Department of Statistics, Uppsala University, Sweden and Institute for Evaluation of Labour Market and Education Policy, IFAU, Uppsala, Sweden.
Centre for Pharmacoepidemiology, Department of Medicine Solna, Karolinska Institutet, Stockholm, Sweden.
Biom J. 2023 Feb;65(2):e2100118. doi: 10.1002/bimj.202100118. Epub 2022 Aug 31.
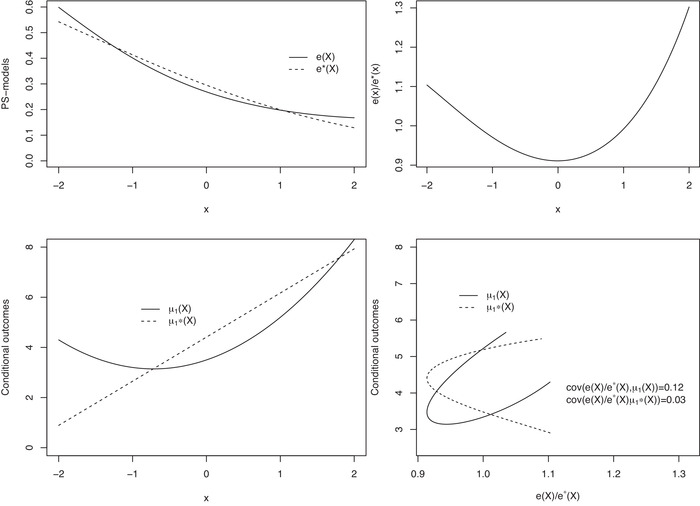
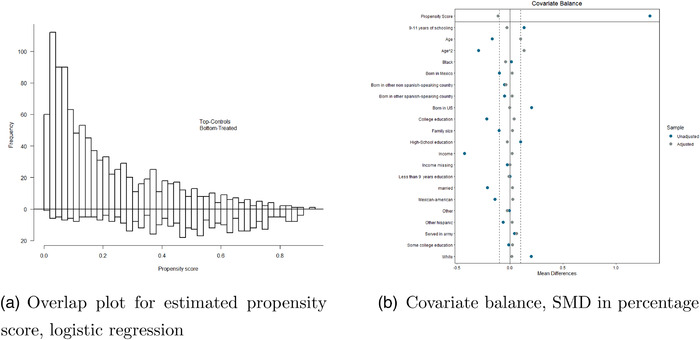
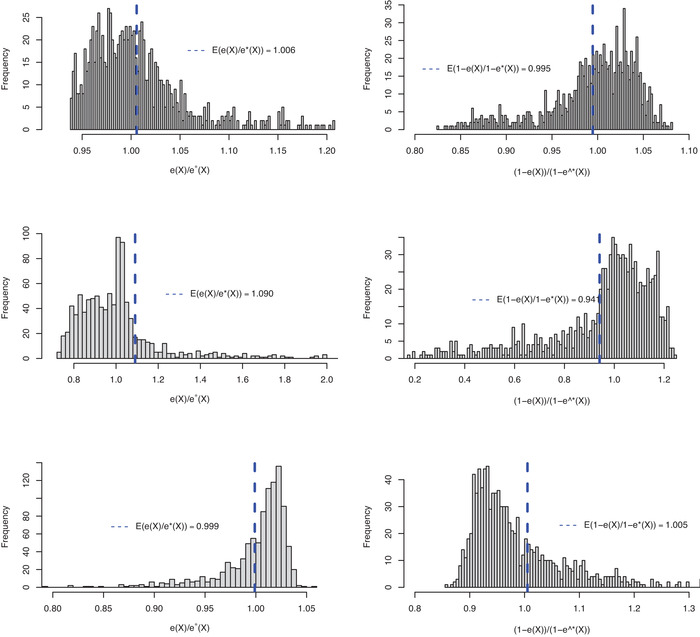
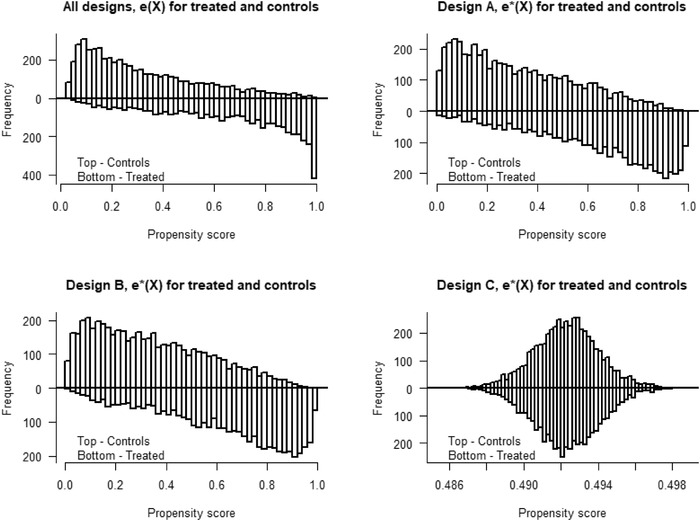
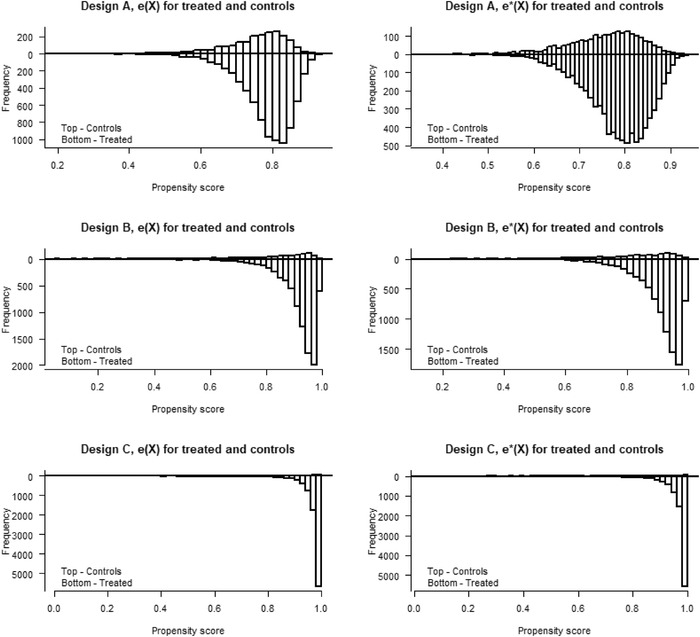
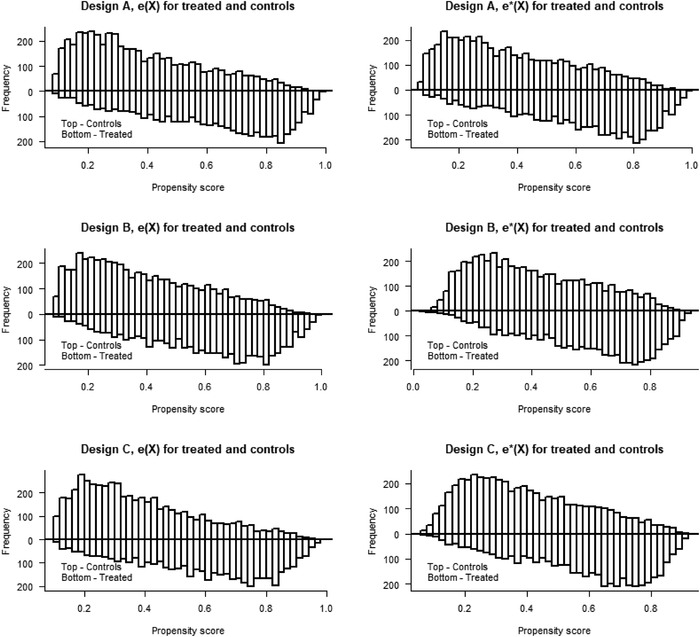
Commonly used semiparametric estimators of causal effects specify parametric models for the propensity score (PS) and the conditional outcome. An example is an augmented inverse probability weighting (IPW) estimator, frequently referred to as a doubly robust estimator, because it is consistent if at least one of the two models is correctly specified. However, in many observational studies, the role of the parametric models is often not to provide a representation of the data-generating process but rather to facilitate the adjustment for confounding, making the assumption of at least one true model unlikely to hold. In this paper, we propose a crude analytical approach to study the large-sample bias of estimators when the models are assumed to be approximations of the data-generating process, namely, when all models are misspecified. We apply our approach to three prototypical estimators of the average causal effect, two IPW estimators, using a misspecified PS model, and an augmented IPW (AIPW) estimator, using misspecified models for the outcome regression (OR) and the PS. For the two IPW estimators, we show that normalization, in addition to having a smaller variance, also offers some protection against bias due to model misspecification. To analyze the question of when the use of two misspecified models is better than one we derive necessary and sufficient conditions for when the AIPW estimator has a smaller bias than a simple IPW estimator and when it has a smaller bias than an IPW estimator with normalized weights. If the misspecification of the outcome model is moderate, the comparisons of the biases of the IPW and AIPW estimators show that the AIPW estimator has a smaller bias than the IPW estimators. However, all biases include a scaling with the PS-model error and we suggest caution in modeling the PS whenever such a model is involved. For numerical and finite sample illustrations, we include three simulation studies and corresponding approximations of the large-sample biases. In a dataset from the National Health and Nutrition Examination Survey, we estimate the effect of smoking on blood lead levels.
常用的因果效应半参数估计量指定倾向评分 (PS) 和条件结果的参数模型。例如,增强逆概率加权 (IPW) 估计量,通常称为双重稳健估计量,因为如果至少有一个模型正确指定,它就是一致的。然而,在许多观察性研究中,参数模型的作用通常不是提供数据生成过程的表示,而是促进混杂因素的调整,使得至少有一个真实模型的假设不太可能成立。在本文中,我们提出了一种粗略的分析方法来研究当模型被假设为数据生成过程的近似时(即所有模型都被误定时)估计量的大样本偏差。我们将我们的方法应用于三个原型平均因果效应估计量,两个 IPW 估计量,使用错误指定的 PS 模型,以及一个增强的 IPW (AIPW) 估计量,使用错误指定的结果回归 (OR) 和 PS 模型。对于两个 IPW 估计量,我们表明归一化除了具有较小的方差外,还提供了一些保护,以防止由于模型误定导致的偏差。为了分析使用两个错误指定的模型是否比一个更好的问题,我们推导出了当 AIPW 估计量的偏差小于简单 IPW 估计量的偏差以及当它的偏差小于具有归一化权重的 IPW 估计量的偏差时的必要和充分条件。如果结果模型的误定程度适中,则 IPW 和 AIPW 估计量的偏差比较表明,AIPW 估计量的偏差小于 IPW 估计量。然而,所有偏差都包括与 PS 模型误差的缩放,并且我们建议在涉及此类模型时谨慎建模 PS。为了进行数值和有限样本说明,我们包括了三个模拟研究和大样本偏差的相应近似值。在国家健康和营养检查调查的一个数据集上,我们估计了吸烟对血液铅水平的影响。