Barboi Cristina, Tzavelis Andreas, Muhammad Lutfiyya NaQiyba
Indiana University Purdue University, Regenstrief Institue, Indianapolis, IN, United States.
Medical Scientist Training Program, Feinberg School of Medicine, Chicago, IL, United States.
JMIR Med Inform. 2022 May 31;10(5):e35293. doi: 10.2196/35293.
Severity of illness scores-Acute Physiology and Chronic Health Evaluation, Simplified Acute Physiology Score, and Sequential Organ Failure Assessment-are current risk stratification and mortality prediction tools used in intensive care units (ICUs) worldwide. Developers of artificial intelligence or machine learning (ML) models predictive of ICU mortality use the severity of illness scores as a reference point when reporting the performance of these computational constructs.
This study aimed to perform a literature review and meta-analysis of articles that compared binary classification ML models with the severity of illness scores that predict ICU mortality and determine which models have superior performance. This review intends to provide actionable guidance to clinicians on the performance and validity of ML models in supporting clinical decision-making compared with the severity of illness score models.
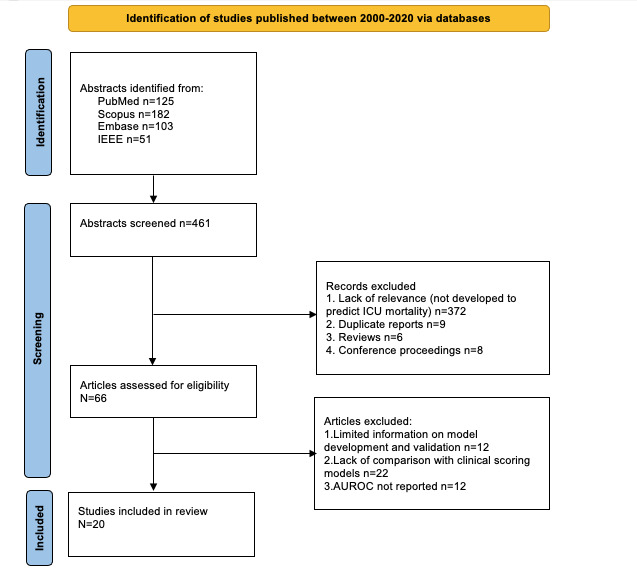
Between December 15 and 18, 2020, we conducted a systematic search of PubMed, Scopus, Embase, and IEEE databases and reviewed studies published between 2000 and 2020 that compared the performance of binary ML models predictive of ICU mortality with the performance of severity of illness score models on the same data sets. We assessed the studies' characteristics, synthesized the results, meta-analyzed the discriminative performance of the ML and severity of illness score models, and performed tests of heterogeneity within and among studies.
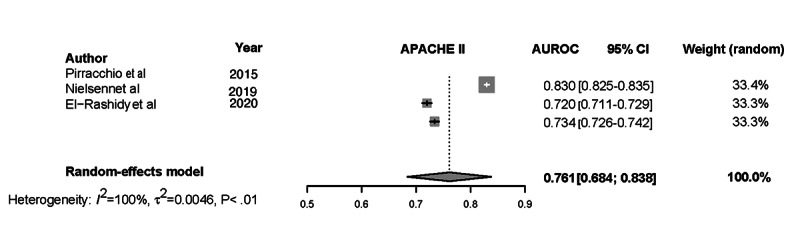
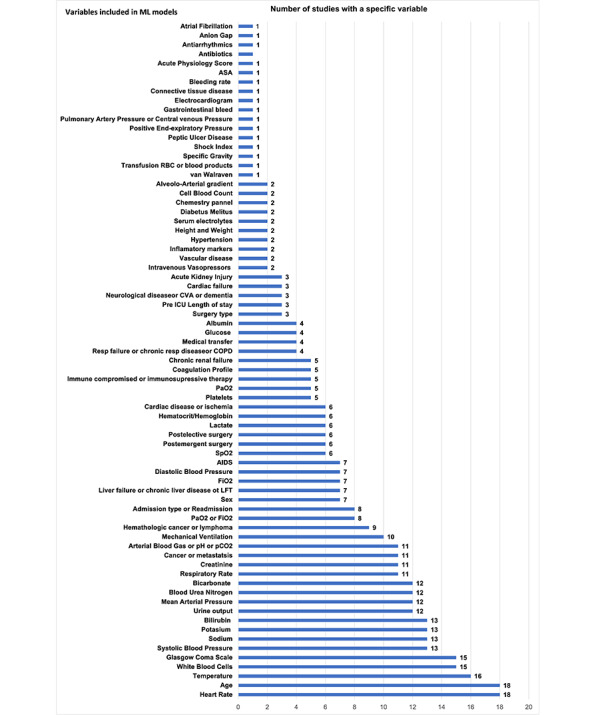
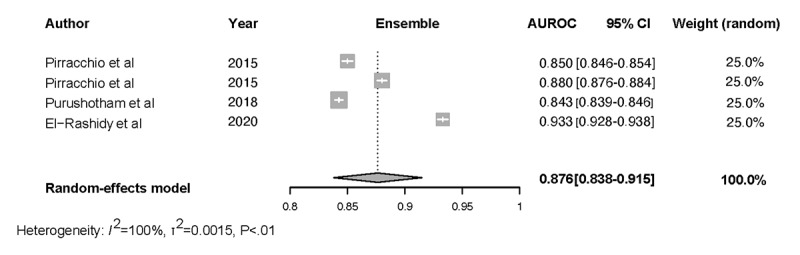
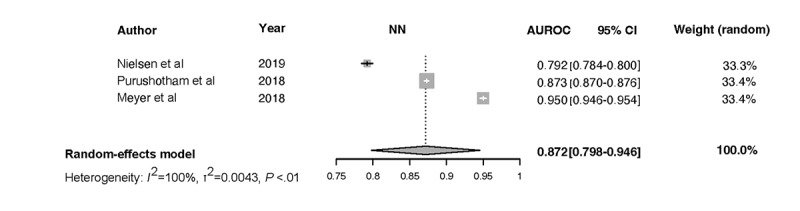
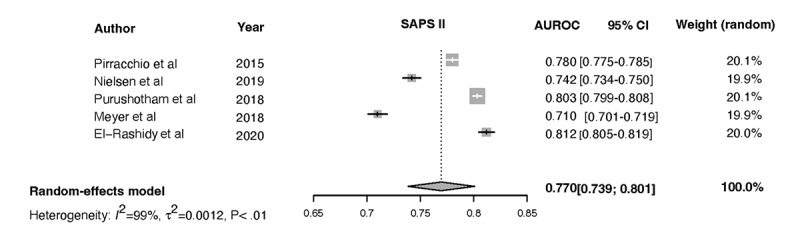
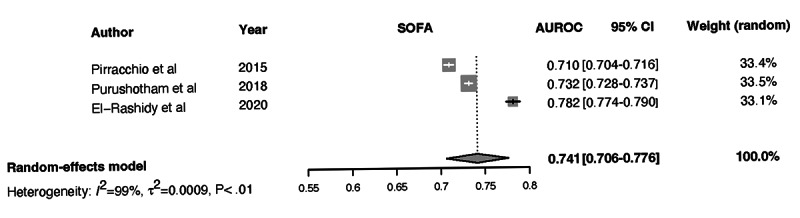
We screened 461 abstracts, of which we assessed the full text of 66 (14.3%) articles. We included in the review 20 (4.3%) studies that developed 47 ML models based on 7 types of algorithms and compared them with 3 types of the severity of illness score models. Of the 20 studies, 4 (20%) were found to have a low risk of bias and applicability in model development, 7 (35%) performed external validation, 9 (45%) reported on calibration, 12 (60%) reported on classification measures, and 4 (20%) addressed explainability. The discriminative performance of the ML-based models, which was reported as AUROC, ranged between 0.728 and 0.99 and between 0.58 and 0.86 for the severity of illness score-based models. We noted substantial heterogeneity among the reported models and considerable variation among the AUROC estimates for both ML and severity of illness score model types.
ML-based models can accurately predict ICU mortality as an alternative to traditional scoring models. Although the range of performance of the ML models is superior to that of the severity of illness score models, the results cannot be generalized due to the high degree of heterogeneity. When presented with the option of choosing between severity of illness score or ML models for decision support, clinicians should select models that have been externally validated, tested in the practice environment, and updated to the patient population and practice environment.
PROSPERO CRD42021203871; https://tinyurl.com/28v2nch8.
疾病严重程度评分——急性生理与慢性健康状况评估、简化急性生理学评分和序贯器官衰竭评估——是目前全球重症监护病房(ICU)中使用的风险分层和死亡率预测工具。预测ICU死亡率的人工智能或机器学习(ML)模型的开发者在报告这些计算结构的性能时,将疾病严重程度评分作为参考点。
本研究旨在对比较二元分类ML模型与预测ICU死亡率的疾病严重程度评分的文章进行文献综述和荟萃分析,并确定哪些模型具有更优的性能。本综述旨在为临床医生提供关于ML模型在支持临床决策方面的性能和有效性的可操作指导,以便与疾病严重程度评分模型进行比较。
在2020年12月15日至18日期间,我们对PubMed、Scopus、Embase和IEEE数据库进行了系统检索,并回顾了2000年至2020年期间发表的研究,这些研究在相同数据集上比较了预测ICU死亡率的二元ML模型与疾病严重程度评分模型的性能。我们评估了研究的特征,综合了结果,对ML模型和疾病严重程度评分模型的判别性能进行了荟萃分析,并对研究内部和研究之间的异质性进行了检验。
我们筛选了461篇摘要,其中评估了66篇(14.3%)文章的全文。我们纳入综述的有20项(4.3%)研究,这些研究基于7种算法开发了47个ML模型,并将它们与3种疾病严重程度评分模型进行了比较。在这20项研究中,发现4项(20%)在模型开发中存在低偏倚风险和适用性,7项(35%)进行了外部验证,9项(45%)报告了校准情况,12项(60%)报告了分类指标,4项(20%)涉及可解释性。基于ML的模型的判别性能(报告为AUROC)在0.728至0.99之间,基于疾病严重程度评分的模型在0.58至0.86之间。我们注意到报告的模型之间存在实质性异质性,并且ML模型和疾病严重程度评分模型类型的AUROC估计值之间存在相当大的差异。
基于ML的模型可以准确预测ICU死亡率,作为传统评分模型的替代方法。尽管ML模型的性能范围优于疾病严重程度评分模型,但由于高度异质性,结果不能一概而论。当在疾病严重程度评分或ML模型之间进行选择以获得决策支持时,临床医生应选择经过外部验证、在实践环境中测试并针对患者群体和实践环境进行更新的模型。
PROSPERO CRD42021203871;https://tinyurl.com/28v2nch8 。