Kiser Amber C, Eilbeck Karen, Ferraro Jeffrey P, Skarda David E, Samore Matthew H, Bucher Brian
Department of Biomedical Informatics, School of Medicine, University of Utah, Salt Lake City, UT, United States.
Department of Medicine, School of Medicine, University of Utah, Salt Lake City, UT, United States.
JMIR Med Inform. 2022 Aug 30;10(8):e39057. doi: 10.2196/39057.
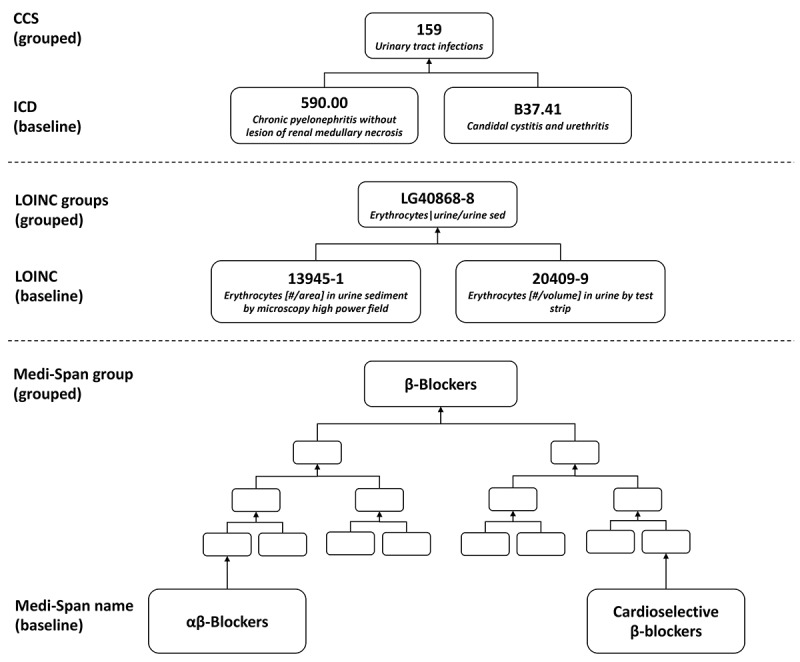
With the widespread adoption of electronic healthcare records (EHRs) by US hospitals, there is an opportunity to leverage this data for the development of predictive algorithms to improve clinical care. A key barrier in model development and implementation includes the external validation of model discrimination, which is rare and often results in worse performance. One reason why machine learning models are not externally generalizable is data heterogeneity. A potential solution to address the substantial data heterogeneity between health care systems is to use standard vocabularies to map EHR data elements. The advantage of these vocabularies is a hierarchical relationship between elements, which allows the aggregation of specific clinical features to more general grouped concepts.
This study aimed to evaluate grouping EHR data using standard vocabularies to improve the transferability of machine learning models for the detection of postoperative health care-associated infections across institutions with different EHR systems.
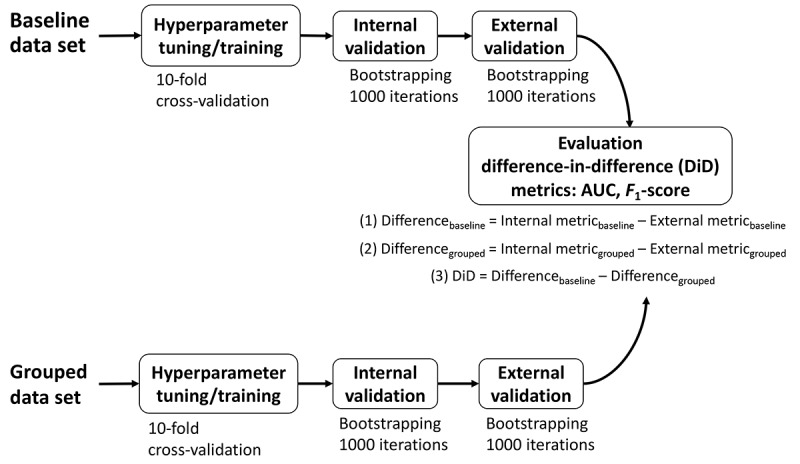
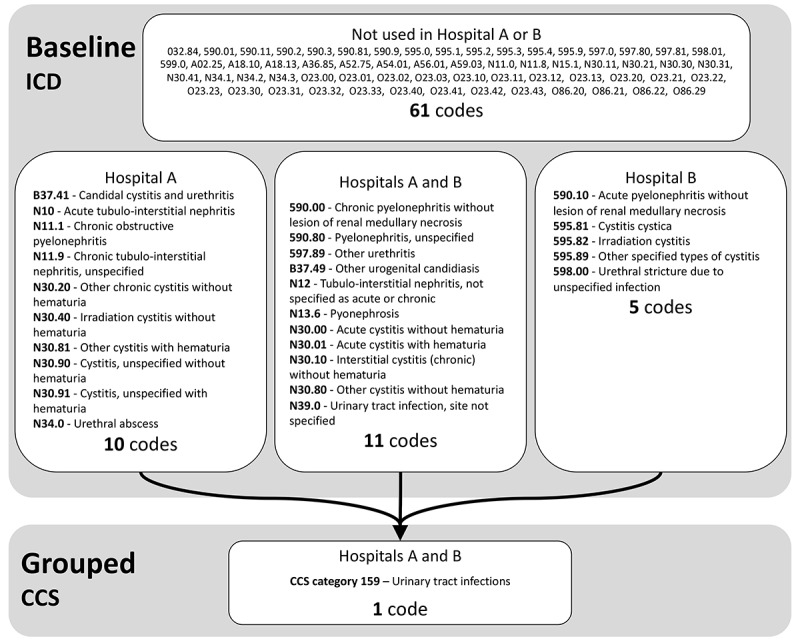
Patients who underwent surgery from the University of Utah Health and Intermountain Healthcare from July 2014 to August 2017 with complete follow-up data were included. The primary outcome was a health care-associated infection within 30 days of the procedure. EHR data from 0-30 days after the operation were mapped to standard vocabularies and grouped using the hierarchical relationships of the vocabularies. Model performance was measured using the area under the receiver operating characteristic curve (AUC) and F-score in internal and external validations. To evaluate model transferability, a difference-in-difference metric was defined as the difference in performance drop between internal and external validations for the baseline and grouped models.
A total of 5775 patients from the University of Utah and 15,434 patients from Intermountain Healthcare were included. The prevalence of selected outcomes was from 4.9% (761/15,434) to 5% (291/5775) for surgical site infections, from 0.8% (44/5775) to 1.1% (171/15,434) for pneumonia, from 2.6% (400/15,434) to 3% (175/5775) for sepsis, and from 0.8% (125/15,434) to 0.9% (50/5775) for urinary tract infections. In all outcomes, the grouping of data using standard vocabularies resulted in a reduced drop in AUC and F-score in external validation compared to baseline features (all P<.001, except urinary tract infection AUC: P=.002). The difference-in-difference metrics ranged from 0.005 to 0.248 for AUC and from 0.075 to 0.216 for F-score.
We demonstrated that grouping machine learning model features based on standard vocabularies improved model transferability between data sets across 2 institutions. Improving model transferability using standard vocabularies has the potential to improve the generalization of clinical prediction models across the health care system.
随着美国医院广泛采用电子健康记录(EHRs),利用这些数据开发预测算法以改善临床护理成为可能。模型开发和实施中的一个关键障碍包括模型区分度的外部验证,这种验证很少见,且往往导致性能更差。机器学习模型无法进行外部泛化的一个原因是数据异质性。解决医疗系统间大量数据异质性的一个潜在解决方案是使用标准词汇表来映射EHR数据元素。这些词汇表的优势在于元素之间的层次关系,这使得特定临床特征能够聚合为更通用的分组概念。
本研究旨在评估使用标准词汇表对EHR数据进行分组,以提高机器学习模型在不同EHR系统的机构间检测术后医疗相关感染的可转移性。
纳入2014年7月至2017年8月在犹他大学健康中心和山间医疗保健机构接受手术且有完整随访数据的患者。主要结局是术后30天内发生的医疗相关感染。术后0至30天的EHR数据被映射到标准词汇表,并利用词汇表的层次关系进行分组。在内部和外部验证中,使用受试者操作特征曲线下面积(AUC)和F值来衡量模型性能。为评估模型的可转移性,定义了一个差异度量指标,即基线模型和分组模型在内部和外部验证中性能下降的差异。
共纳入来自犹他大学的5775例患者和来自山间医疗保健机构的15434例患者。选定结局的患病率如下:手术部位感染为4.9%(761/15434)至5%(291/5775),肺炎为0.8%(44/5775)至1.1%(171/15434),脓毒症为2.6%(400/15434)至3%(175/5775),尿路感染为0.8%(125/15434)至0.9%(50/5775)。在所有结局中,与基线特征相比,使用标准词汇表对数据进行分组导致外部验证中AUC和F值的下降减少(除尿路感染AUC:P = 0.002外,所有P < 0.001)。AUC的差异度量指标范围为0.005至0.248,F值的差异度量指标范围为0.075至0.216。
我们证明了基于标准词汇表对机器学习模型特征进行分组可提高两个机构数据集之间的模型可转移性。使用标准词汇表提高模型可转移性有可能改善临床预测模型在整个医疗系统中的泛化能力。