Deep Digital Phenotyping Research Unit, Department of Population Health, Luxembourg Institute of Health, 1A-B, rue Thomas Edison, 1445, Strassen, Luxembourg.
Center of Epidemiology and Population Health UMR 1018, Inserm, Gustave Roussy Institute, Paris South - Paris Saclay University, Villejuif, France.
Sci Rep. 2021 Aug 6;11(1):16056. doi: 10.1038/s41598-021-95487-5.
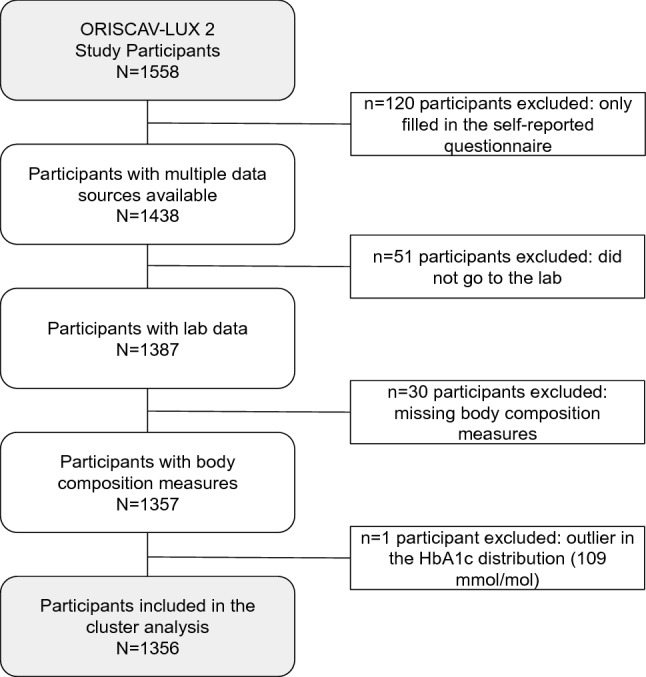
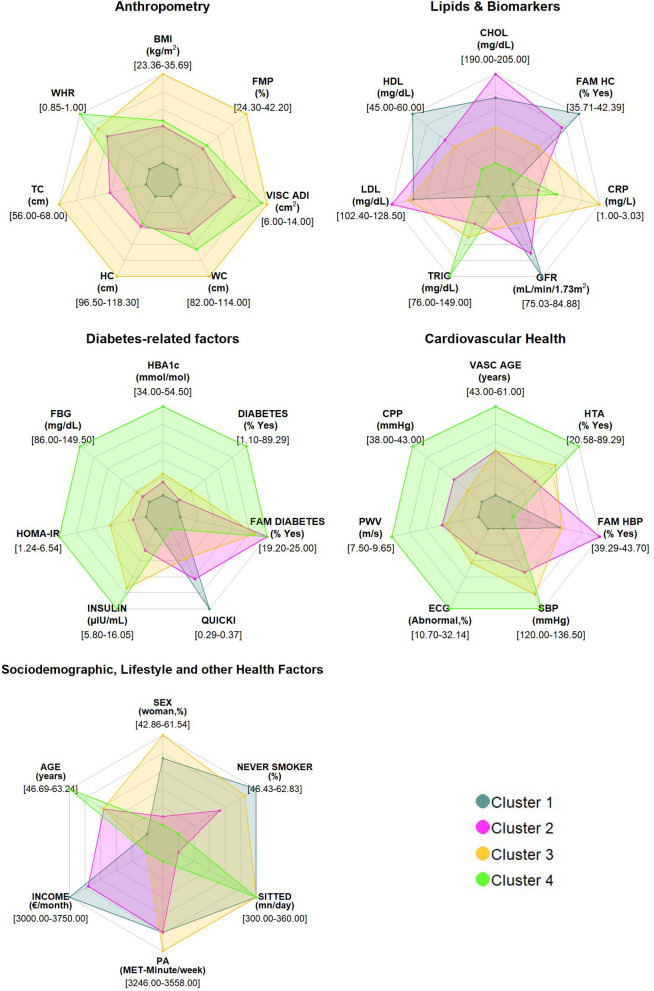
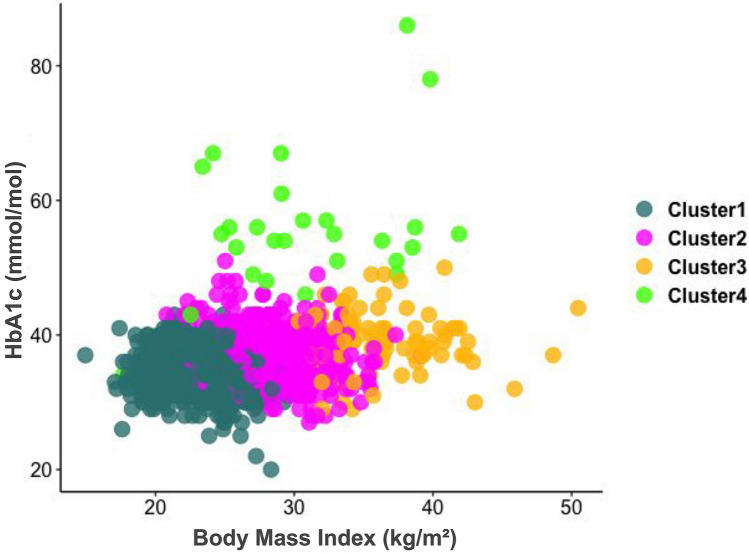
Given the rapid increase in the incidence of cardiometabolic conditions, there is an urgent need for better approaches to prevent as many cases as possible and move from a one-size-fits-all approach to a precision cardiometabolic prevention strategy in the general population. We used data from ORISCAV-LUX 2, a nationwide, cross-sectional, population-based study. On the 1356 participants, we used a machine learning semi-supervised cluster method guided by body mass index (BMI) and glycated hemoglobin (HbA1c), and a set of 29 cardiometabolic variables, to identify subgroups of interest for cardiometabolic health. Cluster stability was assessed with the Jaccard similarity index. We have observed 4 clusters with a very high stability (ranging between 92 and 100%). Based on distinctive features that deviate from the overall population distribution, we have labeled Cluster 1 (N = 729, 53.76%) as "Healthy", Cluster 2 (N = 508, 37.46%) as "Family history-Overweight-High Cholesterol ", Cluster 3 (N = 91, 6.71%) as "Severe Obesity-Prediabetes-Inflammation" and Cluster 4 (N = 28, 2.06%) as "Diabetes-Hypertension-Poor CV Health". Our work provides an in-depth characterization and thus, a better understanding of cardiometabolic health in the general population. Our data suggest that such a clustering approach could now be used to define more targeted and tailored strategies for the prevention of cardiometabolic diseases at a population level. This study provides a first step towards precision cardiometabolic prevention and should be externally validated in other contexts.
鉴于心血管代谢疾病发病率的迅速增加,我们迫切需要更好的方法来预防尽可能多的病例,并从针对所有人的一刀切方法转变为针对普通人群的精准心血管代谢预防策略。我们使用了来自 ORISCAV-LUX 2 的数据,这是一项全国性的、横断面的、基于人群的研究。在 1356 名参与者中,我们使用了一种由体重指数 (BMI) 和糖化血红蛋白 (HbA1c) 指导的机器学习半监督聚类方法,以及一组 29 个心血管代谢变量,来确定对心血管代谢健康感兴趣的亚组。使用 Jaccard 相似指数评估聚类稳定性。我们观察到 4 个具有非常高稳定性的聚类(范围在 92%到 100%之间)。基于与总体人群分布不同的特征,我们将聚类 1(N=729,53.76%)标记为“健康”,聚类 2(N=508,37.46%)标记为“有家族史的超重高胆固醇”,聚类 3(N=91,6.71%)标记为“严重肥胖前驱糖尿病炎症”,聚类 4(N=28,2.06%)标记为“糖尿病高血压心血管健康不良”。我们的工作提供了对心血管代谢健康的深入描述,从而更好地理解了普通人群的心血管代谢健康。我们的数据表明,这种聚类方法现在可以用于在人群层面定义更有针对性和定制化的心血管代谢疾病预防策略。本研究为精准心血管代谢预防迈出了第一步,应在其他环境中进行外部验证。