Schwarz Julia, Li Katrina Kechun, Sim Jasper Hong, Zhang Yixin, Buchanan-Worster Elizabeth, Post Brechtje, Gibson Jenny Louise, McDougall Kirsty
Faculty of Modern and Medieval Languages and Linguistics, University of Cambridge, Cambridge, United Kingdom.
Medical Research Council Cognition and Brain Sciences Unit, University of Cambridge, Cambridge, United Kingdom.
Front Psychol. 2022 Jul 19;13:879156. doi: 10.3389/fpsyg.2022.879156. eCollection 2022.
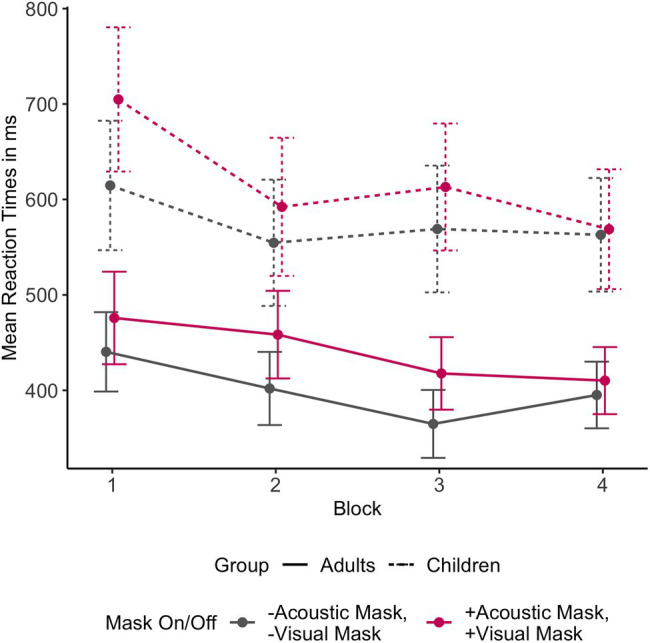
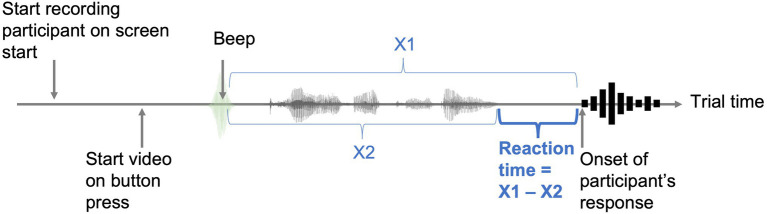
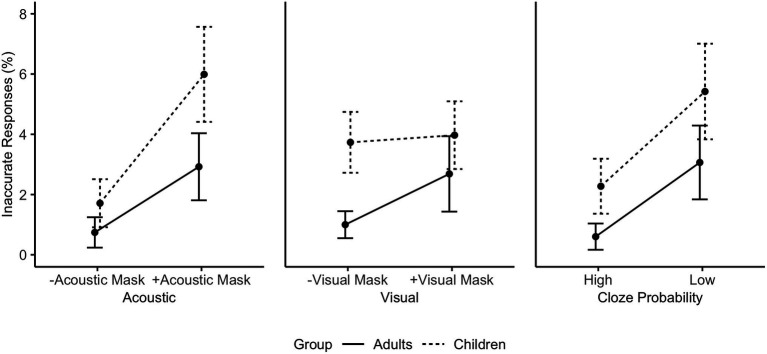
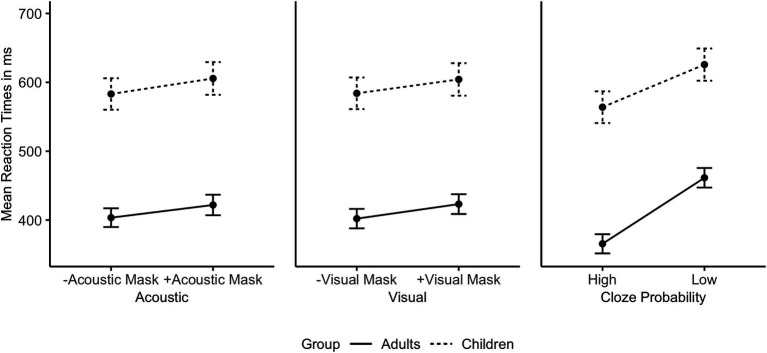
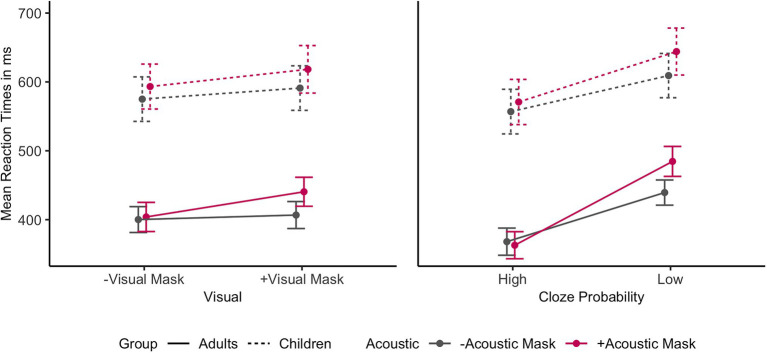
During the COVID-19 pandemic, questions have been raised about the impact of face masks on communication in classroom settings. However, it is unclear to what extent visual obstruction of the speaker's mouth or changes to the acoustic signal lead to speech processing difficulties, and whether these effects can be mitigated by semantic predictability, i.e., the availability of contextual information. The present study investigated the acoustic and visual effects of face masks on speech intelligibility and processing speed under varying semantic predictability. Twenty-six children (aged 8-12) and twenty-six adults performed an internet-based cued shadowing task, in which they had to repeat aloud the last word of sentences presented in audio-visual format. The results showed that children and adults made more mistakes and responded more slowly when listening to face mask speech compared to speech produced without a face mask. Adults were only significantly affected by face mask speech when both the acoustic and the visual signal were degraded. While acoustic mask effects were similar for children, removal of visual speech cues through the face mask affected children to a lesser degree. However, high semantic predictability reduced audio-visual mask effects, leading to full compensation of the acoustically degraded mask speech in the adult group. Even though children did not fully compensate for face mask speech with high semantic predictability, overall, they still profited from semantic cues in all conditions. Therefore, in classroom settings, strategies that increase contextual information such as building on students' prior knowledge, using keywords, and providing visual aids, are likely to help overcome any adverse face mask effects.
在新冠疫情期间,人们对口罩对课堂交流的影响提出了疑问。然而,尚不清楚说话者嘴巴的视觉遮挡或声学信号的变化在多大程度上会导致语音处理困难,以及这些影响是否可以通过语义可预测性(即上下文信息的可用性)得到缓解。本研究调查了在不同语义可预测性下口罩对语音清晰度和处理速度的声学和视觉影响。26名儿童(8至12岁)和26名成年人完成了一项基于网络的提示跟读任务,他们必须大声重复以视听形式呈现的句子的最后一个单词。结果表明,与不戴口罩说话相比,儿童和成年人在听戴口罩讲话时犯错更多,反应更慢。只有在声学和视觉信号都退化时,成年人才会受到口罩讲话的显著影响。虽然儿童的声学口罩效应相似,但通过口罩去除视觉语音线索对儿童的影响较小。然而,高语义可预测性降低了视听口罩效应,使成年组中声学退化的口罩讲话得到了完全补偿。尽管儿童在高语义可预测性下没有完全补偿口罩讲话的影响,但总体而言,他们在所有情况下仍然从语义线索中受益。因此,在课堂环境中,增加上下文信息的策略,如基于学生的先验知识、使用关键词和提供视觉辅助工具,可能有助于克服口罩带来的任何不利影响。