Liu Songbo, Cui Chengmin, Chen Huipeng, Liu Tong
School of Computer Science and Technology, Harbin Institute of Technology, Harbin, China.
Beijing Institute of Control Engineering, China Academy of Space Technology, Beijing, China.
Front Genet. 2022 Oct 21;13:984068. doi: 10.3389/fgene.2022.984068. eCollection 2022.
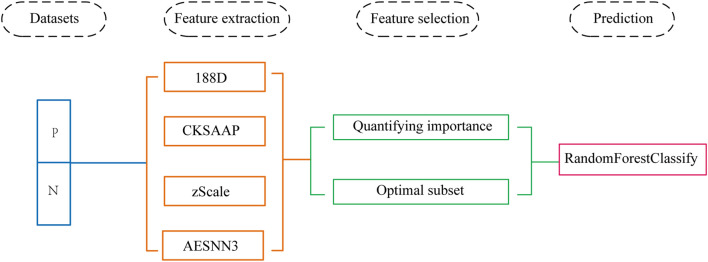
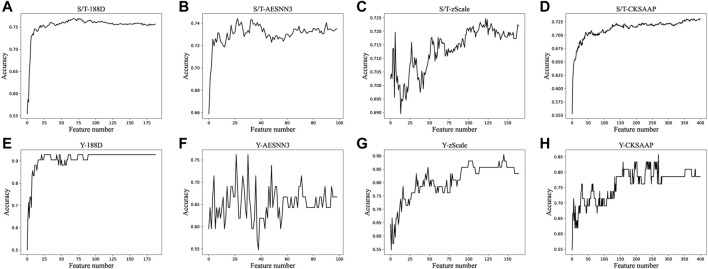
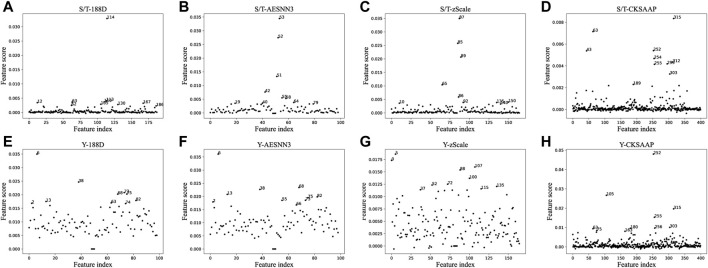
SARS-COV-2 is prevalent all over the world, causing more than six million deaths and seriously affecting human health. At present, there is no specific drug against SARS-COV-2. Protein phosphorylation is an important way to understand the mechanism of SARS -COV-2 infection. It is often expensive and time-consuming to identify phosphorylation sites with specific modified residues through experiments. A method that uses machine learning to make predictions about them is proposed. As all the methods of extracting protein sequence features are knowledge-driven, these features may not be effective for detecting phosphorylation sites without a complete understanding of the mechanism of protein. Moreover, redundant features also have a great impact on the fitting degree of the model. To solve these problems, we propose a feature selection method based on ensemble learning, which firstly extracts protein sequence features based on knowledge, then quantifies the importance score of each feature based on data, and finally uses the subset of important features as the final features to predict phosphorylation sites.
严重急性呼吸综合征冠状病毒2(SARS-CoV-2)在全球广泛传播,已导致超过600万人死亡,严重影响人类健康。目前,尚无针对SARS-CoV-2的特效药物。蛋白质磷酸化是了解SARS-CoV-2感染机制的重要途径。通过实验鉴定具有特定修饰残基的磷酸化位点通常既昂贵又耗时。为此提出了一种利用机器学习对其进行预测的方法。由于所有提取蛋白质序列特征的方法都是知识驱动的,在没有完全理解蛋白质机制的情况下,这些特征可能对检测磷酸化位点无效。此外,冗余特征对模型的拟合度也有很大影响。为了解决这些问题,我们提出了一种基于集成学习的特征选择方法,该方法首先基于知识提取蛋白质序列特征,然后基于数据量化每个特征的重要性得分,最后使用重要特征的子集作为最终特征来预测磷酸化位点。