Karimi Davood, Dou Haoran, Gholipour Ali
Department of Radiology, Boston Children's Hospital, Harvard Medical School, Boston, MA 02115, USA.
Centre for Computational Imaging & Simulation Technologies in Biomedicine (CISTIB), School of Computing, University of Leeds, Leeds LS2 9JT, U.K.
IEEE Access. 2022;10:29322-29332. doi: 10.1109/access.2022.3156894. Epub 2022 Mar 4.
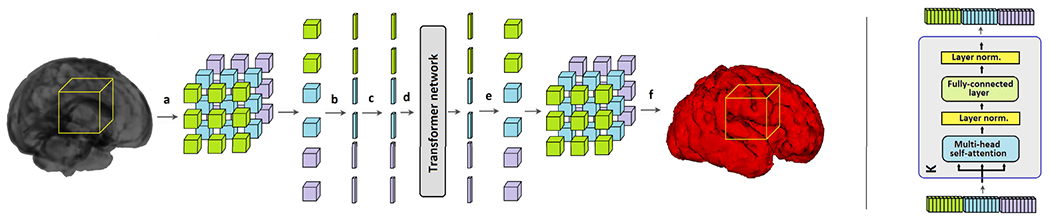
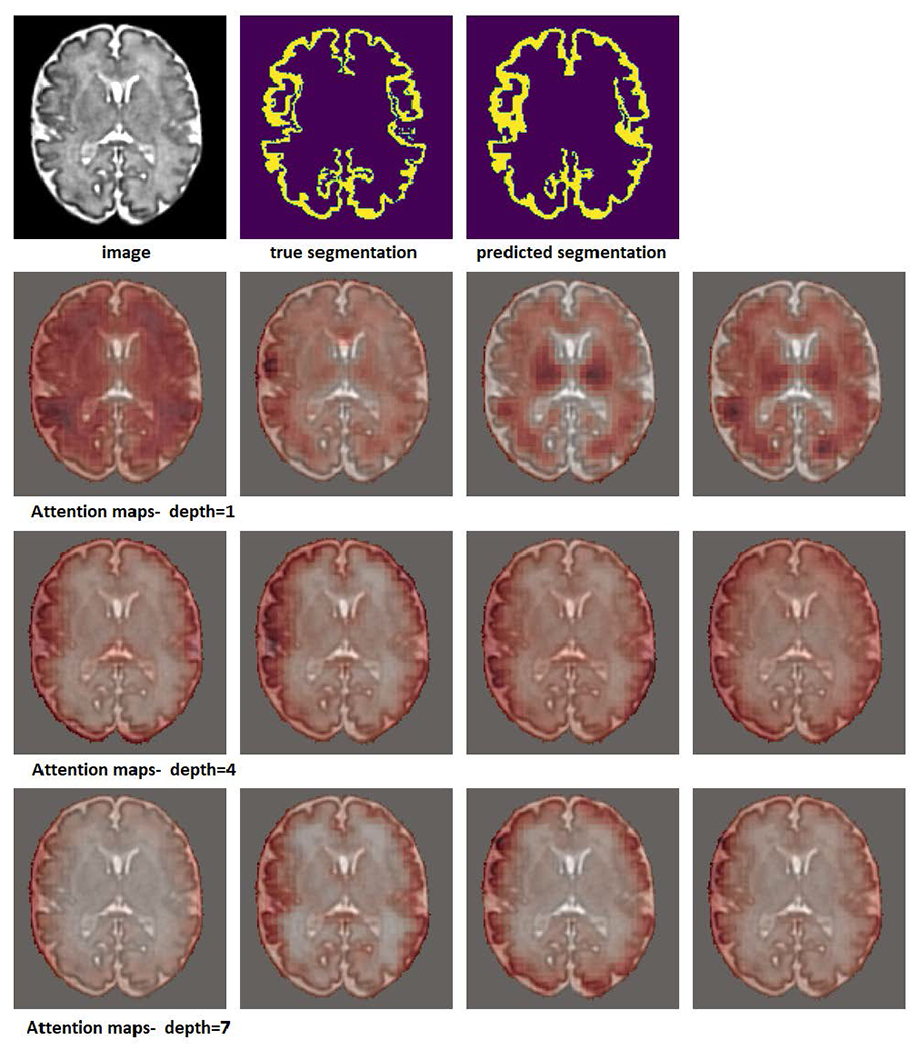
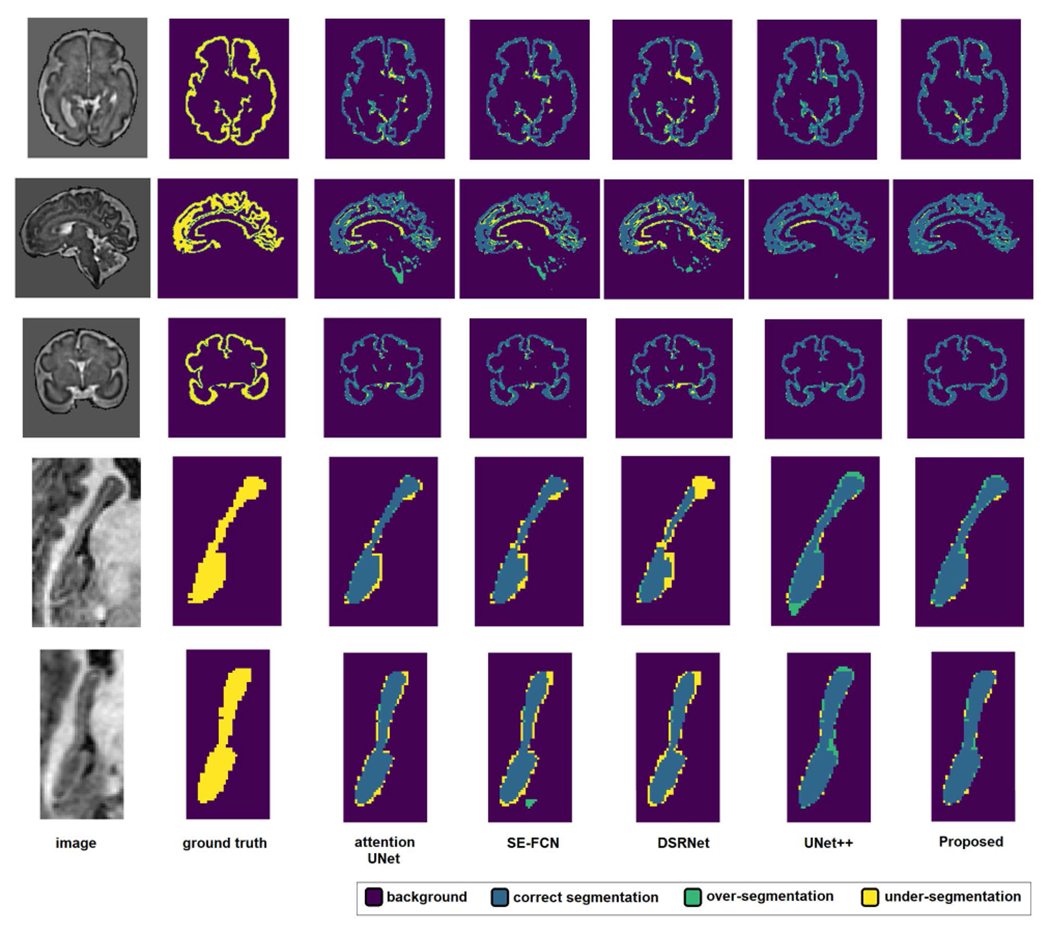
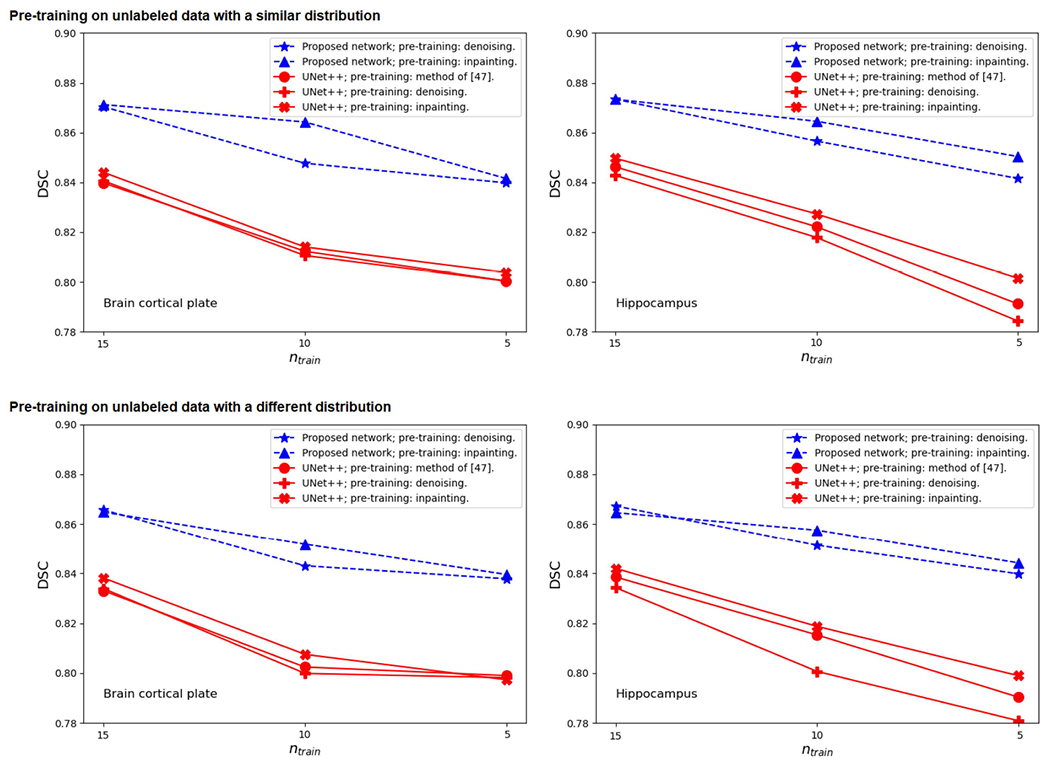
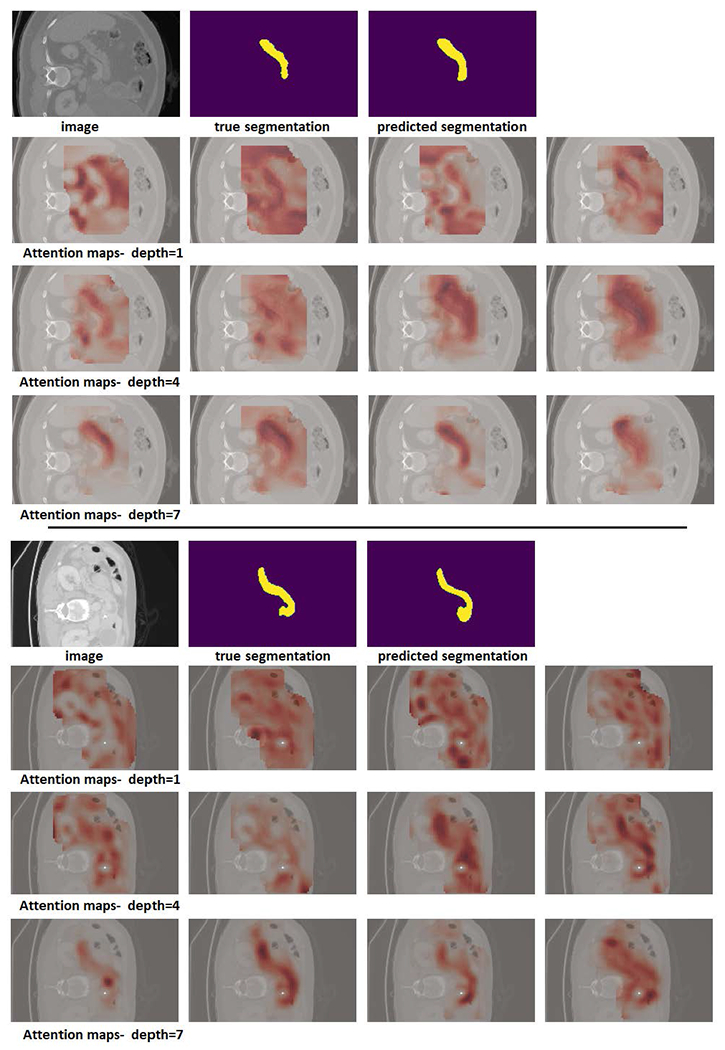
Deep learning models represent the state of the art in medical image segmentation. Most of these models are fully-convolutional networks (FCNs), namely each layer processes the output of the preceding layer with convolution operations. The convolution operation enjoys several important properties such as sparse interactions, parameter sharing, and translation equivariance. Because of these properties, FCNs possess a strong and useful inductive bias for image modeling and analysis. However, they also have certain important shortcomings, such as performing a fixed and pre-determined operation on a test image regardless of its content and difficulty in modeling long-range interactions. In this work we show that a different deep neural network architecture, based entirely on self-attention between neighboring image patches and without any convolution operations, can achieve more accurate segmentations than FCNs. Our proposed model is based directly on the transformer network architecture. Given a 3D image block, our network divides it into non-overlapping 3D patches and computes a 1D embedding for each patch. The network predicts the segmentation map for the block based on the self-attention between these patch embeddings. Furthermore, in order to address the common problem of scarcity of labeled medical images, we propose methods for pre-training this model on large corpora of unlabeled images. Our experiments show that the proposed model can achieve segmentation accuracies that are better than several state of the art FCN architectures on two datasets. Our proposed network can be trained using only tens of labeled images. Moreover, with the proposed pre-training strategies, our network outperforms FCNs when labeled training data is small.
深度学习模型代表了医学图像分割的当前技术水平。这些模型大多是全卷积网络(FCN),即每一层都通过卷积操作处理前一层的输出。卷积操作具有几个重要特性,如稀疏交互、参数共享和平移不变性。由于这些特性,FCN在图像建模和分析方面具有强大且有用的归纳偏差。然而,它们也有一些重要缺点,比如无论测试图像的内容和难度如何,都对其执行固定且预先确定的操作,以及在对长距离交互进行建模时存在困难。在这项工作中,我们表明一种完全基于相邻图像块之间的自注意力且没有任何卷积操作的不同深度神经网络架构,能够比FCN实现更准确的分割。我们提出的模型直接基于Transformer网络架构。给定一个3D图像块,我们的网络将其划分为不重叠的3D块,并为每个块计算一个1D嵌入。网络基于这些块嵌入之间的自注意力预测该块的分割图。此外,为了解决标记医学图像稀缺的常见问题,我们提出了在大量未标记图像语料库上对该模型进行预训练的方法。我们的实验表明,所提出的模型在两个数据集上能够实现优于几种当前技术水平的FCN架构的分割精度。我们提出的网络仅使用几十张标记图像就可以进行训练。此外,通过所提出的预训练策略,当标记训练数据较少时,我们的网络优于FCN。