Catala Omar Del Tejo, Igual Ismael Salvador, Perez-Benito Francisco Javier, Escriva David Millan, Castello Vicent Ortiz, Llobet Rafael, Perez-Cortes Juan-Carlos
Instituto Tecnológico de Informática (ITI), Universitat Politècnica de València 46022 Valencia Spain.
Department of Computer Systems and Computation (DSIC)Universitat Politècnica de València 46022 Valencia Spain.
IEEE Access. 2021 Mar 10;9:42370-42383. doi: 10.1109/ACCESS.2021.3065456. eCollection 2021.
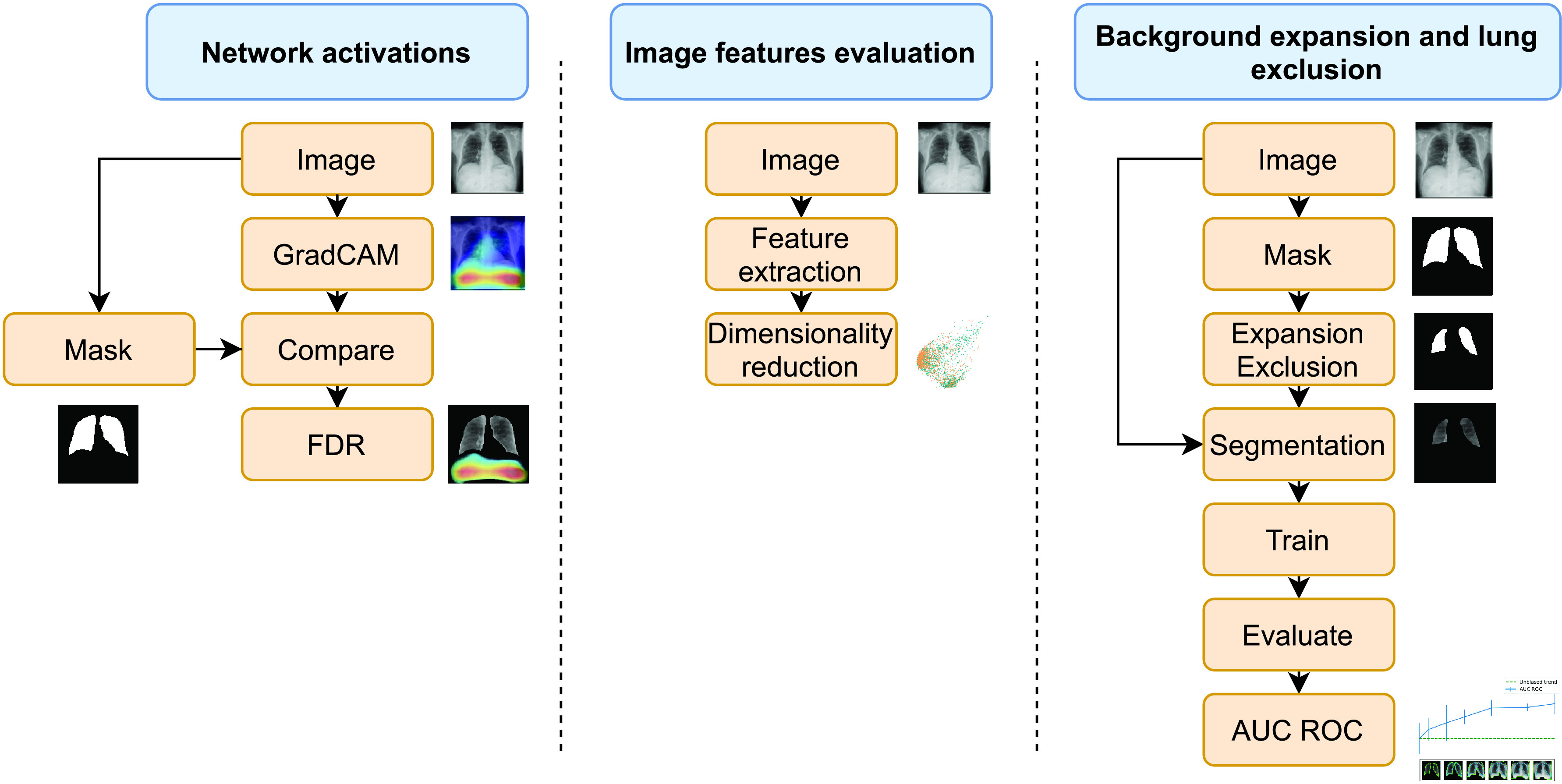
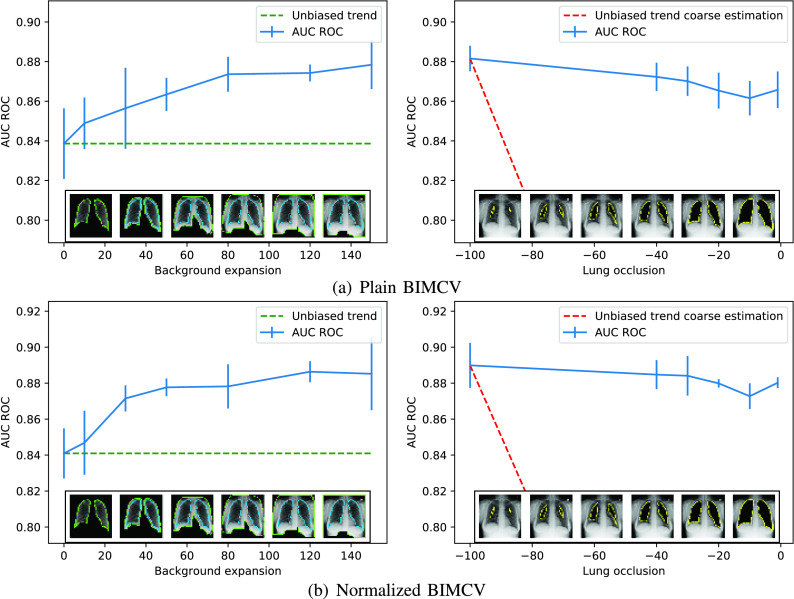
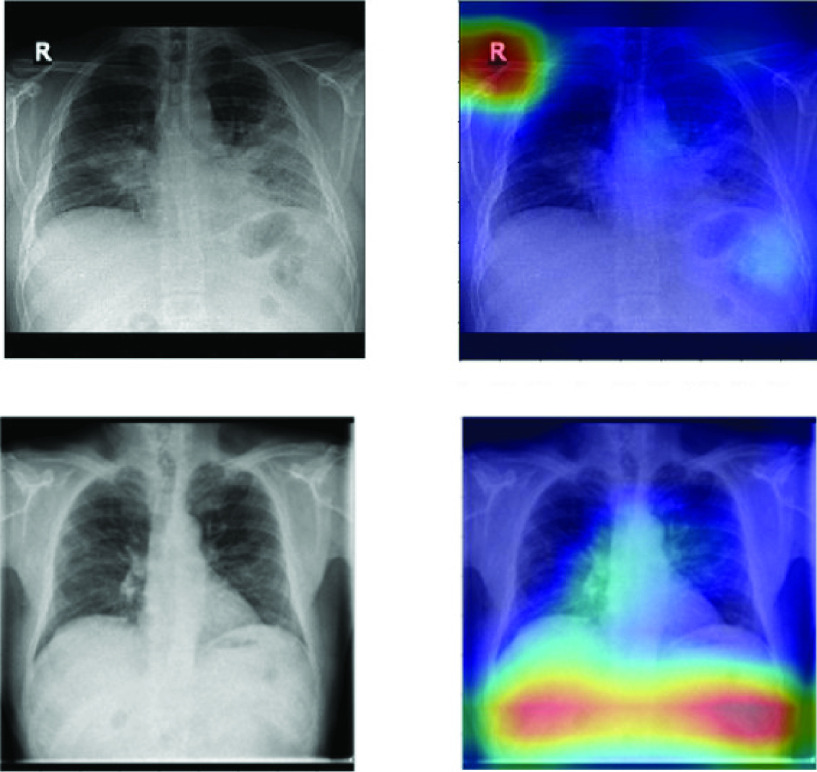
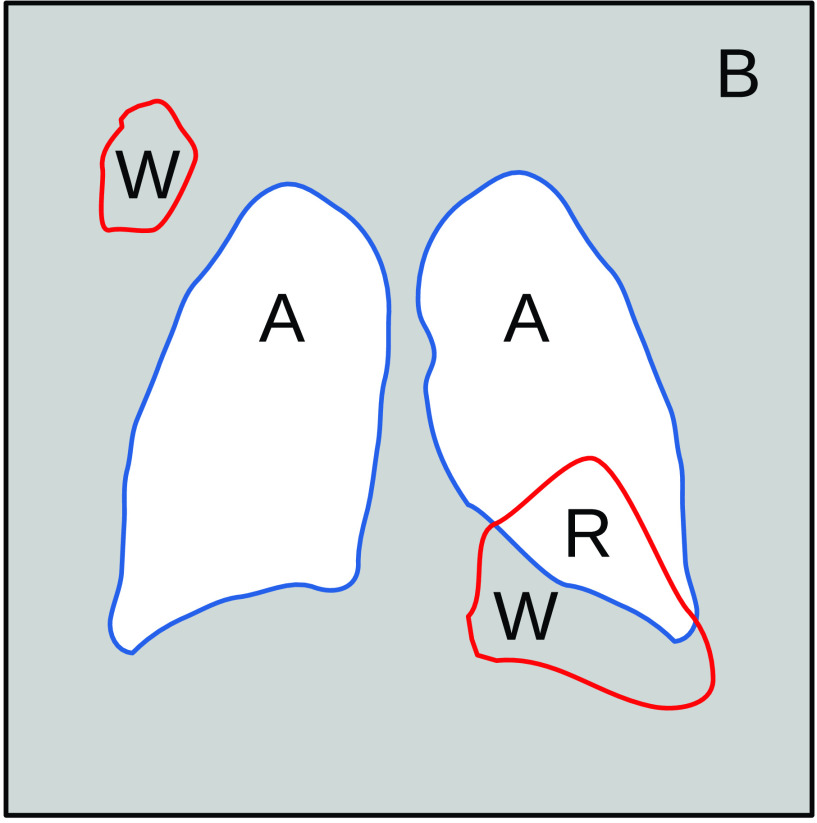
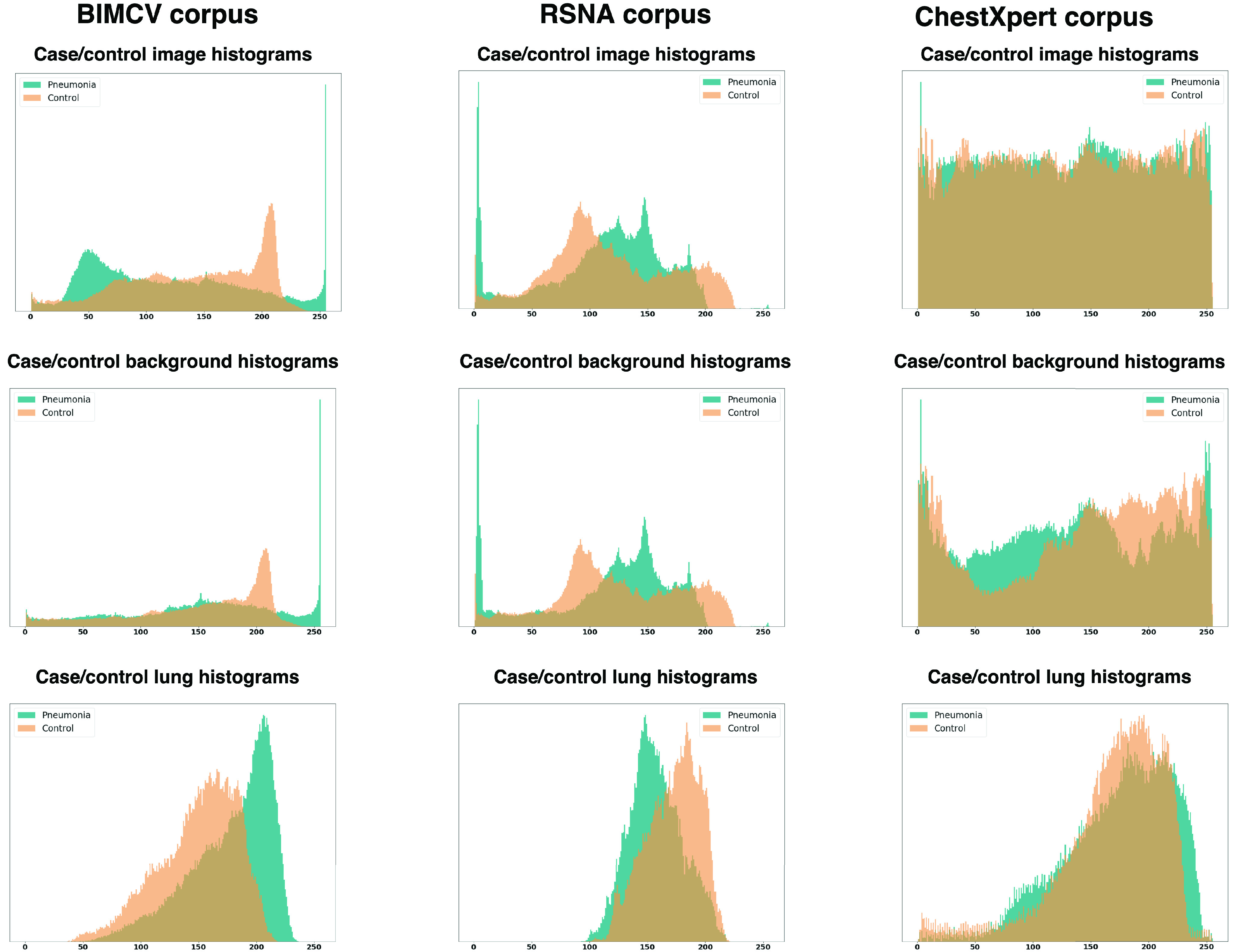
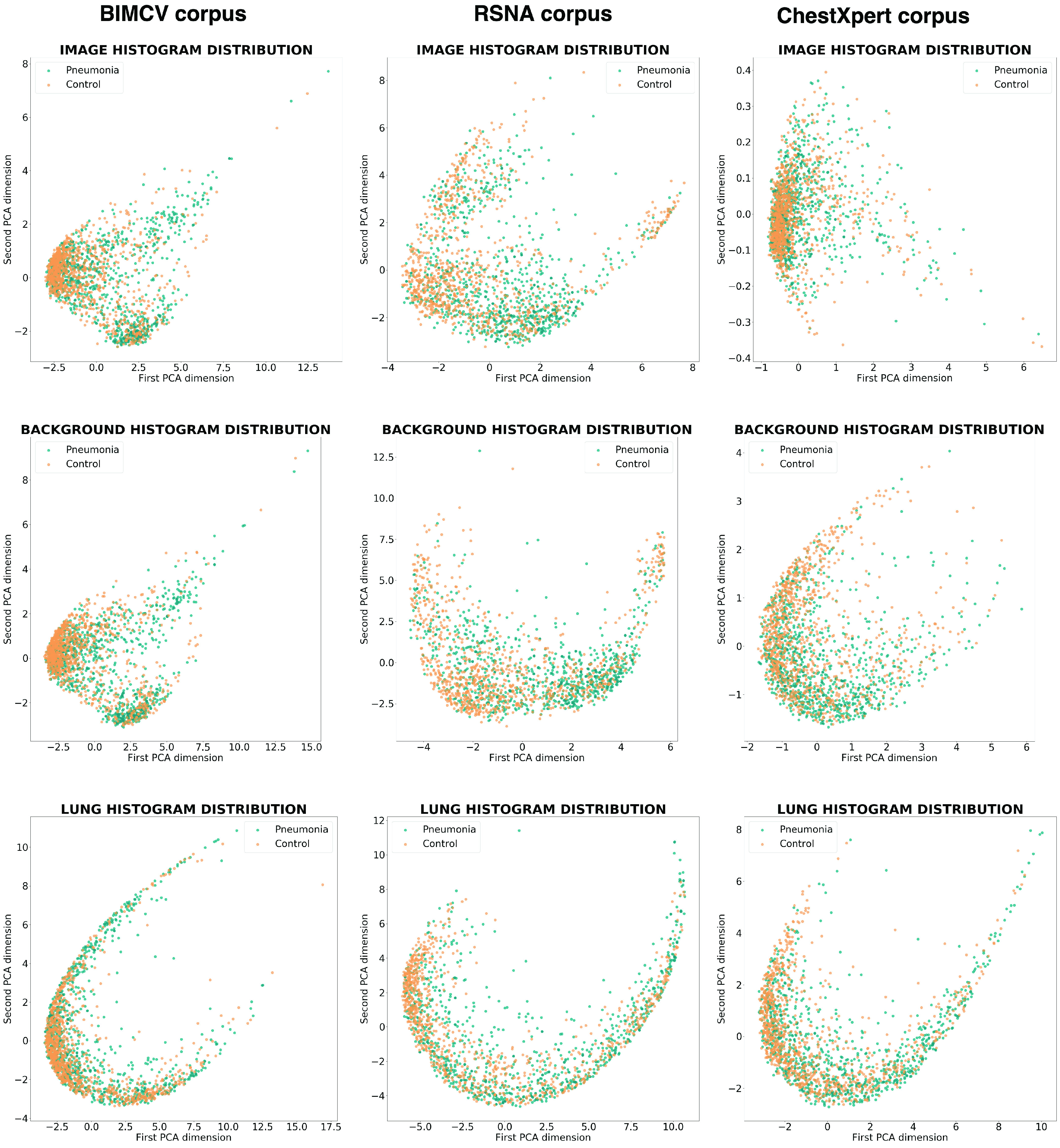
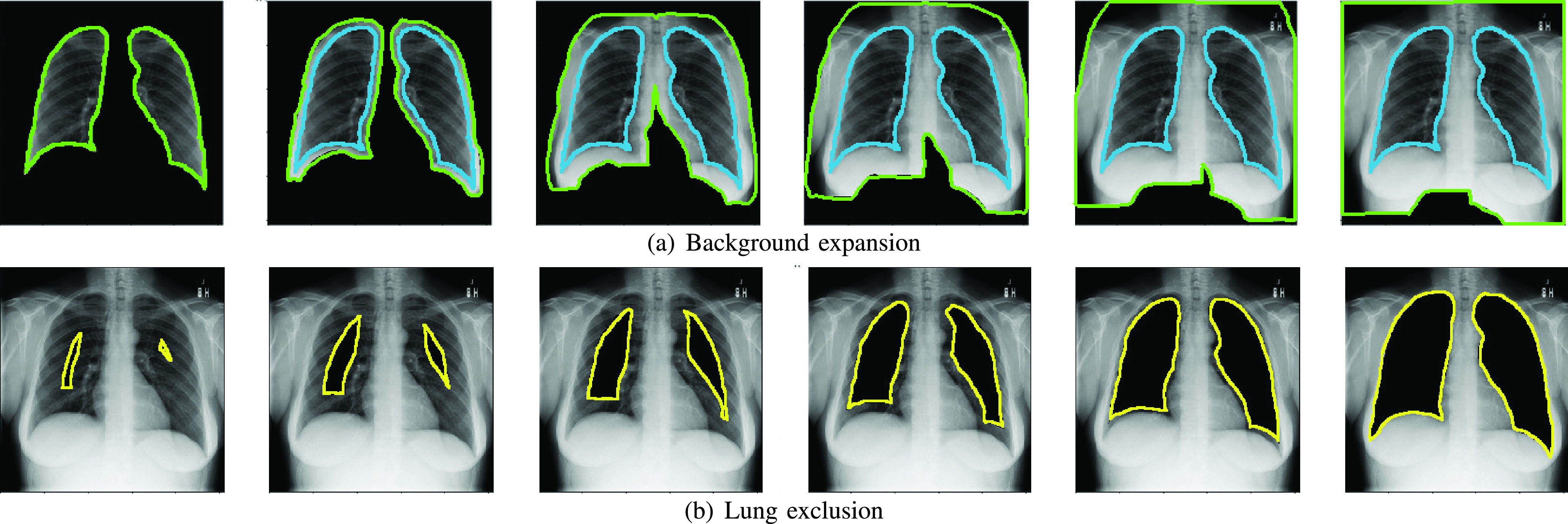
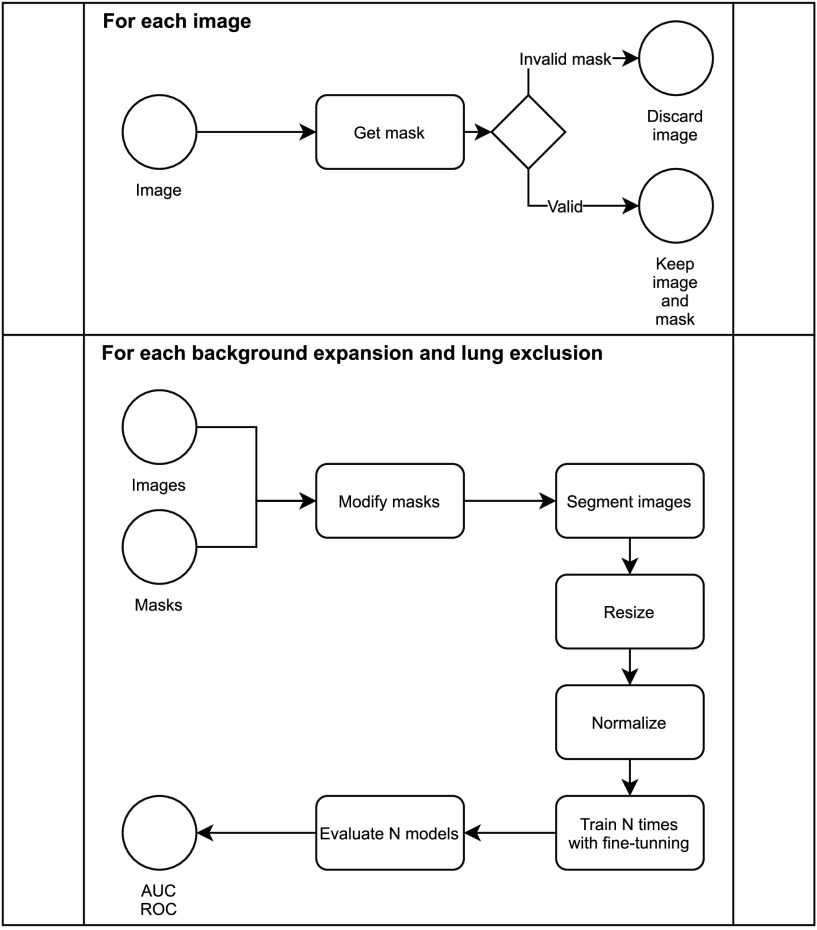
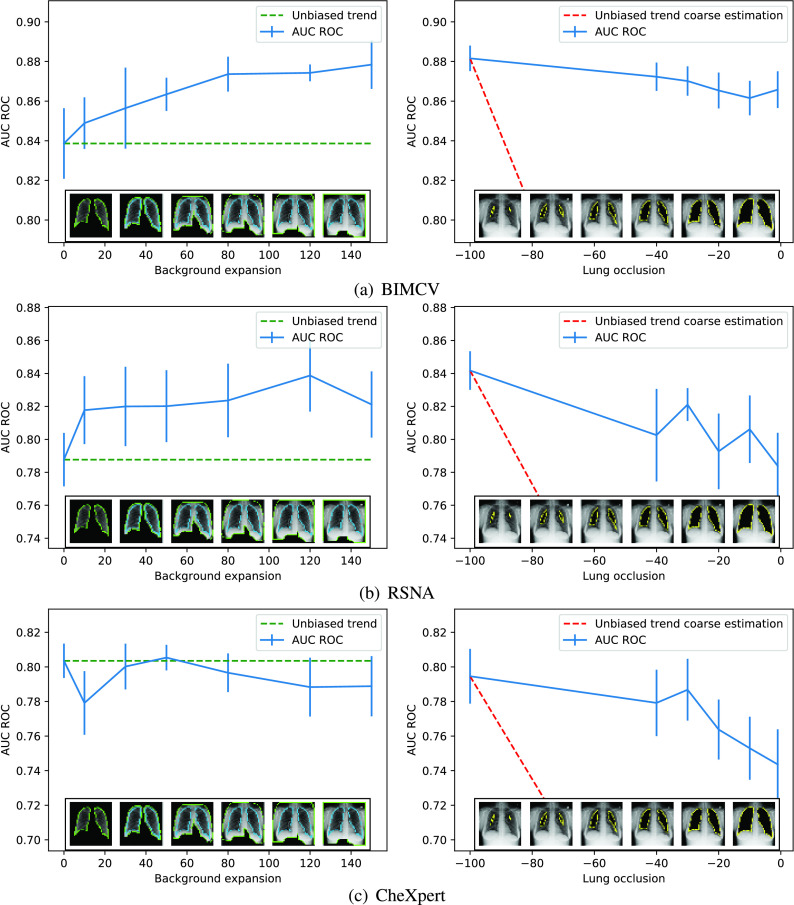
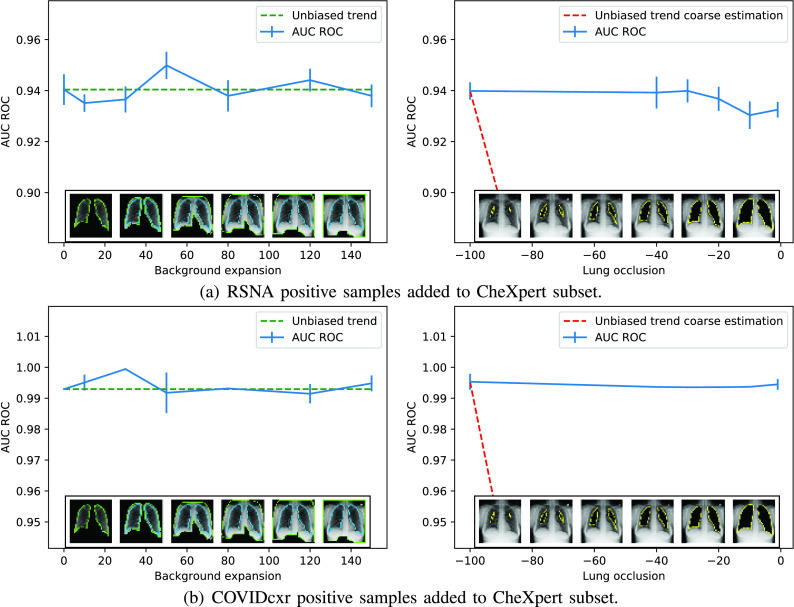
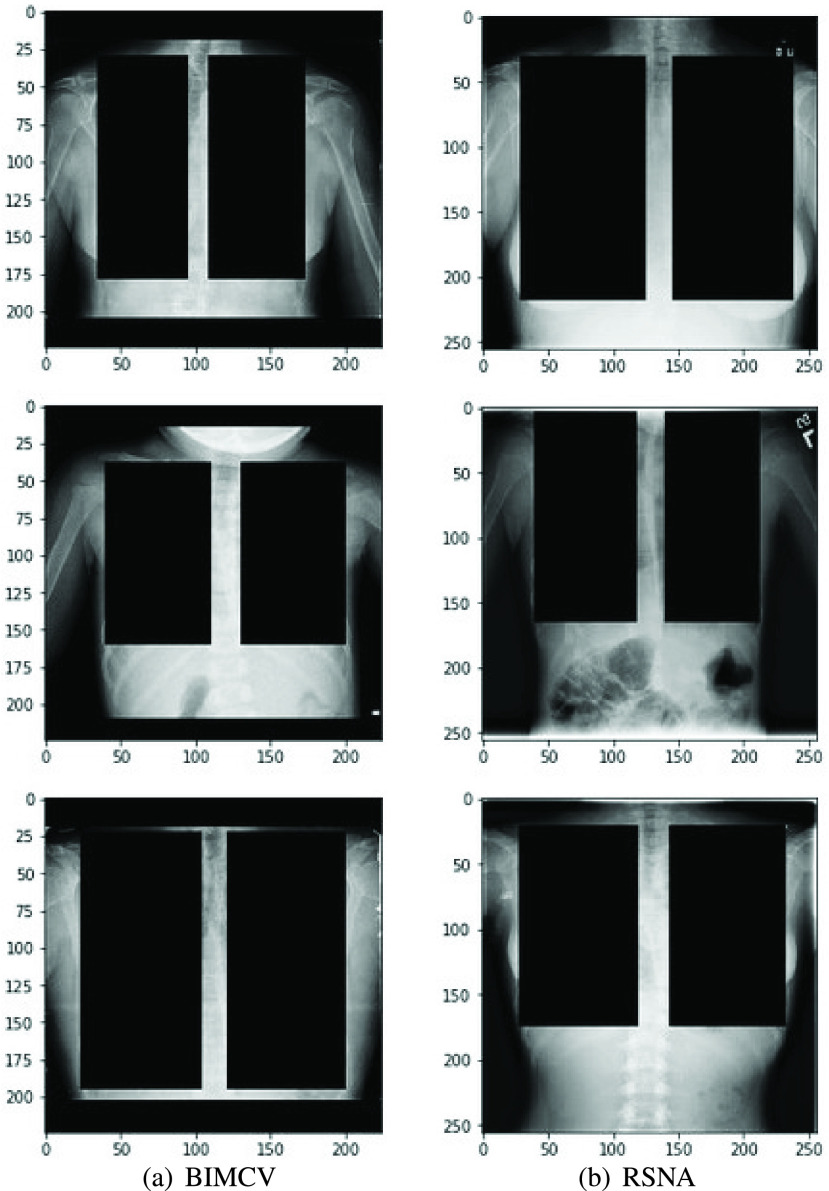
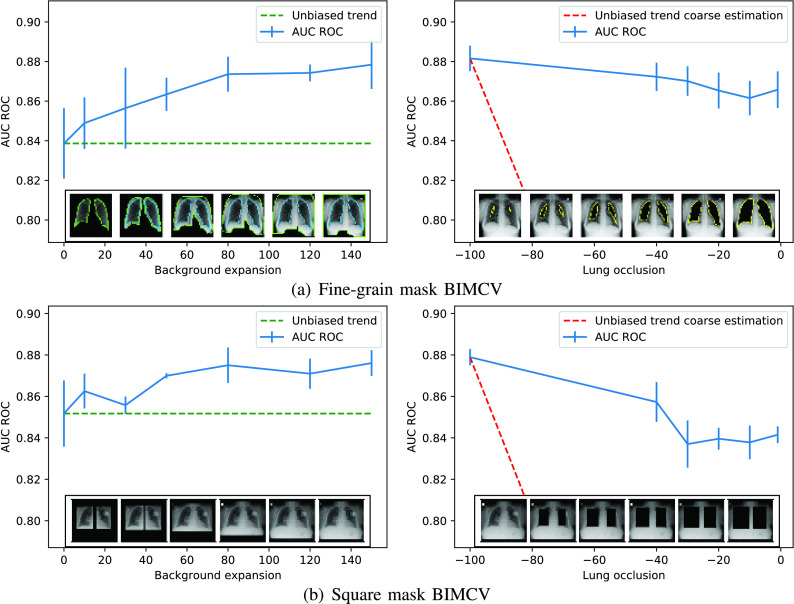
Chest X-ray images are useful for early COVID-19 diagnosis with the advantage that X-ray devices are already available in health centers and images are obtained immediately. Some datasets containing X-ray images with cases (pneumonia or COVID-19) and controls have been made available to develop machine-learning-based methods to aid in diagnosing the disease. However, these datasets are mainly composed of different sources coming from pre-COVID-19 datasets and COVID-19 datasets. Particularly, we have detected a significant bias in some of the released datasets used to train and test diagnostic systems, which might imply that the results published are optimistic and may overestimate the actual predictive capacity of the techniques proposed. In this article, we analyze the existing bias in some commonly used datasets and propose a series of preliminary steps to carry out before the classic machine learning pipeline in order to detect possible biases, to avoid them if possible and to report results that are more representative of the actual predictive power of the methods under analysis.
胸部X光图像对于早期诊断新冠肺炎很有用,其优势在于健康中心已有X光设备,且能立即获取图像。一些包含病例(肺炎或新冠肺炎)和对照的X光图像数据集已可供使用,以开发基于机器学习的方法来辅助疾病诊断。然而,这些数据集主要由来自新冠肺炎疫情前数据集和新冠肺炎数据集的不同来源组成。特别是,我们在一些用于训练和测试诊断系统的已发布数据集中检测到了显著偏差,这可能意味着所发表的结果较为乐观,可能高估了所提出技术的实际预测能力。在本文中,我们分析了一些常用数据集中存在的偏差,并提出了一系列在经典机器学习流程之前要采取的初步步骤,以便检测可能的偏差,尽可能避免这些偏差,并报告更能代表所分析方法实际预测能力的结果。