García-Barrios Guillermo, Crespo-Herrera Leonardo, Cruz-Izquierdo Serafín, Vitale Paolo, Sandoval-Islas José Sergio, Gerard Guillermo Sebastián, Aguilar-Rincón Víctor Heber, Corona-Torres Tarsicio, Crossa José, Pacheco-Gil Rosa Angela
Postgrado en Recursos Genéticos y Productividad-Genética, Colegio de Postgraduados, Texcoco 56264, Estado de México, Mexico.
International Maize and Wheat Improvement Center (CIMMYT), Km 35 Carretera México-Veracruz, Texcoco 56237, Estado de México, Mexico.
Genes (Basel). 2024 Mar 27;15(4):417. doi: 10.3390/genes15040417.
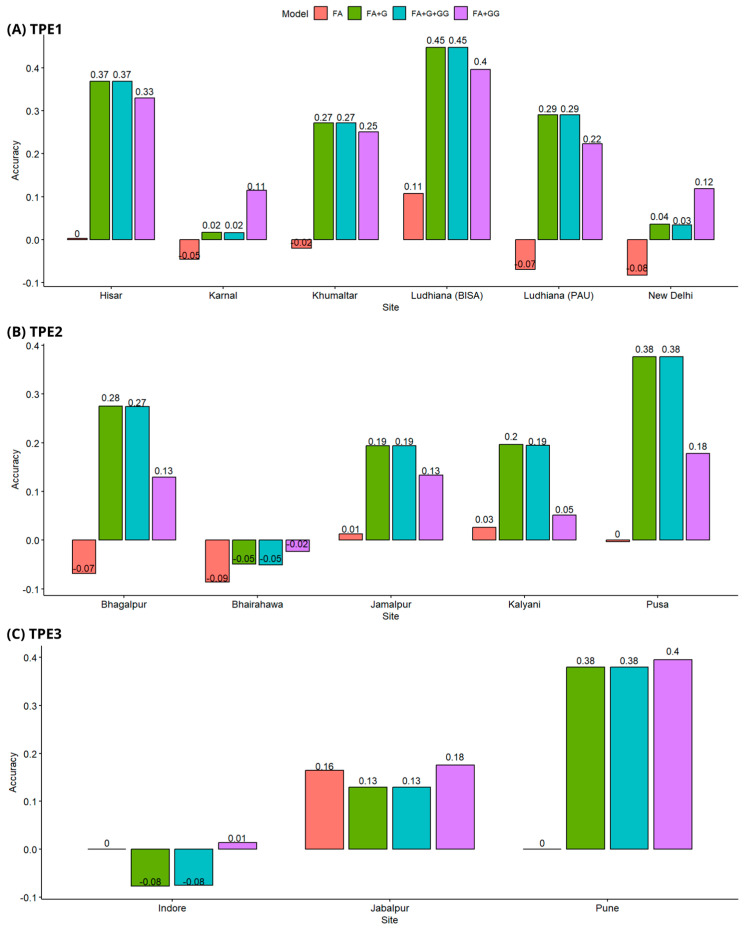
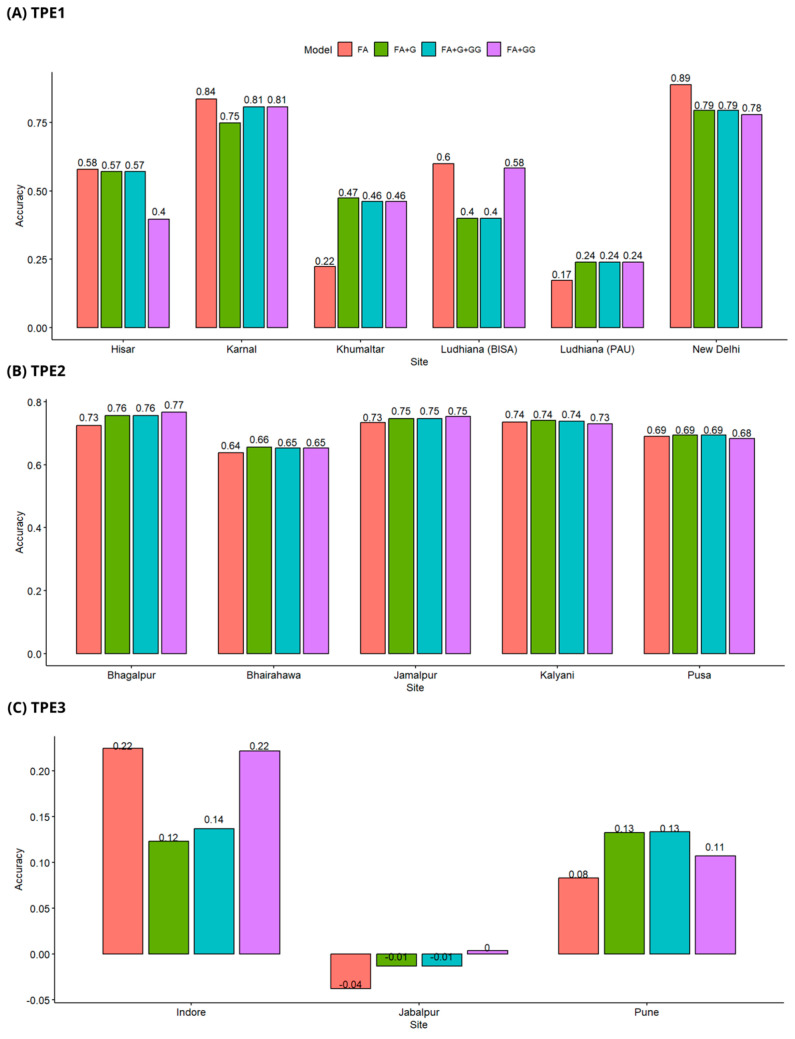
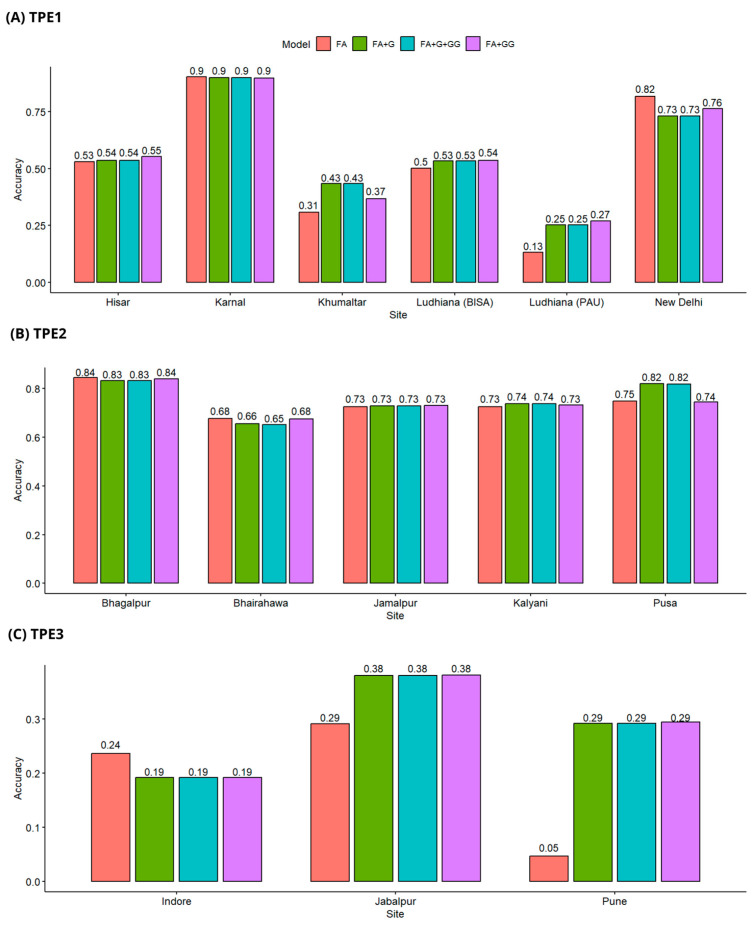
Genomic prediction relates a set of markers to variability in observed phenotypes of cultivars and allows for the prediction of phenotypes or breeding values of genotypes on unobserved individuals. Most genomic prediction approaches predict breeding values based solely on additive effects. However, the economic value of wheat lines is not only influenced by their additive component but also encompasses a non-additive part (e.g., additive × additive epistasis interaction). In this study, genomic prediction models were implemented in three target populations of environments (TPE) in South Asia. Four models that incorporate genotype × environment interaction (G × E) and genotype × genotype (GG) were tested: Factor Analytic (FA), FA with genomic relationship matrix (FA + G), FA with epistatic relationship matrix (FA + GG), and FA with both genomic and epistatic relationship matrices (FA + G + GG). Results show that the FA + G and FA + G + GG models displayed the best and a similar performance across all tests, leading us to infer that the FA + G model effectively captures certain epistatic effects. The wheat lines tested in sites in different TPE were predicted with different precisions depending on the cross-validation employed. In general, the best prediction accuracy was obtained when some lines were observed in some sites of particular TPEs and the worse genomic prediction was observed when wheat lines were never observed in any site of one TPE.
基因组预测将一组标记与品种观察到的表型变异联系起来,并能够预测未观察个体的基因型的表型或育种值。大多数基因组预测方法仅基于加性效应来预测育种值。然而,小麦品系的经济价值不仅受其加性成分的影响,还包括非加性部分(例如,加性×加性上位性互作)。在本研究中,在南亚的三个目标环境群体(TPE)中实施了基因组预测模型。测试了四种纳入基因型×环境互作(G×E)和基因型×基因型(GG)的模型:因子分析(FA)、带有基因组关系矩阵的FA(FA + G)、带有上位性关系矩阵的FA(FA + GG)以及带有基因组和上位性关系矩阵的FA(FA + G + GG)。结果表明,FA + G和FA + G + GG模型在所有测试中表现最佳且相似,这使我们推断FA + G模型有效地捕捉了某些上位性效应。根据所采用的交叉验证,在不同TPE地点测试的小麦品系预测精度不同。一般来说,当在特定TPE的某些地点观察到一些品系时,预测准确性最高;而当在一个TPE的任何地点都未观察到小麦品系时,基因组预测效果最差。