Department of Radiology, Duke University Medical Center, Durham, North Carolina.
Department of Electrical and Computer Engineering, Duke University, Durham, North Carolina.
JAMA Netw Open. 2021 Aug 2;4(8):e2119100. doi: 10.1001/jamanetworkopen.2021.19100.
Breast cancer screening is among the most common radiological tasks, with more than 39 million examinations performed each year. While it has been among the most studied medical imaging applications of artificial intelligence, the development and evaluation of algorithms are hindered by the lack of well-annotated, large-scale publicly available data sets.
To curate, annotate, and make publicly available a large-scale data set of digital breast tomosynthesis (DBT) images to facilitate the development and evaluation of artificial intelligence algorithms for breast cancer screening; to develop a baseline deep learning model for breast cancer detection; and to test this model using the data set to serve as a baseline for future research.
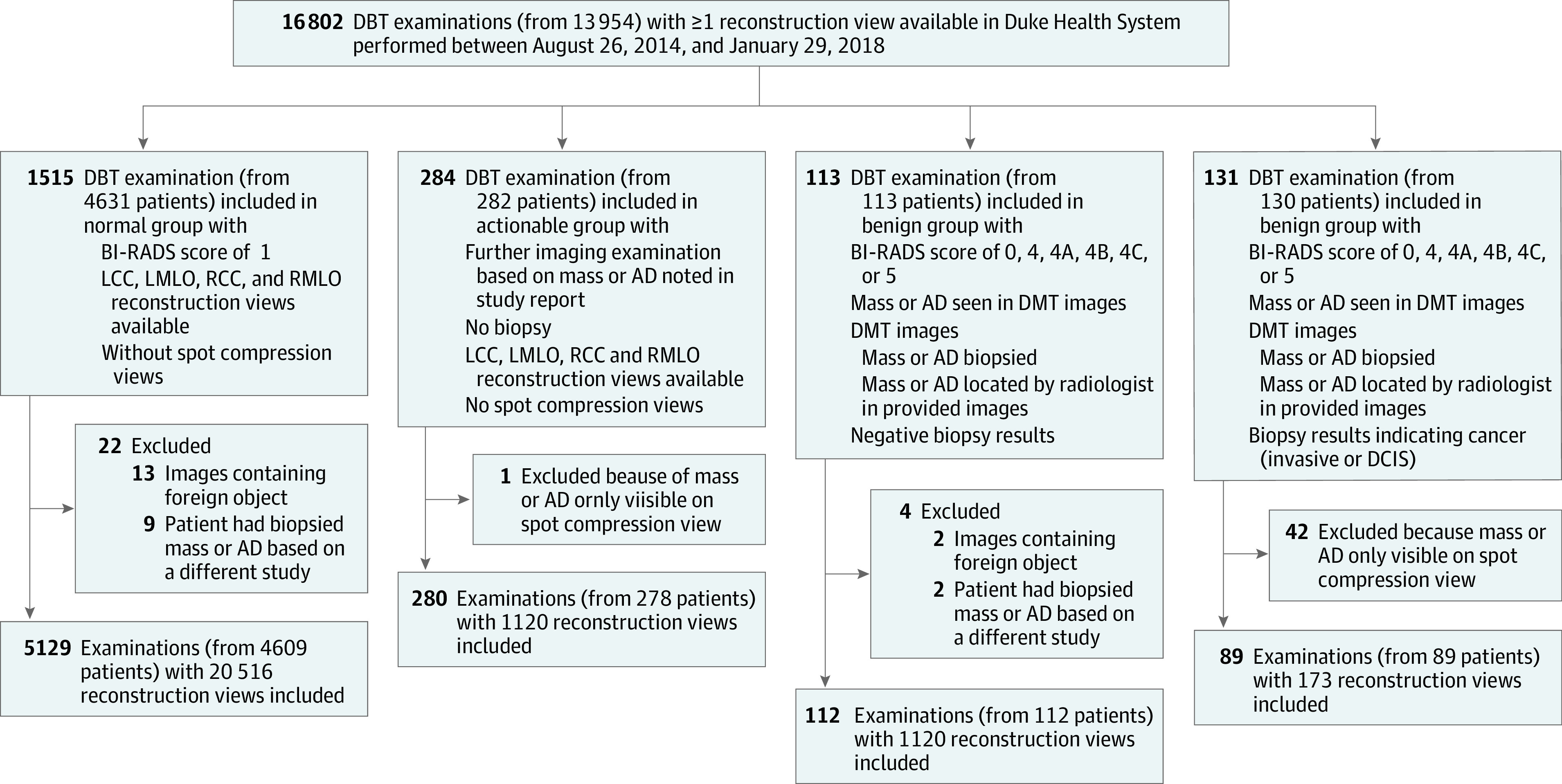
DESIGN, SETTING, AND PARTICIPANTS: In this diagnostic study, 16 802 DBT examinations with at least 1 reconstruction view available, performed between August 26, 2014, and January 29, 2018, were obtained from Duke Health System and analyzed. From the initial cohort, examinations were divided into 4 groups and split into training and test sets for the development and evaluation of a deep learning model. Images with foreign objects or spot compression views were excluded. Data analysis was conducted from January 2018 to October 2020.
Screening DBT.
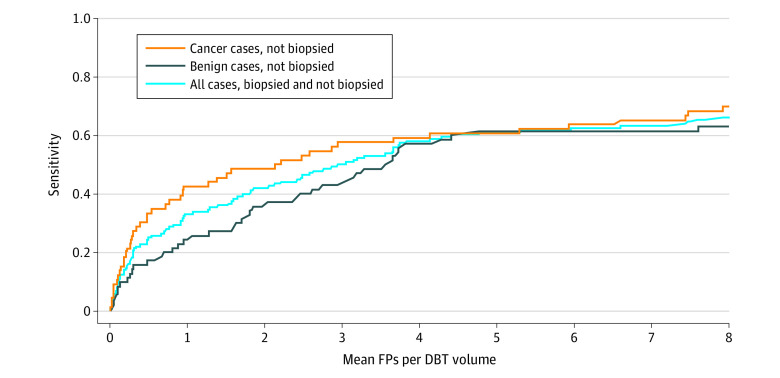
The detection algorithm was evaluated with breast-based free-response receiver operating characteristic curve and sensitivity at 2 false positives per volume.
The curated data set contained 22 032 reconstructed DBT volumes that belonged to 5610 studies from 5060 patients with a mean (SD) age of 55 (11) years and 5059 (100.0%) women. This included 4 groups of studies: (1) 5129 (91.4%) normal studies; (2) 280 (5.0%) actionable studies, for which where additional imaging was needed but no biopsy was performed; (3) 112 (2.0%) benign biopsied studies; and (4) 89 studies (1.6%) with cancer. Our data set included masses and architectural distortions that were annotated by 2 experienced radiologists. Our deep learning model reached breast-based sensitivity of 65% (39 of 60; 95% CI, 56%-74%) at 2 false positives per DBT volume on a test set of 460 examinations from 418 patients.
The large, diverse, and curated data set presented in this study could facilitate the development and evaluation of artificial intelligence algorithms for breast cancer screening by providing data for training as well as a common set of cases for model validation. The performance of the model developed in this study showed that the task remains challenging; its performance could serve as a baseline for future model development.
乳腺癌筛查是最常见的放射学任务之一,每年进行的检查超过 3900 万次。尽管它是人工智能在医学影像学应用中研究最多的领域之一,但由于缺乏经过良好注释的大规模公共可用数据集,算法的开发和评估受到了阻碍。
整理、注释并公开一个大型数字乳腺断层摄影术(DBT)图像数据集,以促进用于乳腺癌筛查的人工智能算法的开发和评估;开发用于乳腺癌检测的基础深度学习模型;并使用该数据集测试该模型,作为未来研究的基线。
设计、设置和参与者:在这项诊断研究中,从杜克健康系统(Duke Health System)获得了 2014 年 8 月 26 日至 2018 年 1 月 29 日期间进行的至少有 1 个重建视图的 16802 次 DBT 检查,并进行了分析。从初始队列中,将检查分为 4 组,并将其分为训练集和测试集,以开发和评估深度学习模型。排除了有异物或斑点压缩视图的图像。数据分析于 2018 年 1 月至 2020 年 10 月进行。
筛查 DBT。
使用基于乳房的自由响应接收器操作特征曲线和每 2 个假阳性的体积敏感性来评估检测算法。
整理后的数据集包含 22032 个重建的 DBT 卷,来自 5060 名患者的 5030 项研究,平均(SD)年龄为 55(11)岁,其中 5059 名(100.0%)为女性。这包括 4 组研究:(1)5129 项(91.4%)正常研究;(2)280 项(5.0%)可采取行动的研究,需要额外的影像学检查,但未进行活检;(3)112 项(2.0%)良性活检研究;(4)89 项(1.6%)有癌症的研究。我们的数据集中包括肿块和结构扭曲,这些都是由 2 名有经验的放射科医生注释的。我们的深度学习模型在 460 次检查的测试集(来自 418 名患者)上达到了每 DBT 体积 2 个假阳性的乳房敏感性为 65%(39 例;95%CI,56%-74%)。
本研究中提出的大型、多样化和整理后的数据集可以通过提供训练数据以及用于模型验证的通用病例集来促进乳腺癌筛查的人工智能算法的开发和评估。本研究中开发的模型的性能表明该任务仍然具有挑战性;其性能可作为未来模型开发的基线。