Ko Yu-Chieh, Chen Wei-Shiang, Chen Hung-Hsun, Hsu Tsui-Kang, Chen Ying-Chi, Liu Catherine Jui-Ling, Lu Henry Horng-Shing
Department of Ophthalmology, Taipei Veterans General Hospital, 201 Sec. 2, Shihpai Rd., Taipei 11217, Taiwan.
Faculty of Medicine, National Yang Ming Chiao Tung University School of Medicine, 155 Sec. 2, Linong St., Taipei 11221, Taiwan.
Biomedicines. 2022 Jun 3;10(6):1314. doi: 10.3390/biomedicines10061314.
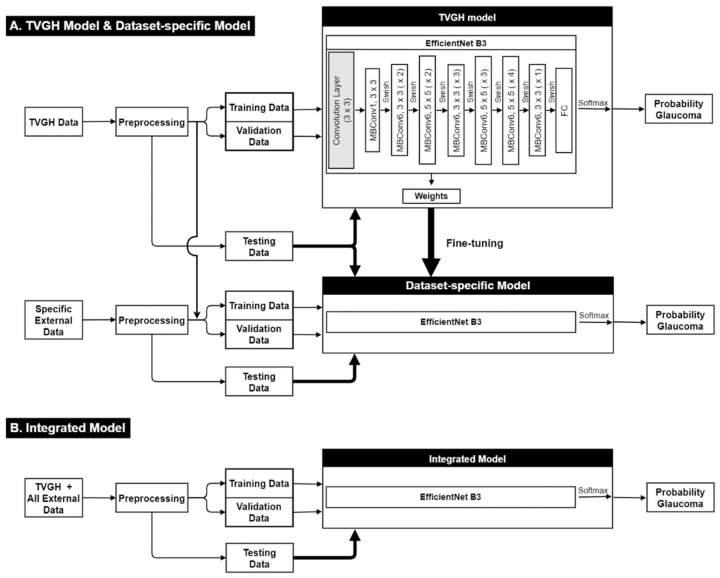
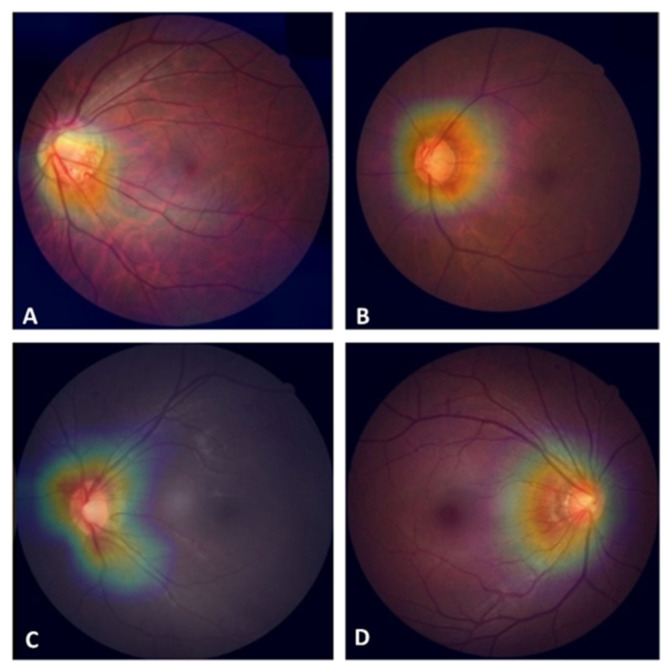
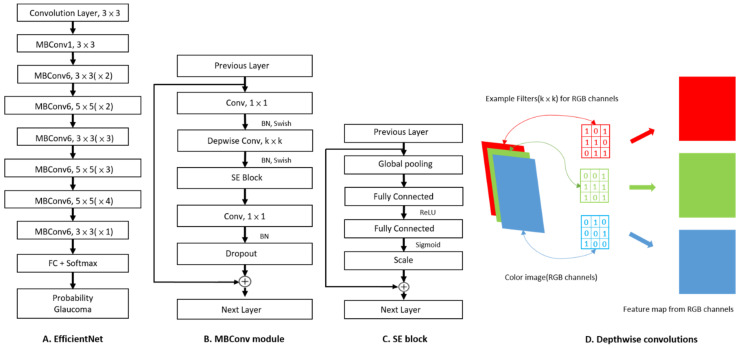
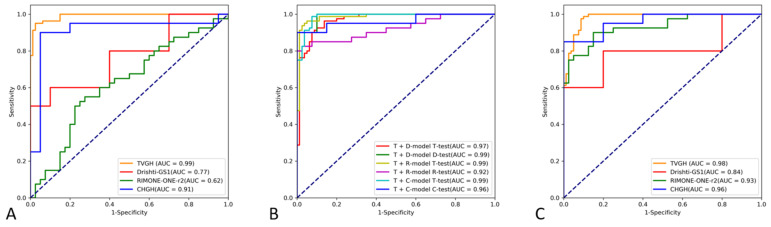
Automated glaucoma detection using deep learning may increase the diagnostic rate of glaucoma to prevent blindness, but generalizable models are currently unavailable despite the use of huge training datasets. This study aims to evaluate the performance of a convolutional neural network (CNN) classifier trained with a limited number of high-quality fundus images in detecting glaucoma and methods to improve its performance across different datasets. A CNN classifier was constructed using EfficientNet B3 and 944 images collected from one medical center (core model) and externally validated using three datasets. The performance of the core model was compared with (1) the integrated model constructed by using all training images from the four datasets and (2) the dataset-specific model built by fine-tuning the core model with training images from the external datasets. The diagnostic accuracy of the core model was 95.62% but dropped to ranges of 52.5-80.0% on the external datasets. Dataset-specific models exhibited superior diagnostic performance on the external datasets compared to other models, with a diagnostic accuracy of 87.50-92.5%. The findings suggest that dataset-specific tuning of the core CNN classifier effectively improves its applicability across different datasets when increasing training images fails to achieve generalization.
使用深度学习进行青光眼自动检测可能会提高青光眼的诊断率以预防失明,但尽管使用了大量训练数据集,目前仍没有可推广的模型。本研究旨在评估使用有限数量的高质量眼底图像训练的卷积神经网络(CNN)分类器在检测青光眼方面的性能,以及在不同数据集上提高其性能的方法。使用EfficientNet B3和从一个医疗中心收集的944张图像构建了一个CNN分类器(核心模型),并使用三个数据集进行外部验证。将核心模型的性能与(1)使用来自四个数据集的所有训练图像构建的集成模型,以及(2)通过使用来自外部数据集的训练图像对核心模型进行微调而构建的特定数据集模型进行比较。核心模型的诊断准确率为95.62%,但在外部数据集上降至52.5 - 80.0%的范围。与其他模型相比,特定数据集模型在外部数据集上表现出卓越的诊断性能,诊断准确率为87.50 - 92.5%。研究结果表明,当增加训练图像无法实现泛化时,对核心CNN分类器进行特定数据集的调整可有效提高其在不同数据集上的适用性。