Taylan Osman, Alkabaa Abdulaziz S, Alqabbaa Hanan S, Pamukçu Esra, Leiva Víctor
Department of Industrial Engineering, Faculty of Engineering, King Abdulaziz University, Jeddah 21589, Saudi Arabia.
University Medical Services Center, King Abdulaziz University, Jeddah 21589, Saudi Arabia.
Biology (Basel). 2023 Jan 11;12(1):117. doi: 10.3390/biology12010117.
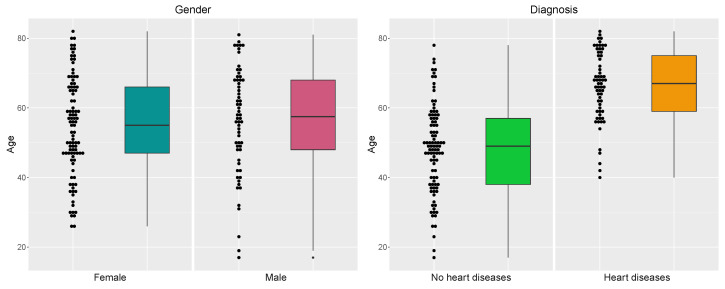
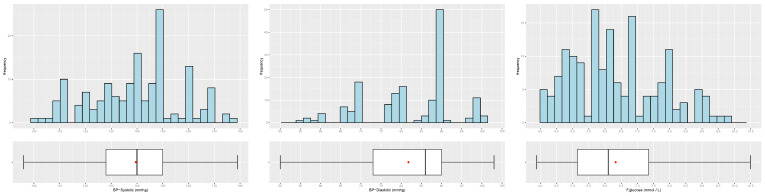
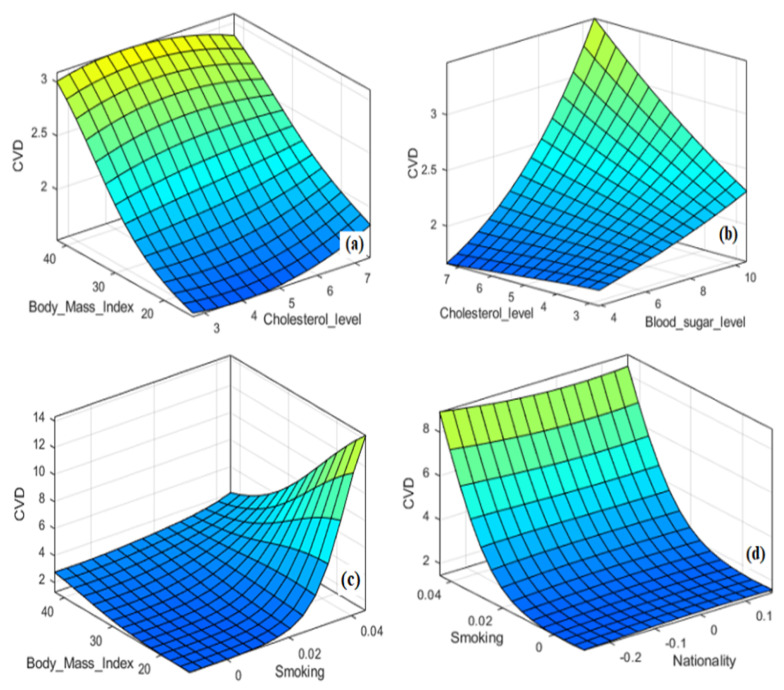
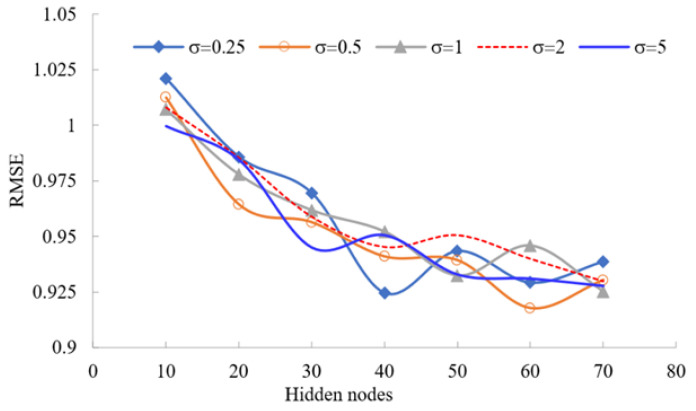
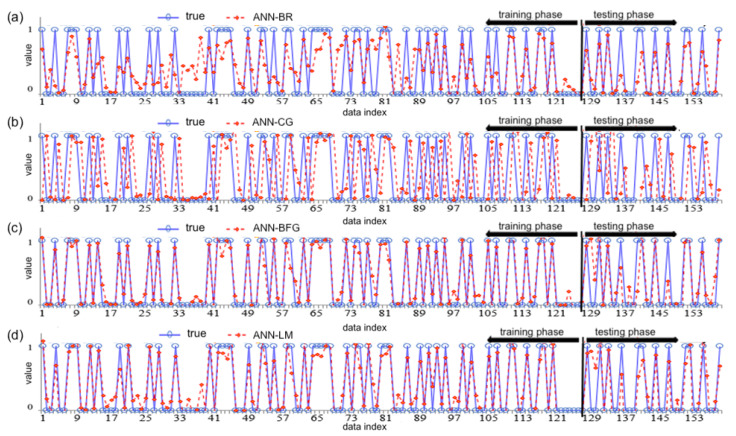
Timely and accurate detection of cardiovascular diseases (CVDs) is critically important to minimize the risk of a myocardial infarction. Relations between factors of CVDs are complex, ill-defined and nonlinear, justifying the use of artificial intelligence tools. These tools aid in predicting and classifying CVDs. In this article, we propose a methodology using machine learning (ML) approaches to predict, classify and improve the diagnostic accuracy of CVDs, including support vector regression (SVR), multivariate adaptive regression splines, the M5Tree model and neural networks for the training process. Moreover, adaptive neuro-fuzzy and statistical approaches, nearest neighbor/naive Bayes classifiers and adaptive neuro-fuzzy inference system (ANFIS) are used to predict seventeen CVD risk factors. Mixed-data transformation and classification methods are employed for categorical and continuous variables predicting CVD risk. We compare our hybrid models and existing ML techniques on a CVD real dataset collected from a hospital. A sensitivity analysis is performed to determine the influence and exhibit the essential variables with regard to CVDs, such as the patient's age, cholesterol level and glucose level. Our results report that the proposed methodology outperformed well known statistical and ML approaches, showing their versatility and utility in CVD classification. Our investigation indicates that the prediction accuracy of ANFIS for the training process is 96.56%, followed by SVR with 91.95% prediction accuracy. Our study includes a comprehensive comparison of results obtained for the mentioned methods.
及时准确地检测心血管疾病(CVD)对于将心肌梗死风险降至最低至关重要。心血管疾病各因素之间的关系复杂、不明确且呈非线性,这使得人工智能工具的使用具有合理性。这些工具有助于预测和分类心血管疾病。在本文中,我们提出一种使用机器学习(ML)方法来预测、分类并提高心血管疾病诊断准确性的方法,包括在训练过程中使用支持向量回归(SVR)、多元自适应回归样条、M5树模型和神经网络。此外,使用自适应神经模糊和统计方法、最近邻/朴素贝叶斯分类器以及自适应神经模糊推理系统(ANFIS)来预测17种心血管疾病风险因素。采用混合数据转换和分类方法对预测心血管疾病风险的分类变量和连续变量进行处理。我们在从一家医院收集的心血管疾病真实数据集上比较我们的混合模型和现有的机器学习技术。进行敏感性分析以确定影响因素,并展示与心血管疾病相关的关键变量,如患者年龄、胆固醇水平和血糖水平。我们的结果表明,所提出的方法优于著名的统计和机器学习方法,显示出它们在心血管疾病分类中的通用性和实用性。我们的调查表明,训练过程中ANFIS的预测准确率为96.56%,其次是SVR,预测准确率为91.95%。我们的研究对上述方法获得的结果进行了全面比较。