Zhou Jiaogen, Xiong Wei, Wang Yang, Guan Jihong
Jiangsu Provincial Engineering Research Center for Intelligent Monitoring and Ecological Management of Pond and Reservoir Water Environment, Huaiyin Normal University, Huian, China.
Shanghai Key Lab of Intelligent Information Processing, and School of Computer Science, Fudan University, Shanghai, China.
Front Genet. 2021 Dec 14;12:758131. doi: 10.3389/fgene.2021.758131. eCollection 2021.
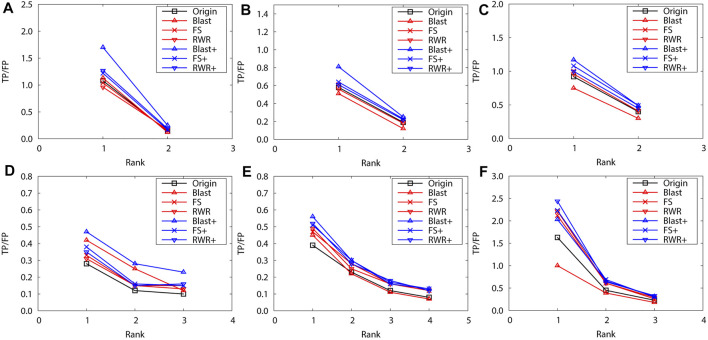
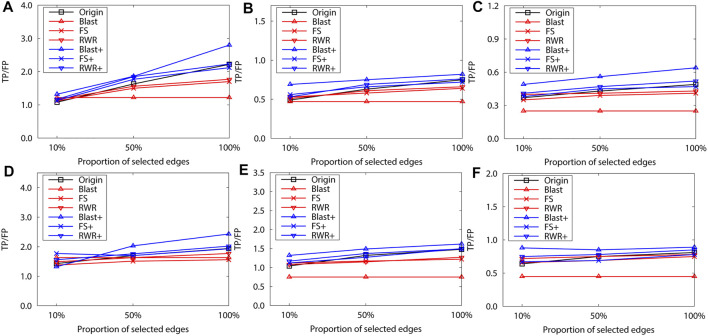
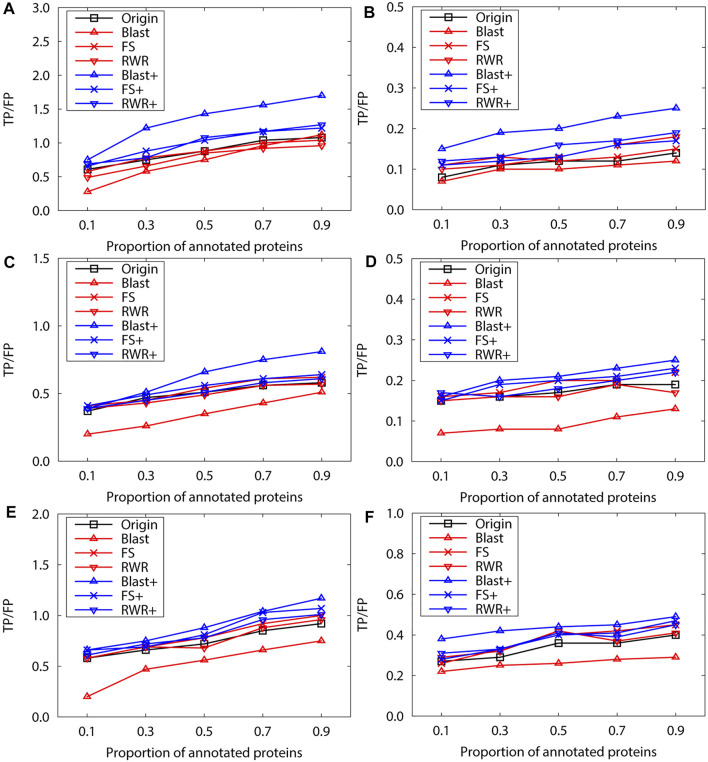
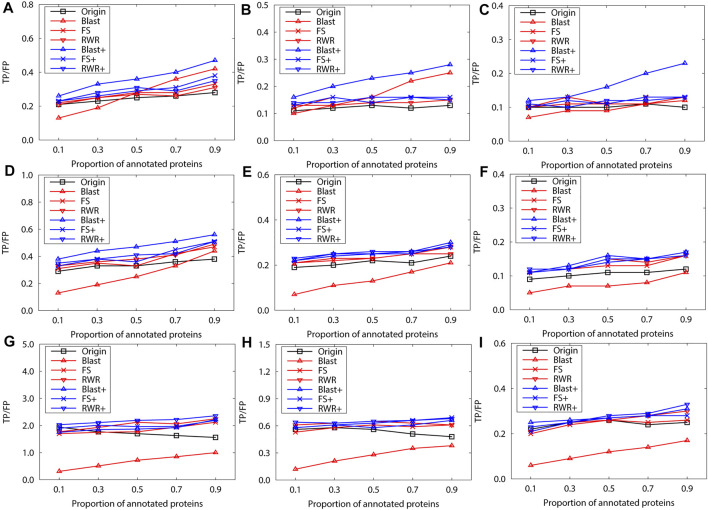
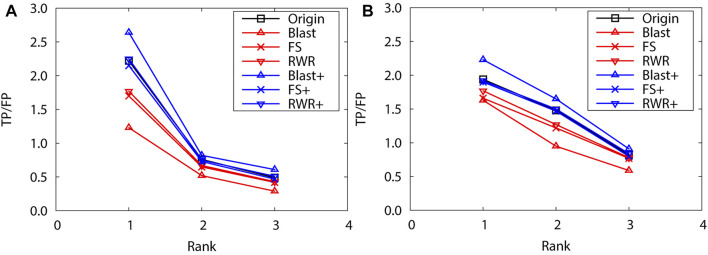
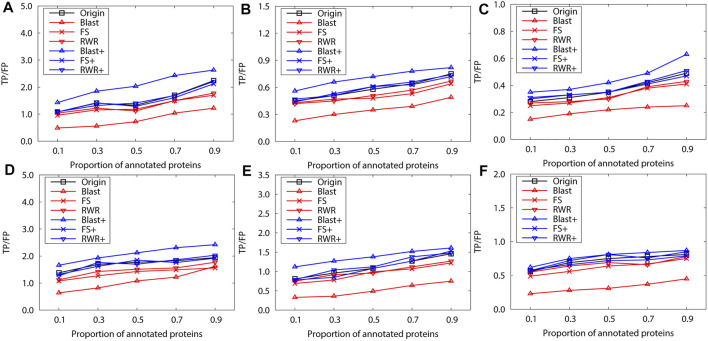
Over the past decades, massive amounts of protein-protein interaction (PPI) data have been accumulated due to the advancement of high-throughput technologies, and but data quality issues (noise or incompleteness) of PPI have been still affecting protein function prediction accuracy based on PPI networks. Although two main strategies of and have been reported on the effectiveness of boosting the prediction performance in numerous literature studies, there still lack comparative studies of the performance differences between and . Inspired by the question, this study first uses three protein similarity metrics (local, global and sequence) for network reconstruction and edge enrichment in PPI networks, and then evaluates the performance differences of network reconstruction, edge enrichment and the original networks on two real PPI datasets. The experimental results demonstrate that edge enrichment work better than both network reconstruction and original networks. Moreover, for the edge enrichment of PPI networks, the sequence similarity outperformes both local and global similarity. In summary, our study can help biologists select suitable pre-processing schemes and achieve better protein function prediction for PPI networks.
在过去几十年中,由于高通量技术的进步,积累了大量蛋白质-蛋白质相互作用(PPI)数据,但是PPI的数据质量问题(噪声或不完整性)仍然影响基于PPI网络的蛋白质功能预测准确性。尽管在众多文献研究中已经报道了两种主要策略在提高预测性能方面的有效性,但是仍然缺乏对这两种策略之间性能差异的比较研究。受此问题启发,本研究首先使用三种蛋白质相似性度量(局部、全局和序列)对PPI网络进行网络重建和边富集,然后在两个真实PPI数据集上评估网络重建、边富集和原始网络的性能差异。实验结果表明,边富集比网络重建和原始网络都表现更好。此外,对于PPI网络的边富集,序列相似性优于局部和全局相似性。总之,我们的研究可以帮助生物学家选择合适的预处理方案,并对PPI网络实现更好的蛋白质功能预测。