University of York.
University of Sussex.
J Cogn Neurosci. 2021 Mar;33(3):445-462. doi: 10.1162/jocn_a_01654. Epub 2020 Dec 7.
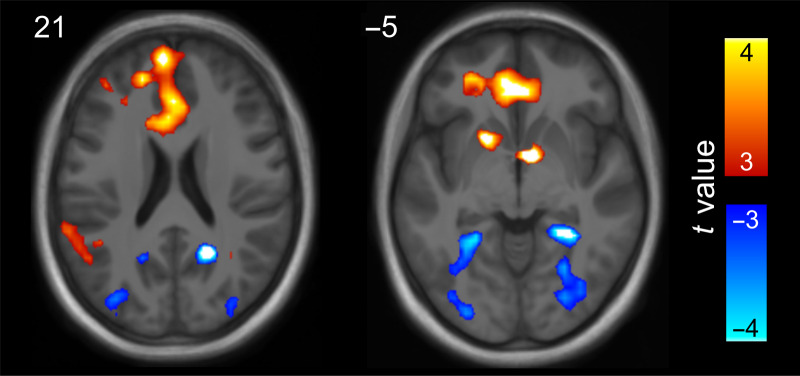
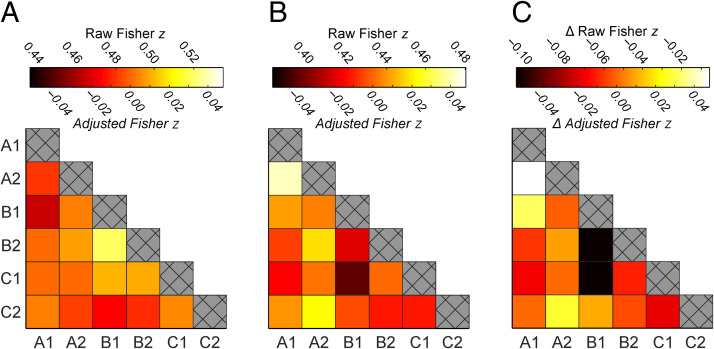
Scene-selective regions of the human brain form allocentric representations of locations in our environment. These representations are independent of heading direction and allow us to know where we are regardless of our direction of travel. However, we know little about how these location-based representations are formed. Using fMRI representational similarity analysis and linear mixed models, we tracked the emergence of location-based representations in scene-selective brain regions. We estimated patterns of activity for two distinct scenes, taken before and after participants learnt they were from the same location. During a learning phase, we presented participants with two types of panoramic videos: (1) an overlap video condition displaying two distinct scenes (0° and 180°) from the same location and (2) a no-overlap video displaying two distinct scenes from different locations (which served as a control condition). In the parahippocampal cortex (PHC) and retrosplenial cortex (RSC), representations of scenes from the same location became more similar to each other only after they had been shown in the overlap condition, suggesting the emergence of viewpoint-independent location-based representations. Whereas these representations emerged in the PHC regardless of task performance, RSC representations only emerged for locations where participants could behaviorally identify the two scenes as belonging to the same location. The results suggest that we can track the emergence of location-based representations in the PHC and RSC in a single fMRI experiment. Further, they support computational models that propose the RSC plays a key role in transforming viewpoint-independent representations into behaviorally relevant representations of specific viewpoints.
人类大脑的场景选择性区域形成了我们环境中位置的定位表示。这些表示与朝向方向无关,使我们能够在不考虑行进方向的情况下知道自己的位置。然而,我们对这些基于位置的表示是如何形成的知之甚少。使用 fMRI 代表性相似性分析和线性混合模型,我们跟踪了场景选择性脑区中基于位置的表示的出现。我们估计了两个不同场景的活动模式,这些场景是在参与者知道它们来自同一位置之前和之后拍摄的。在学习阶段,我们向参与者展示了两种类型的全景视频:(1)重叠视频条件,显示来自同一位置的两个不同场景(0°和 180°);(2)无重叠视频,显示来自不同位置的两个不同场景(作为对照条件)。在海马旁回皮质(PHC)和后扣带回皮质(RSC)中,只有在重叠条件下展示了来自同一位置的场景后,这些场景的表示才变得更加相似,这表明出现了与视角无关的基于位置的表示。虽然这些表示在 PHC 中无论任务表现如何都会出现,但 RSC 的表示仅在参与者可以行为识别出两个场景属于同一位置的情况下出现。结果表明,我们可以在单个 fMRI 实验中跟踪 PHC 和 RSC 中基于位置的表示的出现。此外,它们支持计算模型,该模型提出 RSC 在将与视角无关的表示转换为特定视角的行为相关表示方面发挥关键作用。