Handa Koichi, Thomas Morgan C, Kageyama Michiharu, Iijima Takeshi, Bender Andreas
Centre for Molecular Informatics, Department of Chemistry, University of Cambridge, Lensfield Road, Cambridge, CB2 1EW, UK.
Toxicology & DMPK Research Department, Teijin Institute for Bio-Medical Research, Teijin Pharma Limited, 4-3-2 Asahigaoka, Hino-Shi, Tokyo, 191-8512, Japan.
J Cheminform. 2023 Nov 21;15(1):112. doi: 10.1186/s13321-023-00781-1.
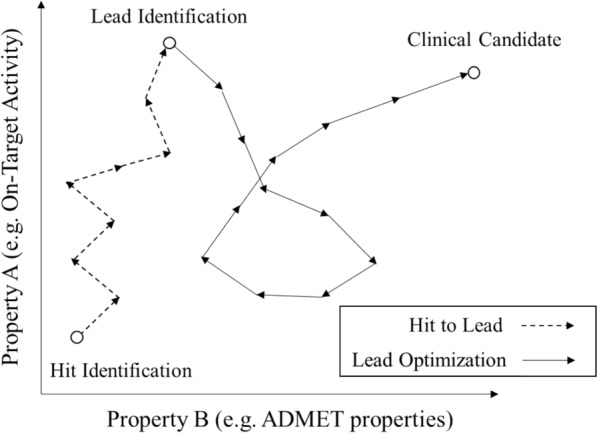
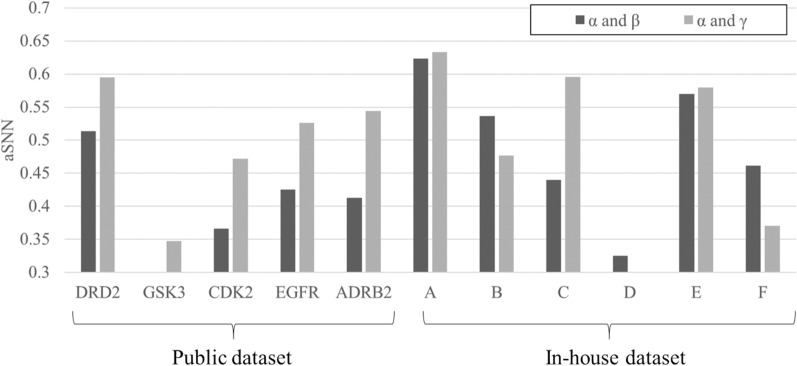
While a multitude of deep generative models have recently emerged there exists no best practice for their practically relevant validation. On the one hand, novel de novo-generated molecules cannot be refuted by retrospective validation (so that this type of validation is biased); but on the other hand prospective validation is expensive and then often biased by the human selection process. In this case study, we frame retrospective validation as the ability to mimic human drug design, by answering the following question: Can a generative model trained on early-stage project compounds generate middle/late-stage compounds de novo? To this end, we used experimental data that contains the elapsed time of a synthetic expansion following hit identification from five public (where the time series was pre-processed to better reflect realistic synthetic expansions) and six in-house project datasets, and used REINVENT as a widely adopted RNN-based generative model. After splitting the dataset and training REINVENT on early-stage compounds, we found that rediscovery of middle/late-stage compounds was much higher in public projects (at 1.60%, 0.64%, and 0.21% of the top 100, 500, and 5000 scored generated compounds) than in in-house projects (where the values were 0.00%, 0.03%, and 0.04%, respectively). Similarly, average single nearest neighbour similarity between early- and middle/late-stage compounds in public projects was higher between active compounds than inactive compounds; however, for in-house projects the converse was true, which makes rediscovery (if so desired) more difficult. We hence show that the generative model recovers very few middle/late-stage compounds from real-world drug discovery projects, highlighting the fundamental difference between purely algorithmic design and drug discovery as a real-world process. Evaluating de novo compound design approaches appears, based on the current study, difficult or even impossible to do retrospectively.Scientific Contribution This contribution hence illustrates aspects of evaluating the performance of generative models in a real-world setting which have not been extensively described previously and which hopefully contribute to their further future development.
尽管最近出现了大量深度生成模型,但对于它们在实际相关验证方面并没有最佳实践方法。一方面,新生成的分子无法通过回顾性验证被反驳(因此这种验证类型存在偏差);但另一方面,前瞻性验证成本高昂,且往往会受到人为选择过程的影响而产生偏差。在本案例研究中,我们将回顾性验证定义为模仿人类药物设计的能力,通过回答以下问题:在早期项目化合物上训练的生成模型能否从头生成中期/后期化合物?为此,我们使用了实验数据,这些数据包含了从五个公开数据集(其中时间序列经过预处理以更好地反映实际合成扩展)和六个内部项目数据集中识别出命中化合物后合成扩展所经过的时间,并使用REINVENT作为一种广泛采用的基于循环神经网络的生成模型。在将数据集拆分并在早期化合物上训练REINVENT之后,我们发现公开项目中中期/后期化合物的重新发现率(在前100、500和5000个评分最高的生成化合物中分别为1.60%、0.64%和0.21%)远高于内部项目(相应的值分别为0.00%、0.03%和0.04%)。同样,公开项目中早期与中期/后期活性化合物之间的平均单最近邻相似度高于非活性化合物之间的相似度;然而,对于内部项目,情况则相反,这使得重新发现(如果需要的话)更加困难。因此,我们表明生成模型从实际药物发现项目中重新发现的中期/后期化合物非常少,突出了纯算法设计与作为实际过程的药物发现之间的根本差异。基于当前研究,评估从头化合物设计方法似乎很难甚至不可能通过回顾性进行。科学贡献 因此,本贡献阐述了在实际环境中评估生成模型性能的一些方面,这些方面此前尚未得到广泛描述,希望能为其未来的进一步发展做出贡献。