Shankar Sumukh Vasisht, Dhingra Lovedeep S, Aminorroaya Arya, Adejumo Philip, Nadkarni Girish N, Xu Hua, Brandt Cynthia, Oikonomou Evangelos K, Pedroso Aline F, Khera Rohan
Section of Cardiovascular Medicine, Department of Internal Medicine, Yale School of Medicine, New Haven, CT, USA.
The Charles Bronfman Institute for Personalized Medicine, Icahn School of Medicine at Mount Sinai, New York, NY, USA.
medRxiv. 2024 Oct 8:2024.10.08.24315035. doi: 10.1101/2024.10.08.24315035.
Rich data in cardiovascular diagnostic testing are often sequestered in unstructured reports, with the necessity of manual abstraction limiting their use in real-time applications in patient care and research.
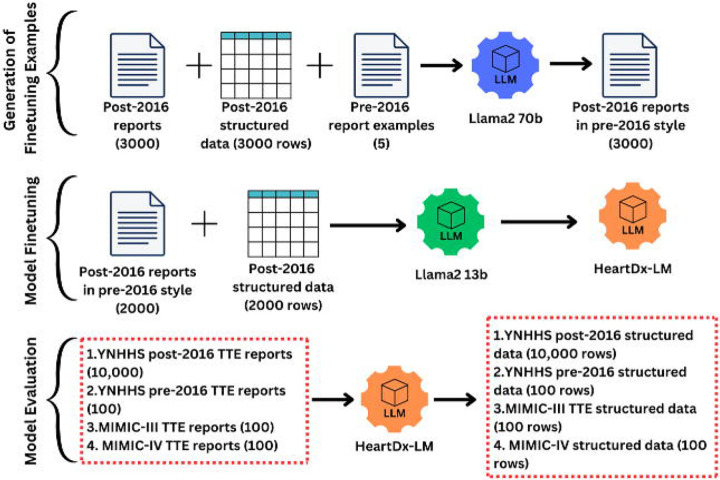
We developed a two-step process that sequentially deploys generative and interpretative large language models (LLMs; Llama2 70b and Llama2 13b). Using a Llama2 70b model, we generated varying formats of transthoracic echocardiogram (TTE) reports from 3,000 real-world echo reports with paired structured elements, leveraging temporal changes in reporting formats to define the variations. Subsequently, we fine-tuned Llama2 13b using sequentially larger batches of generated echo reports as inputs, to extract data from free-text narratives across 18 clinically relevant echocardiographic fields. This was set up as a prompt-based supervised training task. We evaluated the fine-tuned Llama2 13b model, HeartDx-LM, on several distinct echocardiographic datasets: (i) reports across the different time periods and formats at Yale New Haven Health System (YNHHS), (ii) the Medical Information Mart for Intensive Care (MIMIC) III dataset, and (iii) the MIMIC IV dataset. We used the accuracy of extracted fields and Cohen's Kappa as the metrics and have publicly released the HeartDX-LM model.
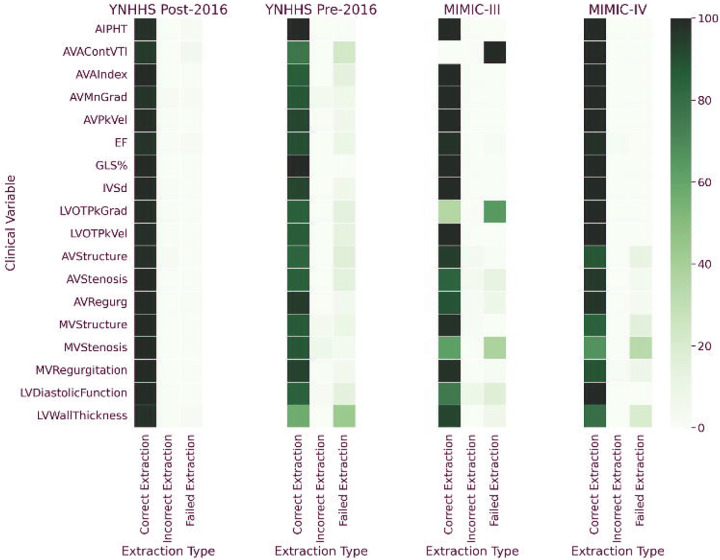
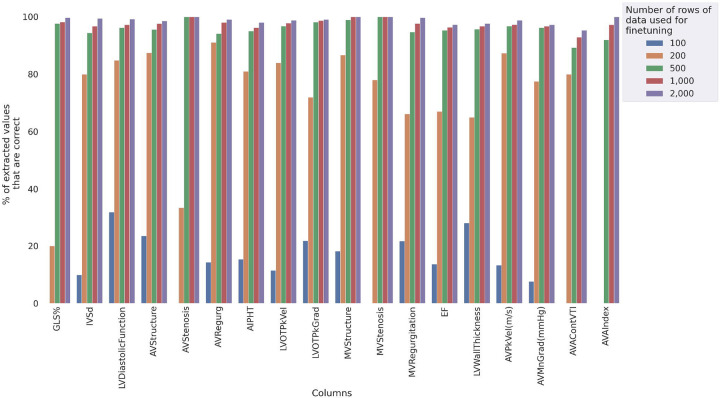
The HeartDX-LM model was trained on randomly selected 2,000 synthetic echo reports with varying formats and paired structured labels, with a wide range of clinical findings. We identified a lower threshold of 500 annotated reports required for fine-tuning Llama2 13b to achieve stable and consistent performance. At YNHHS, the HeartDx-LM model accurately extracted 69,144 out of 70,032 values (98.7%) across 18 clinical fields from unstructured reports in the test set from contemporary records where paired structured data were also available. In older echo reports where only unstructured reports were available, the model achieved 87.1% accuracy against expert annotations for the same 18 fields for a random sample of 100 reports. Similarly, in expert-annotated external validation sets from MIMIC-IV and MIMIC-III, HeartDx-LM correctly extracted 201 out of 220 available values (91.3%) and 615 out of 707 available values (87.9%), respectively, from 100 randomly chosen and expert annotated echo reports from each set.
We developed a novel method using paired large and moderate-sized LLMs to automate the extraction of unstructured echocardiographic reports into tabular datasets. Our approach represents a scalable strategy that transforms unstructured reports into computable elements that can be leveraged to improve cardiovascular care quality and enable research.
心血管诊断测试中的丰富数据通常被隔离在非结构化报告中,由于需要人工提取,限制了它们在患者护理和研究的实时应用中的使用。
我们开发了一个两步流程,依次部署生成式和解释性大语言模型(LLMs;Llama2 70b和Llama2 13b)。使用Llama2 70b模型,我们从3000份具有配对结构化元素的真实世界超声心动图(TTE)报告中生成了不同格式的报告,利用报告格式的时间变化来定义变化。随后,我们使用依次增加批次的生成式超声心动图报告作为输入对Llama2 13b进行微调,以从18个临床相关超声心动图领域的自由文本叙述中提取数据。这被设置为一个基于提示的监督训练任务。我们在几个不同的超声心动图数据集上评估了经过微调的Llama2 13b模型HeartDx-LM:(i)耶鲁纽黑文医疗系统(YNHHS)不同时间段和格式的报告,(ii)重症监护医学信息集市(MIMIC)III数据集,以及(iii)MIMIC IV数据集。我们使用提取字段的准确性和科恩kappa系数作为指标,并已公开发布HeartDX-LM模型。
HeartDX-LM模型在随机选择的2000份具有不同格式和配对结构化标签的合成超声心动图报告上进行训练,这些报告具有广泛的临床发现。我们确定了将Llama2 13b微调以实现稳定和一致性能所需的较低阈值为500份注释报告。在YNHHS,HeartDx-LM模型从当代记录的测试集中的非结构化报告中准确提取了70032个值中的69144个(98.7%),涉及18个临床领域,其中也有配对的结构化数据。在只有非结构化报告的较旧超声心动图报告中,对于随机抽取的100份报告的相同18个领域,该模型相对于专家注释的准确率达到了87.1%。同样,在来自MIMIC-IV和MIMIC-III的专家注释外部验证集中,HeartDx-LM分别从每组随机选择并经专家注释的100份超声心动图报告中正确提取了220个可用值中的201个(91.3%)和707个可用值中的615个(87.9%)。
我们开发了一种新颖的方法,使用配对的大型和中型LLMs将非结构化超声心动图报告自动提取到表格数据集中。我们的方法代表了一种可扩展的策略,将非结构化报告转化为可计算的元素,可用于提高心血管护理质量并推动研究。