Satoła Alicja, Bauer Edyta Agnieszka
Department of Genetics, Animal Breeding and Ethology, Faculty of Animal Science, University of Agriculture in Krakow, al. Mickiewicza 24/28, 30-059 Krakow, Poland.
Department of Animal Reproduction, Anatomy and Genomics, Faculty of Animal Science, University of Agriculture in Krakow, al. Mickiewicza 24/28, 30-059 Krakow, Poland.
Animals (Basel). 2021 Jul 19;11(7):2131. doi: 10.3390/ani11072131.
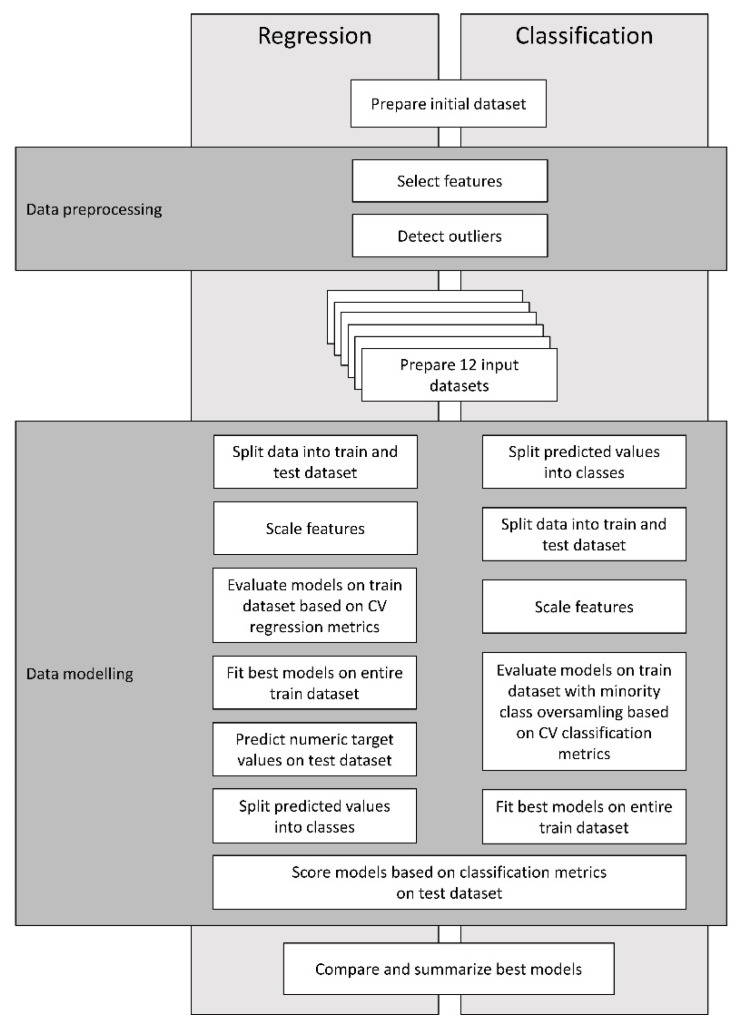
The diagnosis of subclinical ketosis in dairy cows based on blood ketone bodies is a challenging and costly procedure. Scientists are searching for tools based on results of milk performance assessment that would allow monitoring the risk of subclinical ketosis. The objective of the study was (1) to design a scoring system that would allow choosing the best machine learning models for the identification of cows-at-risk of subclinical ketosis, (2) to select the best performing models, and (3) to validate them using a testing dataset containing unseen data. The scoring system was developed using two machine learning modeling pipelines, one for regression and one for classification. As part of the system, different feature selections, outlier detection, data scaling and oversampling methods were used. Various linear and non-linear models were fit using training datasets and evaluated on holdout, testing the datasets. For the assessment of suitability of individual models for predicting subclinical ketosis, three β-hydroxybutyrate concentration in blood (bBHB) thresholds were defined: 1.0, 1.2 and 1.4 mmol/L. Considering the thresholds of 1.2 and 1.4, the logistic regression model was found to be the best fitted model, which included independent variables such as fat-to-protein ratio, acetone and β-hydroxybutyrate concentrations in milk, lactose percentage, lactation number and days in milk. In the cross-validation, this model showed an average sensitivity of 0.74 or 0.75 and specificity of 0.76 or 0.78, at the pre-defined bBHB threshold 1.2 or 1.4 mmol/L, respectively. The values of these metrics were also similar in the external validation on the testing dataset (0.72 or 0.74 for sensitivity and 0.80 or 0.81 for specificity). For the bBHB threshold at 1.0 mmol/L, the best classification model was the model based on the SVC (Support Vector Classification) machine learning method, for which the sensitivity in the cross-validation was 0.74 and the specificity was 0.73. These metrics had lower values for the testing dataset (0.57 and 0.72 respectively). Regression models were characterized by poor fitness to data (R < 0.4). The study results suggest that the prediction of subclinical ketosis based on data from test-day records using classification methods and machine learning algorithms can be a useful tool for monitoring the incidence of this metabolic disorder in dairy cattle herds.
基于血酮体诊断奶牛亚临床酮病是一项具有挑战性且成本高昂的程序。科学家们正在寻找基于牛奶生产性能评估结果的工具,以便监测亚临床酮病风险。本研究的目的是:(1)设计一个评分系统,用于选择识别亚临床酮病风险奶牛的最佳机器学习模型;(2)选择性能最佳的模型;(3)使用包含未见数据的测试数据集对其进行验证。评分系统是使用两个机器学习建模管道开发的,一个用于回归,一个用于分类。作为系统的一部分,使用了不同的特征选择、异常值检测、数据缩放和过采样方法。使用训练数据集拟合各种线性和非线性模型,并在留出法中进行评估,测试数据集。为了评估各个模型预测亚临床酮病的适用性,定义了三个血液中β-羟基丁酸(bBHB)浓度阈值:1.0、1.2和1.4 mmol/L。考虑到1.2和1.4的阈值,发现逻辑回归模型是最佳拟合模型,该模型包括乳脂率与乳蛋白率、牛奶中丙酮和β-羟基丁酸浓度、乳糖百分比、泌乳次数和泌乳天数等自变量。在交叉验证中,该模型在预定义的bBHB阈值1.2或1.4 mmol/L时,平均灵敏度分别为0.74或0.75,特异性分别为0.76或0.78。在测试数据集的外部验证中,这些指标的值也相似(灵敏度为0.72或0.74,特异性为0.80或0.81)。对于bBHB阈值为1.0 mmol/L,最佳分类模型是基于支持向量分类(SVC)机器学习方法的模型,其在交叉验证中的灵敏度为0.74,特异性为根据测试数据集,这些指标的值较低(分别为0.57和0.72)。回归模型的数据拟合度较差(R < 0.4)。研究结果表明,使用分类方法和机器学习算法基于测定日记录数据预测亚临床酮病,可成为监测奶牛群体中这种代谢紊乱发病率的有用工具。