Shahhosseini Mohsen, Hu Guiping, Archontoulis Sotirios V
Department of Industrial and Manufacturing Systems Engineering, Iowa State University, Ames, IA, United States.
Department of Agronomy, Iowa State University, Ames, IA, United States.
Front Plant Sci. 2020 Jul 31;11:1120. doi: 10.3389/fpls.2020.01120. eCollection 2020.
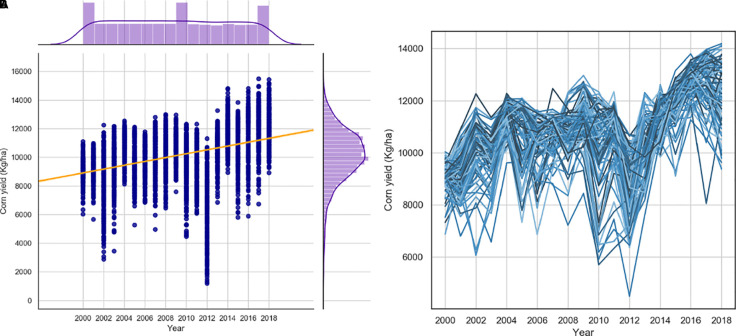
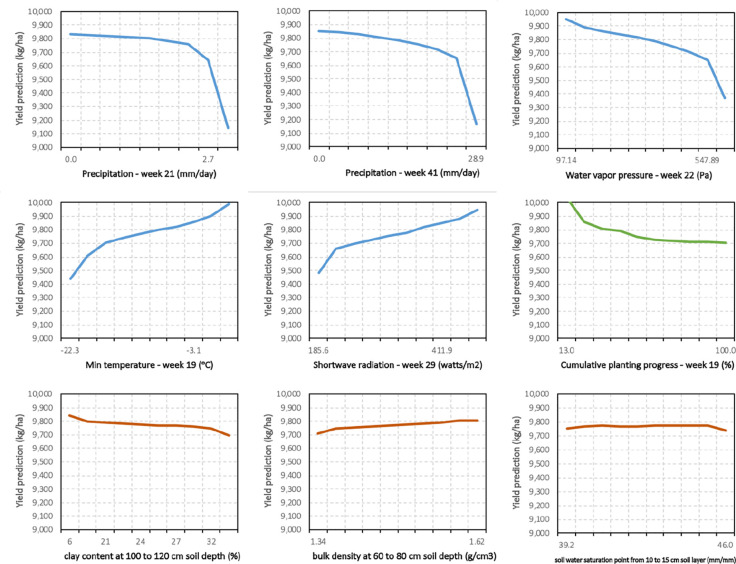
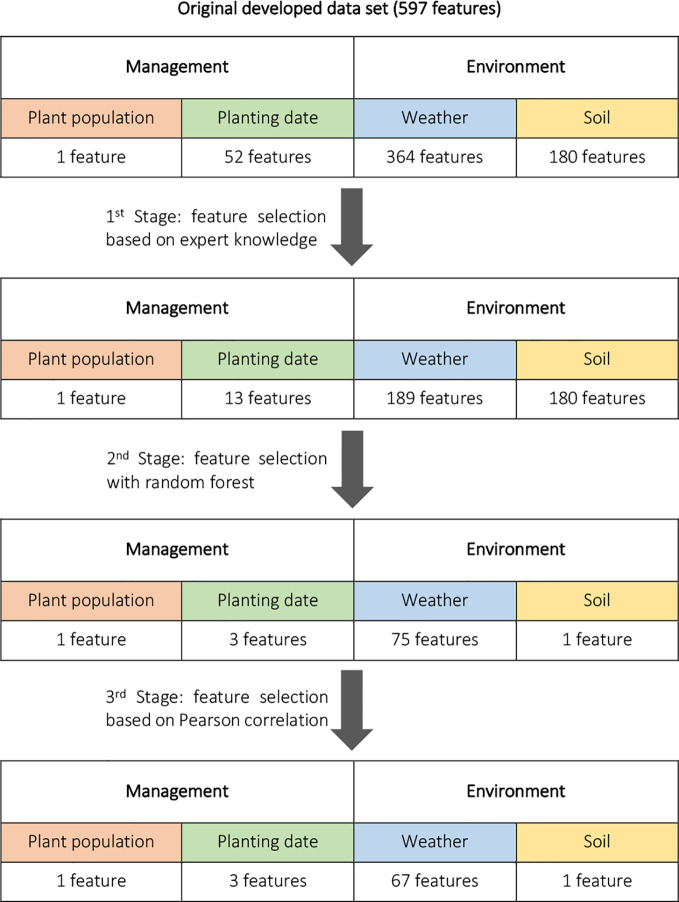
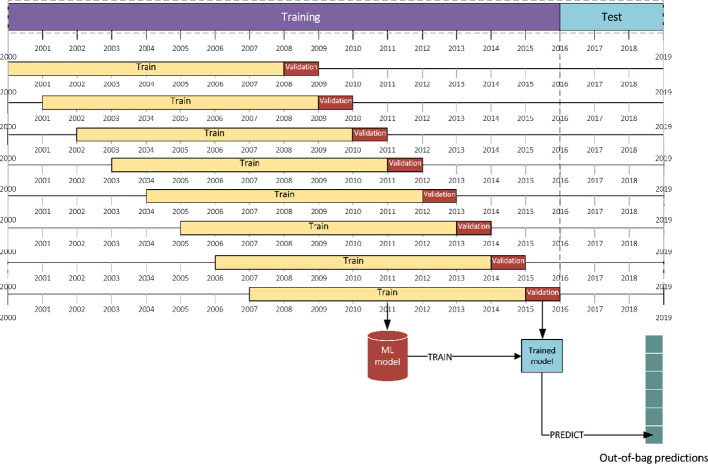
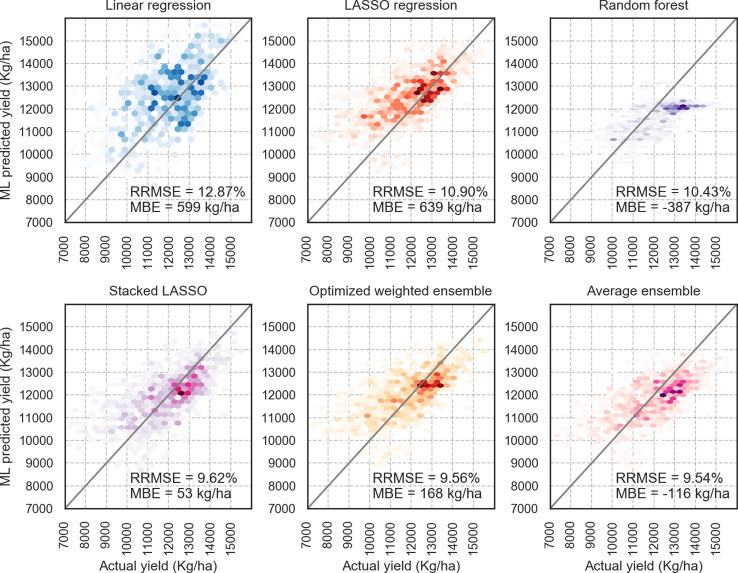
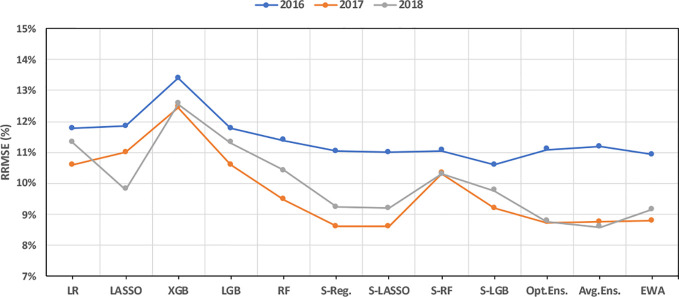
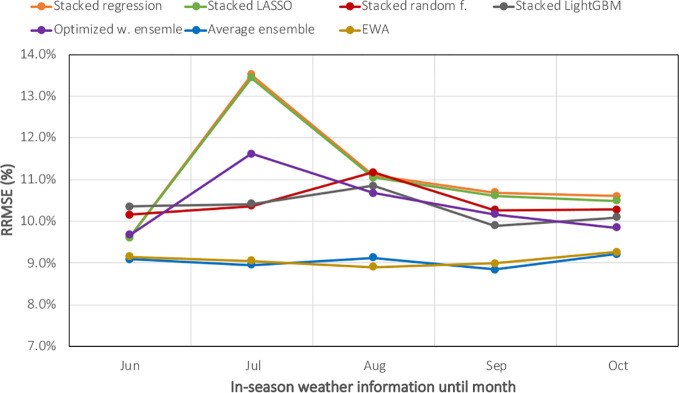
The emergence of new technologies to synthesize and analyze big data with high-performance computing has increased our capacity to more accurately predict crop yields. Recent research has shown that machine learning (ML) can provide reasonable predictions faster and with higher flexibility compared to simulation crop modeling. However, a single machine learning model can be outperformed by a "committee" of models (machine learning ensembles) that can reduce prediction bias, variance, or both and is able to better capture the underlying distribution of the data. Yet, there are many aspects to be investigated with regard to prediction accuracy, time of the prediction, and scale. The earlier the prediction during the growing season the better, but this has not been thoroughly investigated as previous studies considered all data available to predict yields. This paper provides a machine leaning based framework to forecast corn yields in three US Corn Belt states (Illinois, Indiana, and Iowa) considering complete and partial in-season weather knowledge. Several ensemble models are designed using blocked sequential procedure to generate out-of-bag predictions. The forecasts are made in county-level scale and aggregated for agricultural district and state level scales. Results show that the proposed optimized weighted ensemble and the average ensemble are the most precise models with RRMSE of 9.5%. Stacked LASSO makes the least biased predictions (MBE of 53 kg/ha), while other ensemble models also outperformed the base learners in terms of bias. On the contrary, although random k-fold cross-validation is replaced by blocked sequential procedure, it is shown that stacked ensembles perform not as good as weighted ensemble models for time series data sets as they require the data to be non-IID to perform favorably. Comparing our proposed model forecasts with the literature demonstrates the acceptable performance of forecasts made by our proposed ensemble model. Results from the scenario of having partial in-season weather knowledge reveals that decent yield forecasts with RRMSE of 9.2% can be made as early as June 1. Moreover, it was shown that the proposed model performed better than individual models and benchmark ensembles at agricultural district and state-level scales as well as county-level scale. To find the marginal effect of each input feature on the forecasts made by the proposed ensemble model, a methodology is suggested that is the basis for finding feature importance for the ensemble model. The findings suggest that weather features corresponding to weather in weeks 18-24 (May 1 to June 1) are the most important input features.
利用高性能计算来合成和分析大数据的新技术的出现,提高了我们更准确预测作物产量的能力。最近的研究表明,与模拟作物建模相比,机器学习(ML)能够更快且更灵活地提供合理预测。然而,单个机器学习模型可能会被一个“模型委员会”(机器学习集成)超越,该集成能够减少预测偏差、方差或两者兼而有之,并且能够更好地捕捉数据的潜在分布。然而,在预测准确性、预测时间和规模方面仍有许多方面有待研究。在生长季节越早进行预测越好,但由于先前的研究考虑了所有可用数据来预测产量,这一点尚未得到充分研究。本文提供了一个基于机器学习的框架,用于预测美国玉米带三个州(伊利诺伊州、印第安纳州和爱荷华州)的玉米产量,同时考虑完整和部分季中天气信息。使用分块顺序程序设计了几个集成模型,以生成袋外预测。预测是在县级尺度上进行的,并汇总到农业区和州级尺度。结果表明,所提出的优化加权集成模型和平均集成模型是最精确的模型,相对均方根误差(RRMSE)为9.5%。堆叠套索回归做出的预测偏差最小(平均偏差误差为53公斤/公顷),而其他集成模型在偏差方面也优于基础学习器。相反,尽管随机k折交叉验证被分块顺序程序所取代,但结果表明,对于时间序列数据集,堆叠集成模型的表现不如加权集成模型,因为它们需要数据是非独立同分布的才能表现良好。将我们提出的模型预测与文献进行比较,证明了我们提出的集成模型所做预测的可接受性能。部分季中天气信息情景的结果表明,早在6月1日就可以做出相对均方根误差为9.2%的良好产量预测。此外,结果表明,所提出的模型在农业区、州级尺度以及县级尺度上的表现均优于单个模型和基准集成模型。为了找出每个输入特征对所提出的集成模型预测的边际效应,提出了一种方法,该方法是确定集成模型特征重要性的基础。研究结果表明,与第18 - 24周(5月1日至6月1日)天气相对应的天气特征是最重要的输入特征。