Department of Computer Science, Vanderbilt University, Nashville, TN, USA.
School of Medicine, Vanderbilt University, Nashville, TN, USA.
Med Phys. 2021 Oct;48(10):6060-6068. doi: 10.1002/mp.15122. Epub 2021 Aug 22.
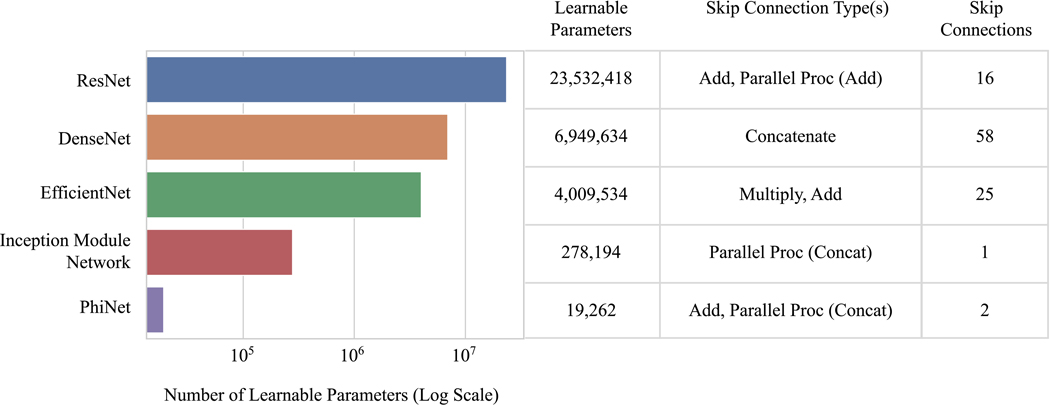
Artificial intelligence diagnosis and triage of large vessel occlusion may quicken clinical response for a subset of time-sensitive acute ischemic stroke patients, improving outcomes. Differences in architectural elements within data-driven convolutional neural network (CNN) models impact performance. Foreknowledge of effective model architectural elements for domain-specific problems can narrow the search for candidate models and inform strategic model design and adaptation to optimize performance on available data. Here, we study CNN architectures with a range of learnable parameters and which span the inclusion of architectural elements, such as parallel processing branches and residual connections with varying methods of recombining residual information.
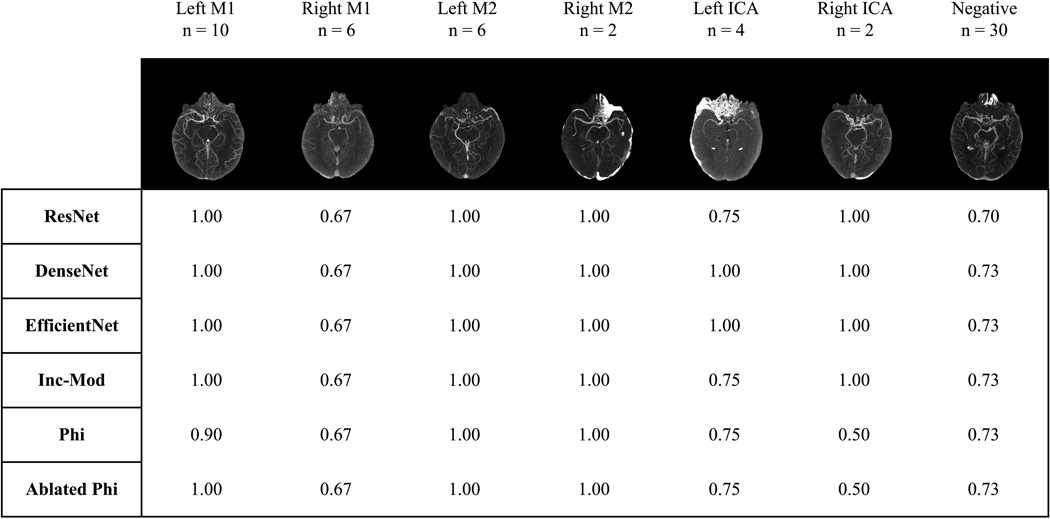
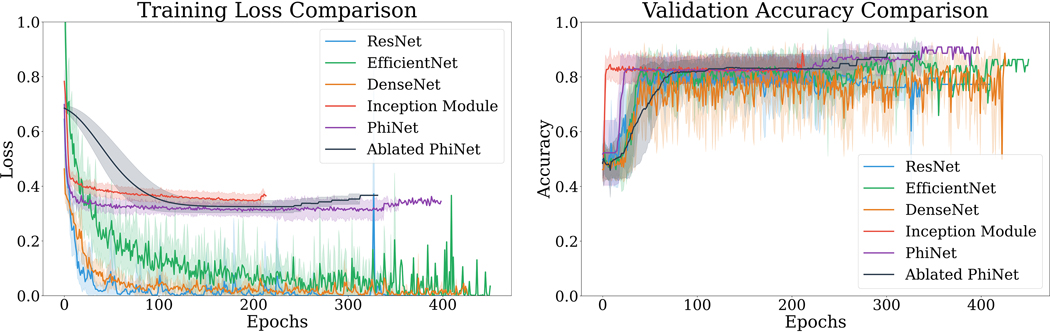
We compare five CNNs: ResNet-50, DenseNet-121, EfficientNet-B0, PhiNet, and an Inception module-based network, on a computed tomography angiography large vessel occlusion detection task. The models were trained and preliminarily evaluated with 10-fold cross-validation on preprocessed scans (n = 240). An ablation study was performed on PhiNet due to superior cross-validated test performance across accuracy, precision, recall, specificity, and F1 score. The final evaluation of all models was performed on a withheld external validation set (n = 60) and these predictions were subsequently calibrated with sigmoid curves.
Uncalibrated results on the withheld external validation set show that DenseNet-121 had the best average performance on accuracy, precision, recall, specificity, and F1 score. After calibration DenseNet-121 maintained superior performance on all metrics except recall.
The number of learnable parameters in our five models and best-ablated PhiNet directly related to cross-validated test performance-the smaller the model the better. However, this pattern did not hold when looking at generalization on the withheld external validation set. DenseNet-121 generalized the best; we posit this was due to its heavy use of residual connections utilizing concatenation, which causes feature maps from earlier layers to be used deeper in the network, while aiding in gradient flow and regularization.
人工智能对大血管闭塞的诊断和分诊可能会加快一部分时间敏感的急性缺血性脑卒中患者的临床反应,从而改善预后。数据驱动卷积神经网络(CNN)模型中的结构元素差异会影响模型性能。对于特定领域的问题,了解有效的模型结构元素可以缩小候选模型的搜索范围,并为优化可用数据上的性能提供战略模型设计和适应性的信息。在这里,我们研究了具有一系列可学习参数的 CNN 架构,这些架构涵盖了架构元素的包含,例如具有不同的残差信息重组方法的并行处理分支和残差连接。
我们在计算机断层血管造影大血管闭塞检测任务中比较了五种 CNN:ResNet-50、DenseNet-121、EfficientNet-B0、PhiNet 和基于 Inception 模块的网络。模型在预处理扫描上使用 10 折交叉验证进行训练和初步评估(n=240)。由于 PhiNet 在准确性、精度、召回率、特异性和 F1 评分的交叉验证测试性能均较高,因此对其进行了消融研究。对所有模型的最终评估是在保留的外部验证集上进行的(n=60),并使用 sigmoid 曲线对这些预测进行了校准。
在保留的外部验证集上的未校准结果表明,DenseNet-121 在准确性、精度、召回率、特异性和 F1 评分方面具有最佳的平均性能。校准后,DenseNet-121 在除召回率之外的所有指标上均保持了较高的性能。
我们五个模型中的可学习参数数量和最佳消融 PhiNet 直接关系到交叉验证测试性能——模型越小越好。但是,当我们观察保留的外部验证集上的泛化时,这种模式并不成立。DenseNet-121 泛化效果最好;我们推测这是由于其大量使用残差连接利用串联,这使得来自早期层的特征图在网络中更深地使用,同时有助于梯度流和正则化。