Leeuwenberg Artuur M, van Smeden Maarten, Langendijk Johannes A, van der Schaaf Arjen, Mauer Murielle E, Moons Karel G M, Reitsma Johannes B, Schuit Ewoud
Julius Center for Health Sciences and Primary Care, University Medical Center Utrecht, Utrecht University, Utrecht, The Netherlands.
Department of Radiation Oncology, University Medical Center Groningen, Groningen University, Groningen, The Netherlands.
Diagn Progn Res. 2022 Jan 11;6(1):1. doi: 10.1186/s41512-021-00115-5.
Clinical prediction models are developed widely across medical disciplines. When predictors in such models are highly collinear, unexpected or spurious predictor-outcome associations may occur, thereby potentially reducing face-validity of the prediction model. Collinearity can be dealt with by exclusion of collinear predictors, but when there is no a priori motivation (besides collinearity) to include or exclude specific predictors, such an approach is arbitrary and possibly inappropriate.
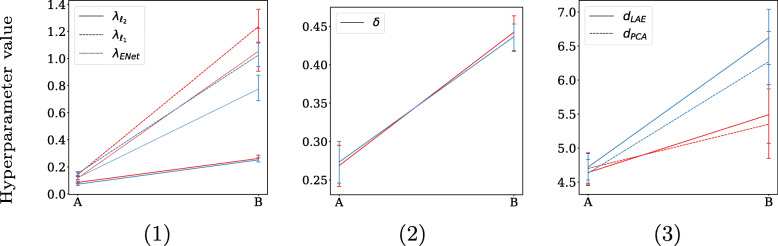
We compare different methods to address collinearity, including shrinkage, dimensionality reduction, and constrained optimization. The effectiveness of these methods is illustrated via simulations.
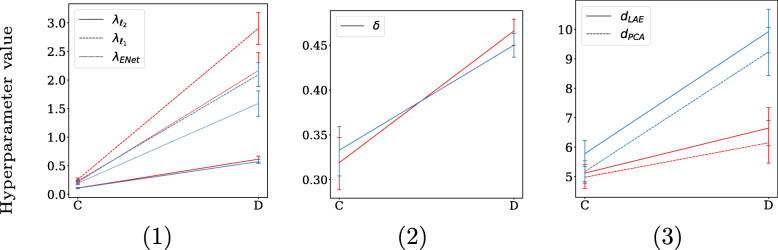
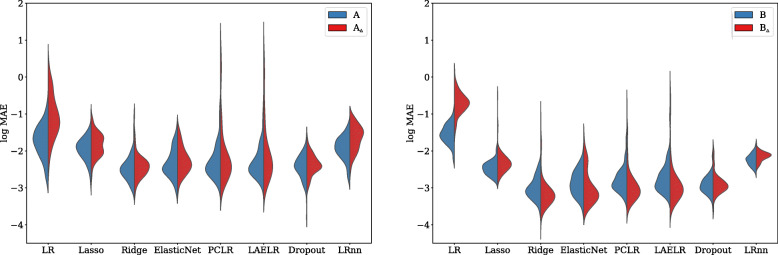
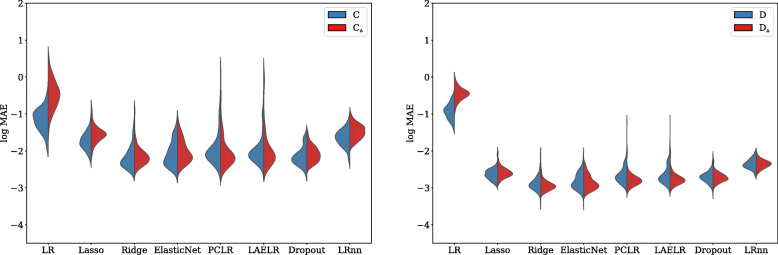
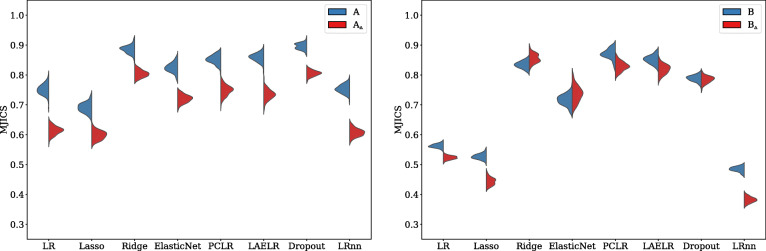
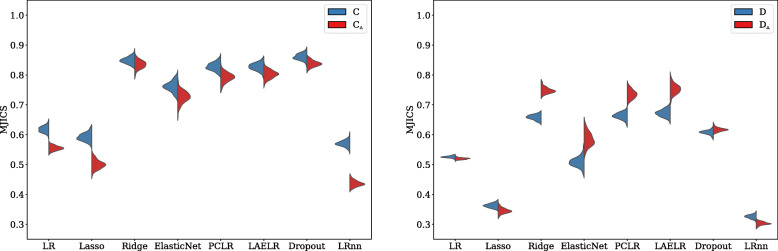
In the conducted simulations, no effect of collinearity was observed on predictive outcomes (AUC, R, Intercept, Slope) across methods. However, a negative effect of collinearity on the stability of predictor selection was found, affecting all compared methods, but in particular methods that perform strong predictor selection (e.g., Lasso). Methods for which the included set of predictors remained most stable under increased collinearity were Ridge, PCLR, LAELR, and Dropout.
Based on the results, we would recommend refraining from data-driven predictor selection approaches in the presence of high collinearity, because of the increased instability of predictor selection, even in relatively high events-per-variable settings. The selection of certain predictors over others may disproportionally give the impression that included predictors have a stronger association with the outcome than excluded predictors.
临床预测模型在各个医学学科中广泛开发。当此类模型中的预测变量高度共线时,可能会出现意外或虚假的预测变量 - 结果关联,从而可能降低预测模型的表面效度。可以通过排除共线预测变量来处理共线性,但当没有先验动机(除共线性外)来纳入或排除特定预测变量时,这种方法是任意的,可能不合适。
我们比较了处理共线性的不同方法,包括收缩、降维和约束优化。通过模拟说明了这些方法的有效性。
在进行的模拟中,未观察到共线性对各方法的预测结果(AUC、R、截距、斜率)有影响。然而,发现共线性对预测变量选择的稳定性有负面影响,影响所有比较的方法,但对执行强预测变量选择的方法(例如套索)影响尤其明显。在共线性增加的情况下,所纳入的预测变量集保持最稳定的方法是岭回归、主成分逻辑回归、局部自适应弹性网回归和随机失活。
基于这些结果,我们建议在存在高共线性的情况下避免使用数据驱动的预测变量选择方法,因为预测变量选择的不稳定性增加,即使在相对较高的每变量事件设置中也是如此。选择某些预测变量而非其他预测变量可能会不成比例地给人一种印象,即纳入的预测变量与结果的关联比排除的预测变量更强。