Artificial Intelligence Laboratory, Vrije Universiteit Brussel, Brussels, 1050, Belgium.
Machine Learning Group, Université Libre de Bruxelles, Brussels, 1050, Belgium.
Sci Rep. 2022 May 9;12(1):7589. doi: 10.1038/s41598-022-11654-2.
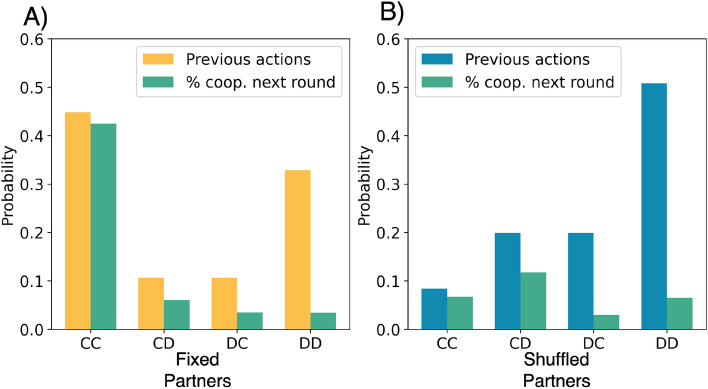
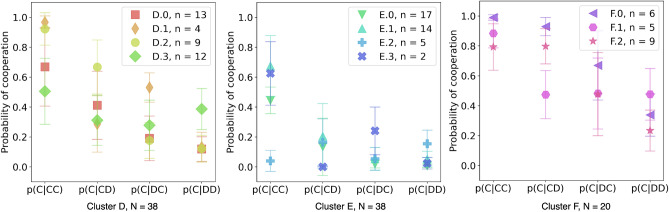
While many theoretical studies have revealed the strategies that could lead to and maintain cooperation in the Iterated Prisoner's dilemma, less is known about what human participants actually do in this game and how strategies change when being confronted with anonymous partners in each round. Previous attempts used short experiments, made different assumptions of possible strategies, and led to very different conclusions. We present here two long treatments that differ in the partner matching strategy used, i.e. fixed or shuffled partners. Here we use unsupervised methods to cluster the players based on their actions and then Hidden Markov Model to infer what the memory-one strategies are in each cluster. Analysis of the inferred strategies reveals that fixed partner interaction leads to behavioral self-organization. Shuffled partners generate subgroups of memory-one strategies that remain entangled, apparently blocking the self-selection process that leads to fully cooperating participants in the fixed partner treatment. Analyzing the latter in more detail shows that AllC, AllD, TFT- and WSLS-like behavior can be observed. This study also reveals that long treatments are needed as experiments with less than 25 rounds capture mostly the learning phase participants go through in these kinds of experiments.
虽然许多理论研究揭示了导致和维持迭代囚徒困境中合作的策略,但对于人类参与者在这个游戏中实际做了什么,以及当面对每轮匿名合作伙伴时策略如何变化,我们知之甚少。之前的尝试使用了短期实验,对可能的策略做出了不同的假设,并得出了非常不同的结论。我们在这里介绍两种不同的长期处理方法,它们在使用的伙伴匹配策略上有所不同,即固定或随机伙伴。在这里,我们使用无监督方法根据参与者的行为对其进行聚类,然后使用隐马尔可夫模型推断每个聚类中的记忆-1 策略是什么。对推断策略的分析表明,固定伙伴的相互作用导致行为的自组织。随机伙伴生成的记忆-1 策略的子组仍然纠缠在一起,显然阻止了导致固定伙伴处理中完全合作参与者的自我选择过程。更详细地分析后者表明,可以观察到 AllC、AllD、TFT 和 WSLS 样行为。这项研究还表明,需要进行长期处理,因为少于 25 轮的实验主要捕捉到了参与者在这类实验中经历的学习阶段。