Bioinformatics Group, Wageningen University & Research, 6708 PB, Wageningen, the Netherlands.
National Phenome Centre, Section of Bioanalytical Chemistry, Division of Systems Medicine, Department of Metabolism, Digestion and Reproduction, Faculty of Medicine, Imperial College London, Hammersmith Hospital Campus, London, W12 0NN, UK.
Nat Commun. 2023 Mar 29;14(1):1752. doi: 10.1038/s41467-023-37446-4.
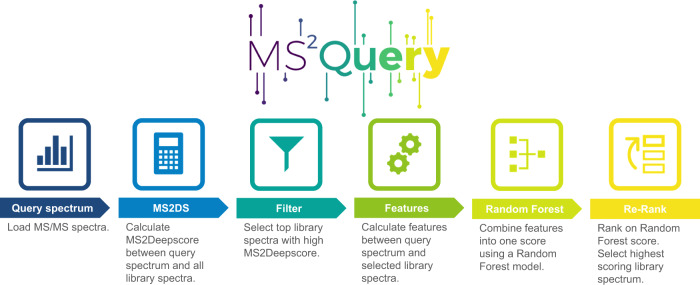
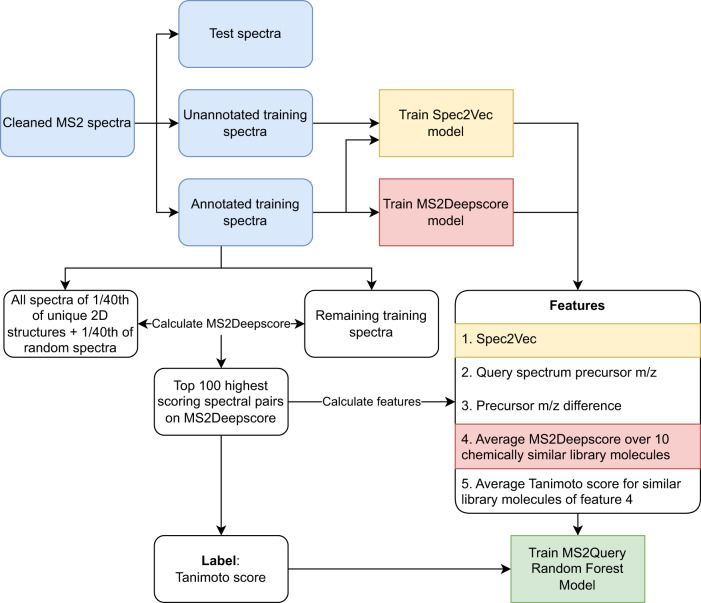
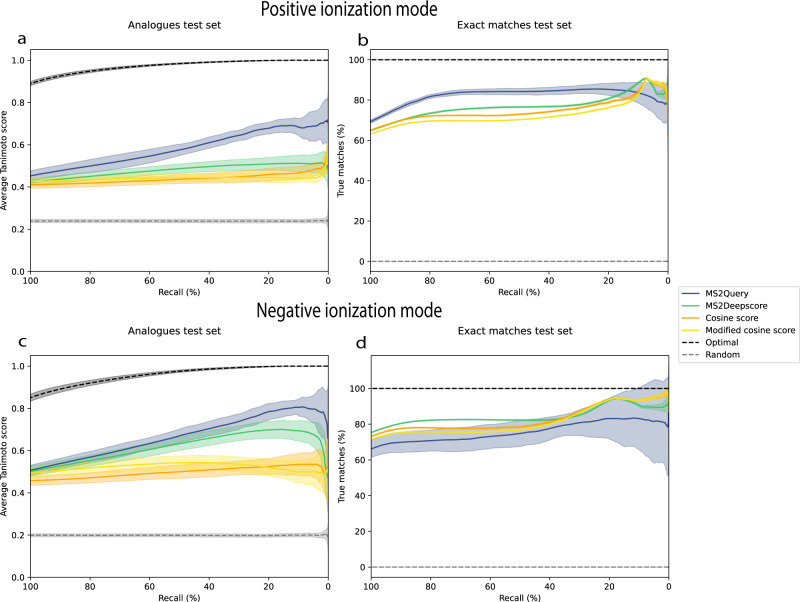
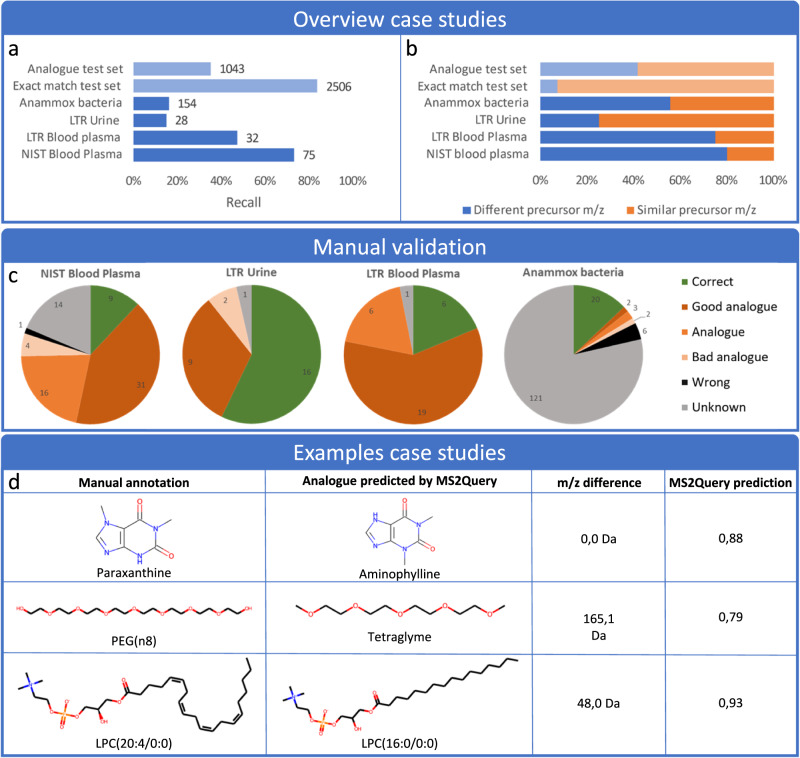
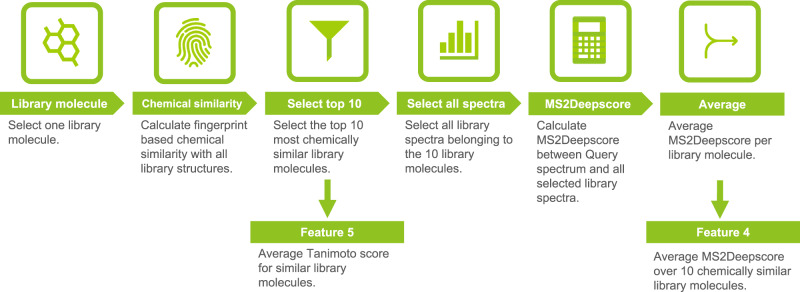
Metabolomics-driven discoveries of biological samples remain hampered by the grand challenge of metabolite annotation and identification. Only few metabolites have an annotated spectrum in spectral libraries; hence, searching only for exact library matches generally returns a few hits. An attractive alternative is searching for so-called analogues as a starting point for structural annotations; analogues are library molecules which are not exact matches but display a high chemical similarity. However, current analogue search implementations are not yet very reliable and relatively slow. Here, we present MS2Query, a machine learning-based tool that integrates mass spectral embedding-based chemical similarity predictors (Spec2Vec and MS2Deepscore) as well as detected precursor masses to rank potential analogues and exact matches. Benchmarking MS2Query on reference mass spectra and experimental case studies demonstrate improved reliability and scalability. Thereby, MS2Query offers exciting opportunities to further increase the annotation rate of metabolomics profiles of complex metabolite mixtures and to discover new biology.
代谢组学驱动的生物样本发现仍然受到代谢物注释和鉴定这一重大挑战的阻碍。只有少数代谢物在光谱库中有被注释的光谱;因此,仅搜索精确的库匹配通常只能得到少数命中。一个有吸引力的替代方法是寻找所谓的类似物作为结构注释的起点;类似物是库分子,它们不是精确匹配,但显示出高度的化学相似性。然而,目前的类似物搜索实现还不是非常可靠和相对较慢。在这里,我们介绍了 MS2Query,这是一个基于机器学习的工具,它集成了基于质荷比嵌入的化学相似性预测器(Spec2Vec 和 MS2Deepscore)以及检测到的前体质量,以对潜在的类似物和精确匹配进行排名。在参考质谱和实验案例研究上对 MS2Query 进行基准测试,证明了其可靠性和可扩展性的提高。因此,MS2Query 为进一步提高复杂代谢物混合物代谢组学图谱的注释率和发现新生物学提供了令人兴奋的机会。