Mess Sarah A, Mackey Alison J, Yarowsky David E
From Sarah A. Mess, M. D., LLC, Columbia, MD.
Department of Plastic Surgery, Georgetown University Clinical Faculty, Washington, DC.
Plast Reconstr Surg Glob Open. 2025 Jan 16;13(1):e6450. doi: 10.1097/GOX.0000000000006450. eCollection 2025 Jan.
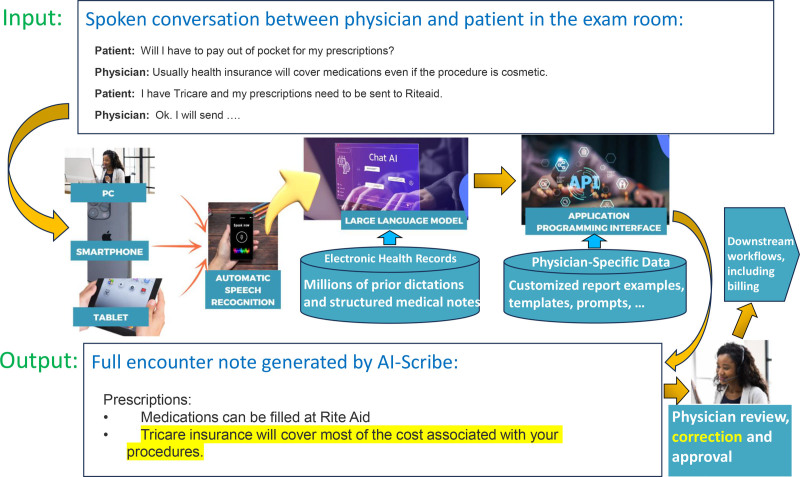
Artificial intelligence (AI) scribe applications in the healthcare community are in the early adoption phase and offer unprecedented efficiency for medical documentation. They typically use an application programming interface with a large language model (LLM), for example, generative pretrained transformer 4. They use automatic speech recognition on the physician-patient interaction, generating a full medical note for the encounter, together with a draft follow-up e-mail for the patient and, often, recommendations, all within seconds or minutes. This provides physicians with increased cognitive freedom during medical encounters due to less time needed interfacing with electronic medical records. However, careful proofreading of the AI-generated language by the physician signing the note is essential. Insidious and potentially significant errors of omission, fabrication, or substitution may occur. The neural network algorithms of LLMs have unpredictable sensitivity to user input and inherent variability in their output. LLMs are unconstrained by established medical knowledge or rules. As they gain increasing levels of access to large corpora of medical records, the explosion of discovered knowledge comes with large potential risks, including to patient privacy, and potential bias in algorithms. Medical AI developers should use robust regulatory oversights, adhere to ethical guidelines, correct bias in algorithms, and improve detection and correction of deviations from the intended output.
人工智能(AI)抄写应用在医疗保健领域正处于早期采用阶段,为医疗记录提供了前所未有的效率。它们通常使用应用程序编程接口与大语言模型(LLM),例如生成式预训练变换器4。它们对医患互动使用自动语音识别,在几秒钟或几分钟内生成此次就诊的完整医疗记录,以及给患者的后续电子邮件草稿,并且通常还有建议。这使得医生在医疗就诊期间有了更大的认知自由度,因为与电子病历交互所需的时间减少了。然而,签署记录的医生对人工智能生成的语言进行仔细校对至关重要。可能会出现隐匿且潜在重大的遗漏、编造或替换错误。大语言模型的神经网络算法对用户输入具有不可预测的敏感性,其输出存在固有变异性。大语言模型不受既定医学知识或规则的约束。随着它们越来越多地访问大量医疗记录语料库,发现的知识激增伴随着巨大的潜在风险,包括对患者隐私的风险以及算法中的潜在偏差。医疗人工智能开发者应采用强有力的监管监督,遵守道德准则,纠正算法偏差,并改进对预期输出偏差的检测和纠正。