Dorkenwald Sven, Schneider-Mizell Casey M, Brittain Derrick, Halageri Akhilesh, Jordan Chris, Kemnitz Nico, Castro Manual A, Silversmith William, Maitin-Shephard Jeremy, Troidl Jakob, Pfister Hanspeter, Gillet Valentin, Xenes Daniel, Bae J Alexander, Bodor Agnes L, Buchanan JoAnn, Bumbarger Daniel J, Elabbady Leila, Jia Zhen, Kapner Daniel, Kinn Sam, Lee Kisuk, Li Kai, Lu Ran, Macrina Thomas, Mahalingam Gayathri, Mitchell Eric, Mondal Shanka Subhra, Mu Shang, Nehoran Barak, Popovych Sergiy, Takeno Marc, Torres Russel, Turner Nicholas L, Wong William, Wu Jingpeng, Yin Wenjing, Yu Szi-Chieh, Reid R Clay, da Costa Nuno Maçarico, Seung H Sebastian, Collman Forrest
Princeton Neuroscience Institute, Princeton University, Princeton, USA.
Computer Science Department, Princeton University, Princeton, USA.
bioRxiv. 2023 Jul 28:2023.07.26.550598. doi: 10.1101/2023.07.26.550598.
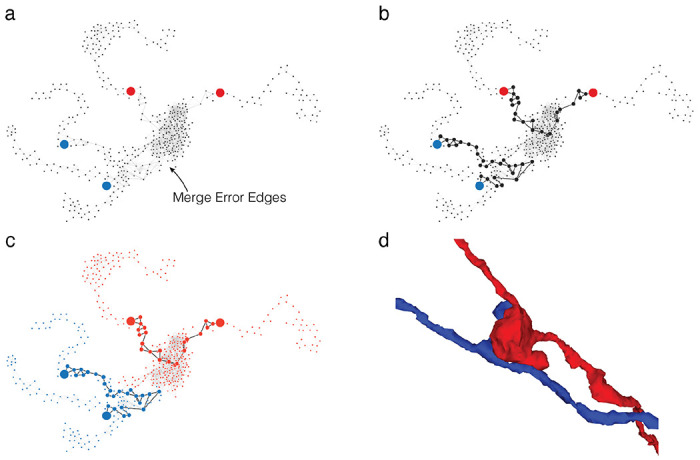
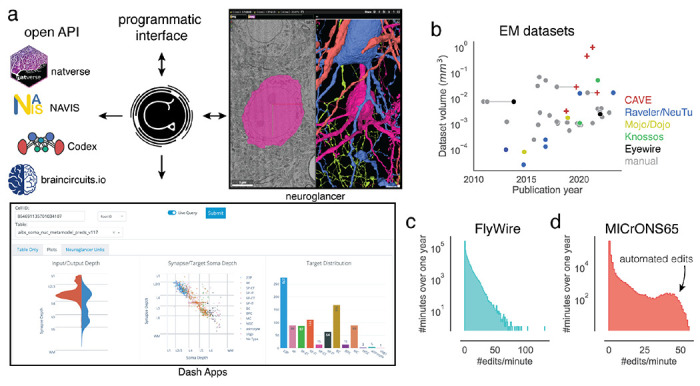
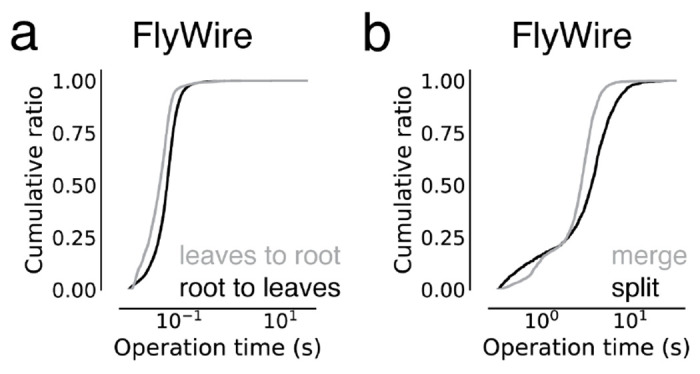
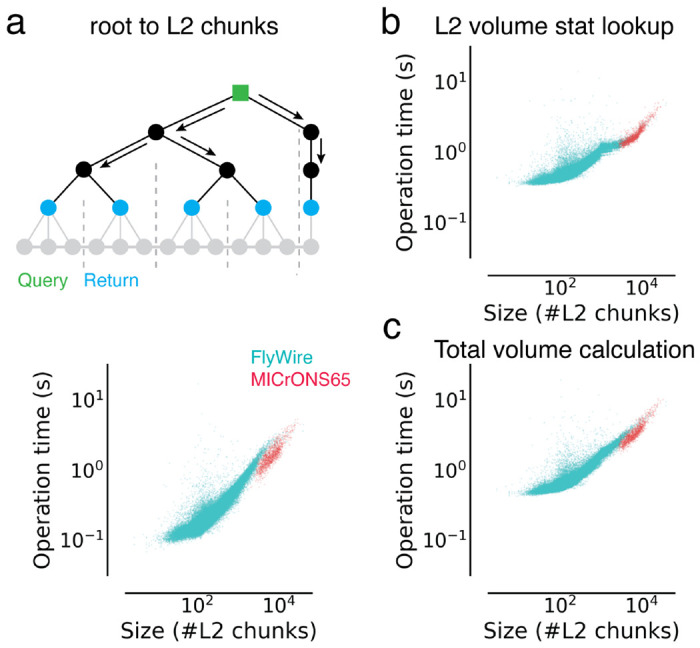
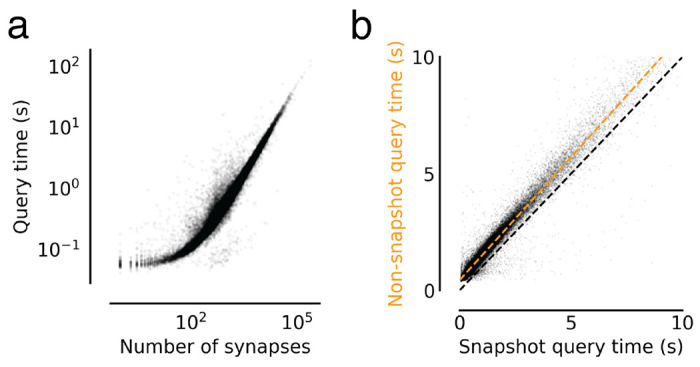
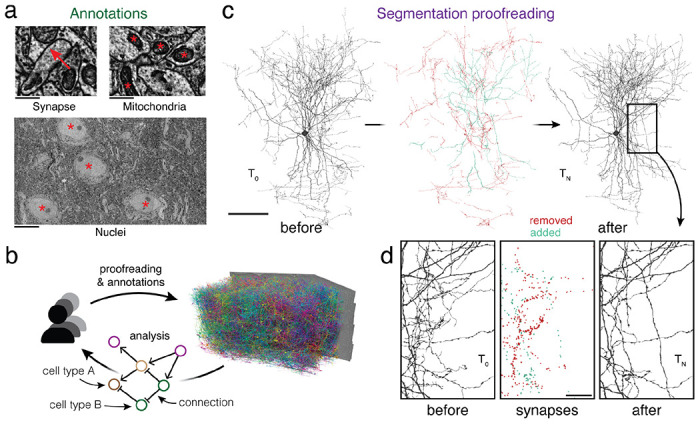
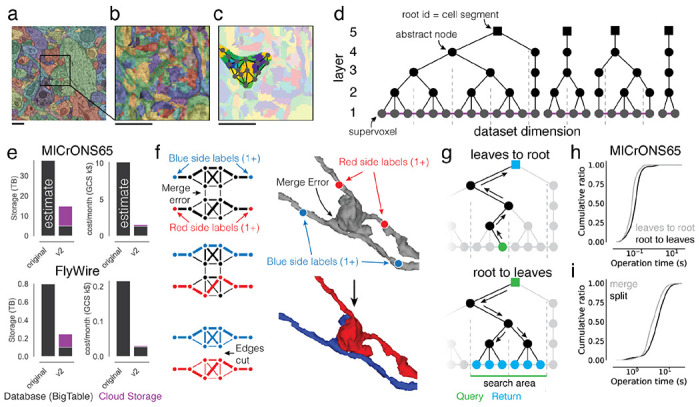
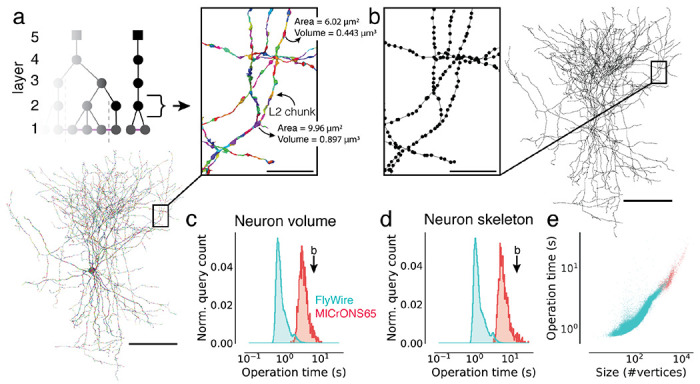
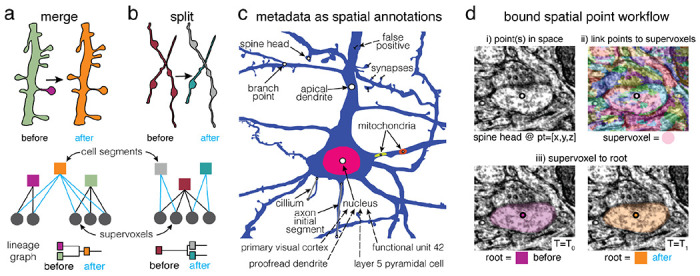
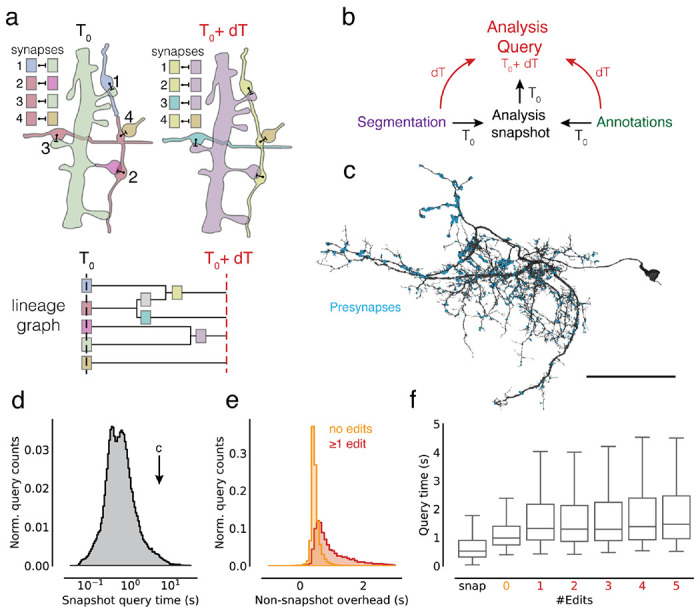
Advances in Electron Microscopy, image segmentation and computational infrastructure have given rise to large-scale and richly annotated connectomic datasets which are increasingly shared across communities. To enable collaboration, users need to be able to concurrently create new annotations and correct errors in the automated segmentation by proofreading. In large datasets, every proofreading edit relabels cell identities of millions of voxels and thousands of annotations like synapses. For analysis, users require immediate and reproducible access to this constantly changing and expanding data landscape. Here, we present the Connectome Annotation Versioning Engine (CAVE), a computational infrastructure for immediate and reproducible connectome analysis in up-to petascale datasets (~1mm) while proofreading and annotating is ongoing. For segmentation, CAVE provides a distributed proofreading infrastructure for continuous versioning of large reconstructions. Annotations in CAVE are defined by locations such that they can be quickly assigned to the underlying segment which enables fast analysis queries of CAVE's data for arbitrary time points. CAVE supports schematized, extensible annotations, so that researchers can readily design novel annotation types. CAVE is already used for many connectomics datasets, including the largest datasets available to date.
电子显微镜、图像分割和计算基础设施的进步催生了大规模且注释丰富的连接组数据集,这些数据集在不同社区之间越来越多地共享。为了实现协作,用户需要能够在对自动分割结果进行校对时,同时创建新的注释并纠正错误。在大型数据集中,每一次校对编辑都会重新标记数百万体素的细胞身份以及数千个诸如突触之类的注释。为了进行分析,用户需要能够即时且可重复地访问这个不断变化和扩展的数据环境。在此,我们展示了连接组注释版本控制引擎(CAVE),这是一种计算基础设施,用于在高达PB级数据集(~1mm)中进行即时且可重复的连接组分析,同时校对和注释工作仍在进行。对于分割,CAVE提供了一个分布式校对基础设施,用于对大型重建结果进行连续版本控制。CAVE中的注释由位置定义,这样它们就可以快速分配到基础段,从而能够针对任意时间点对CAVE的数据进行快速分析查询。CAVE支持模式化、可扩展的注释,以便研究人员能够轻松设计新颖的注释类型。CAVE已经被用于许多连接组数据集,包括迄今为止可用的最大数据集。