Institute of Computing, Unicamp, Brazil.
School of Electrical and Computer Engineering, Unicamp, Brazil.
Sci Data. 2024 Nov 2;11(1):1192. doi: 10.1038/s41597-024-03951-4.
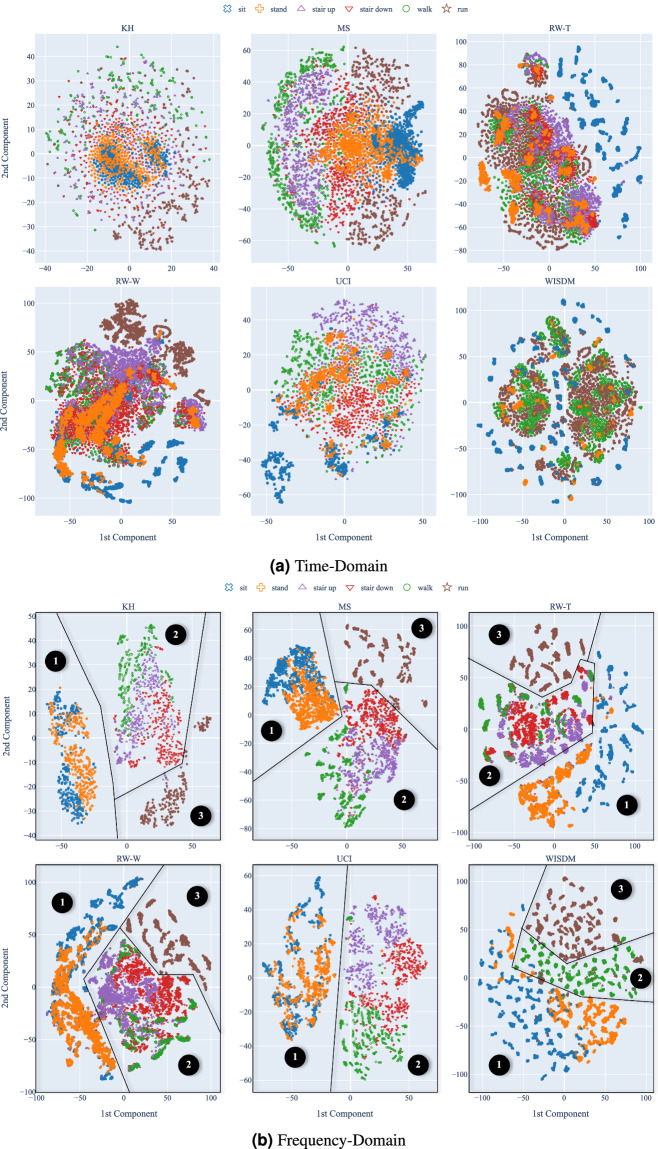
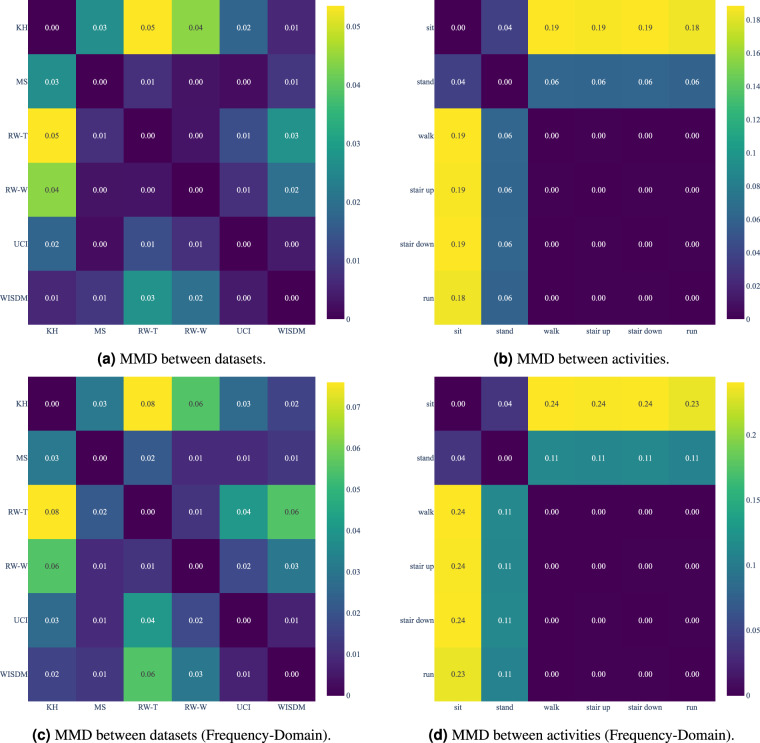
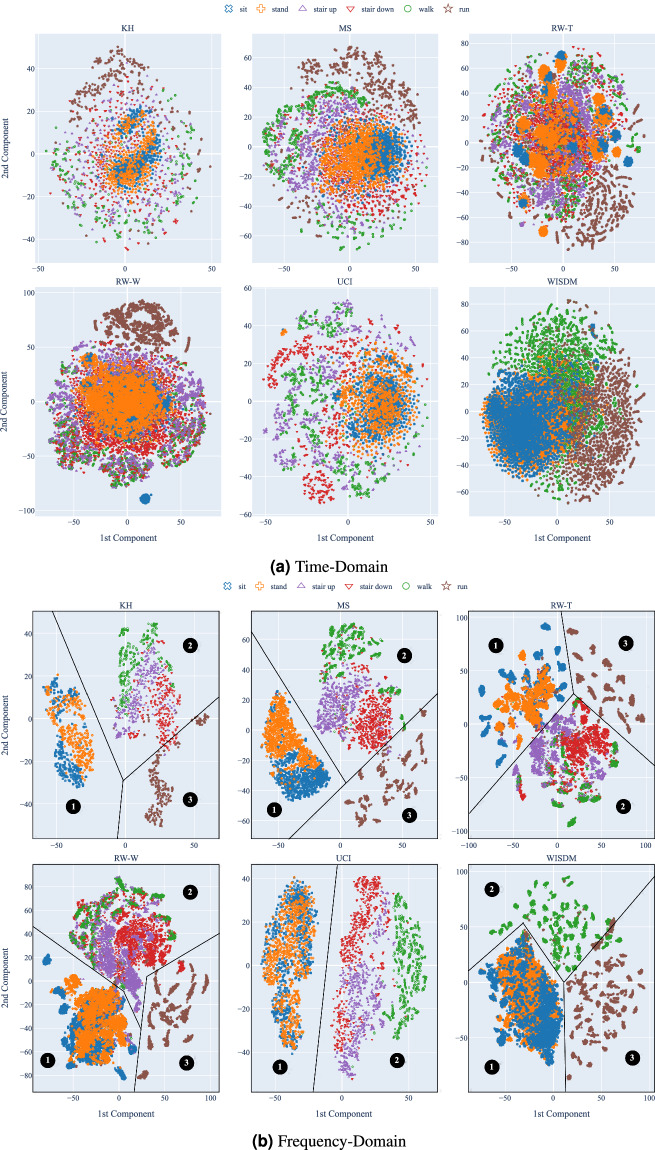
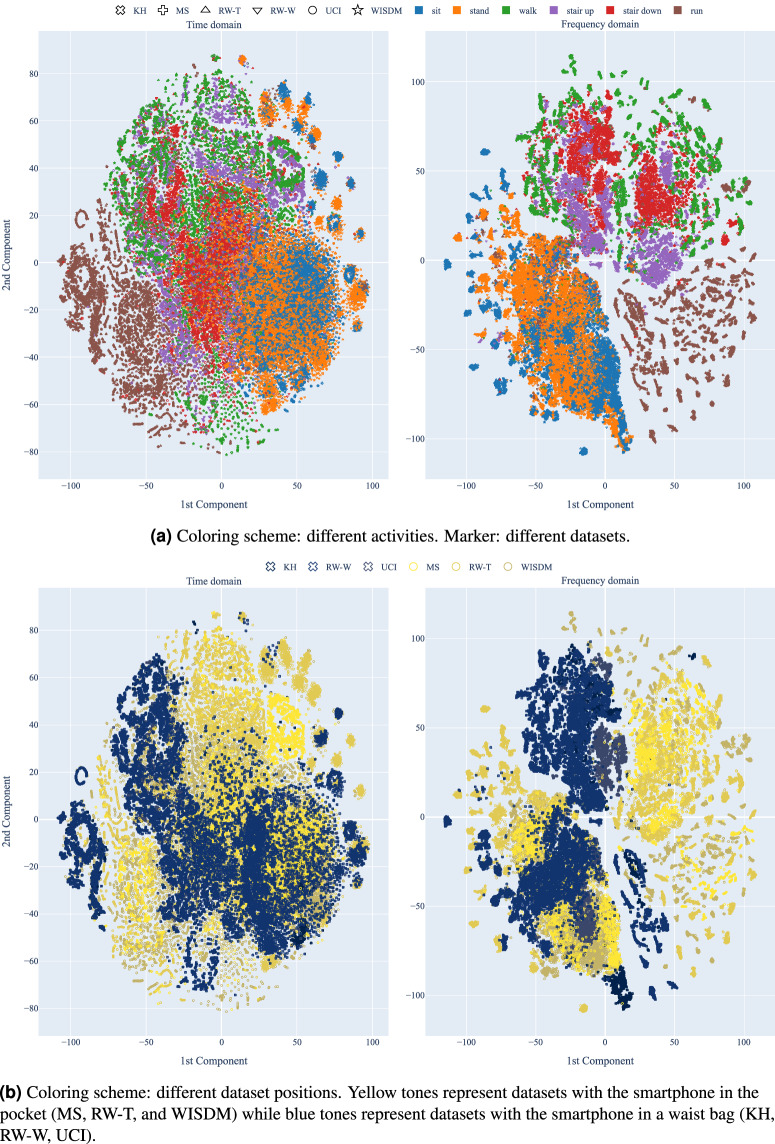
Human activity recognition (HAR) using smartphone inertial sensors, like accelerometers and gyroscopes, enhances smartphones' adaptability and user experience. Data distribution from these sensors is affected by several factors including sensor hardware, software, device placement, user demographics, terrain, and more. Most datasets focus on providing variability in user and (sometimes) device placement, limiting domain adaptation and generalization studies. Consequently, models trained on one dataset often perform poorly on others. Despite many publicly available HAR datasets, cross-dataset generalization remains challenging due to data format incompatibilities, such as differences in measurement units, sampling rates, and label encoding. Hence, we introduce the DAGHAR benchmark, a curated collection of datasets for domain adaptation and generalization studies in smartphone-based HAR. We standardized six datasets in terms of accelerometer units, sampling rate, gravity component, activity labels, user partitioning, and time window size, removing trivial biases while preserving intrinsic differences. This enables controlled evaluation of model generalization capabilities. Additionally, we provide baseline performance metrics from state-of-the-art machine learning models, crucial for comprehensive evaluations of generalization in HAR tasks.
使用智能手机惯性传感器(如加速度计和陀螺仪)进行人体活动识别 (HAR),可增强智能手机的适应性和用户体验。这些传感器的数据分布受到多种因素的影响,包括传感器硬件、软件、设备放置、用户人口统计数据、地形等。大多数数据集都侧重于提供用户和(有时)设备放置的可变性,限制了域自适应和泛化研究。因此,在一个数据集上训练的模型在其他数据集上的表现往往不佳。尽管有许多公开可用的 HAR 数据集,但由于数据格式不兼容,例如测量单位、采样率和标签编码的差异,跨数据集的泛化仍然具有挑战性。因此,我们引入了 DAGHAR 基准,这是一个用于智能手机 HAR 中的域自适应和泛化研究的精选数据集集合。我们根据加速度计单位、采样率、重力分量、活动标签、用户分区和时间窗口大小对六个数据集进行了标准化,在保留内在差异的同时消除了微不足道的偏差。这使得模型泛化能力的可控评估成为可能。此外,我们还提供了来自最先进的机器学习模型的基线性能指标,这对于 HAR 任务中的全面泛化评估至关重要。