的平台由三个模块组成。模块 I 使用三次样条或主成分分析 (PCA) 对时间数据进行预处理,同时完成缺失数据插补和去噪任务。模块 II 通过 K-均值或层次聚类进行无监督分类。模块 III 评估并识别与特定时间模式具有强关联的生物实体(例如分子事件)。已应用 jackstraw 方法来估计聚类成员的 p 值和后验包含概率 (PIP),这两者都指导了特征选择。为了演示分析平台的实用性,我们使用了一个时间蛋白质组学数据集,该数据集捕获了在异丙肾上腺素 (ISO) 诱导的肥大过程中,小鼠心脏中氧化应激诱导的翻译后修饰 (O-PTM) 的蛋白质组全动态变化。
我们创建了一个平台 CV.Signature.TCP,用于识别组学数据集中的不同时间聚类。我们提出了一个心血管用例,以证明其在揭示心脏重构中 O-PTM 调节的生物学见解方面的实用性。该平台在一个开源 R 包(https://github.com/UCLA-BD2K/CV.Signature.TCP)中实现。