McCulloch Charles E, Neuhaus John M
Division of Biostatistics, Department of Epidemiology and Biostatistics, University of California, San Francisco, San Francisco, California 94107, USA.
Biometrics. 2011 Mar;67(1):270-9. doi: 10.1111/j.1541-0420.2010.01435.x.
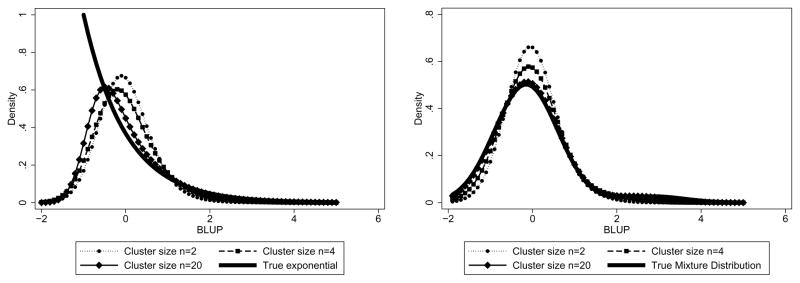
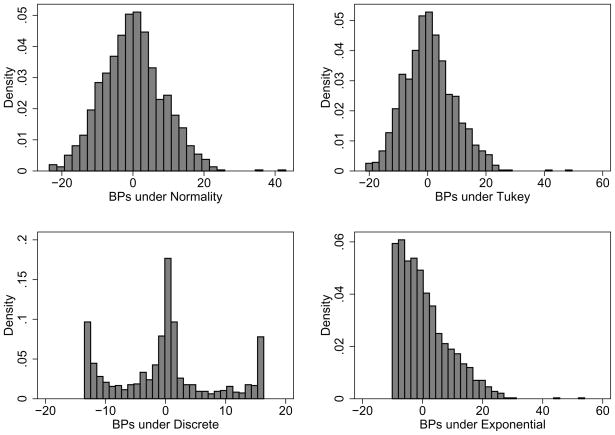
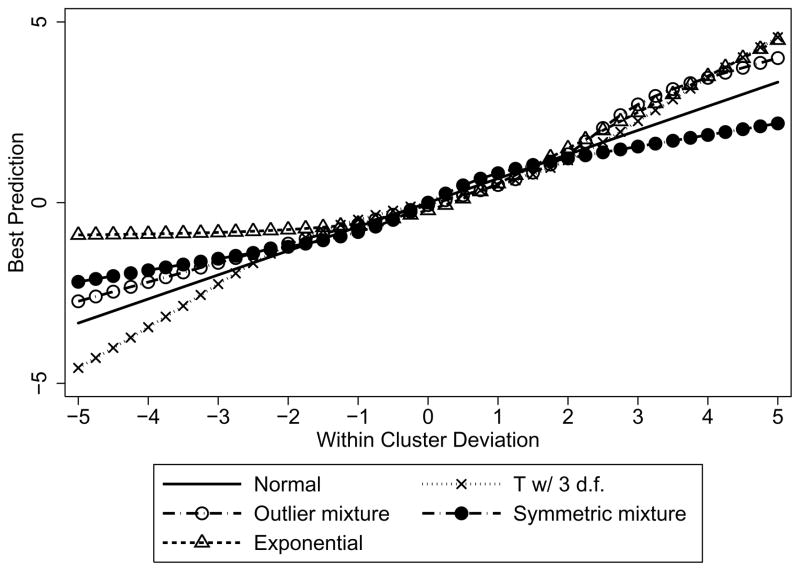
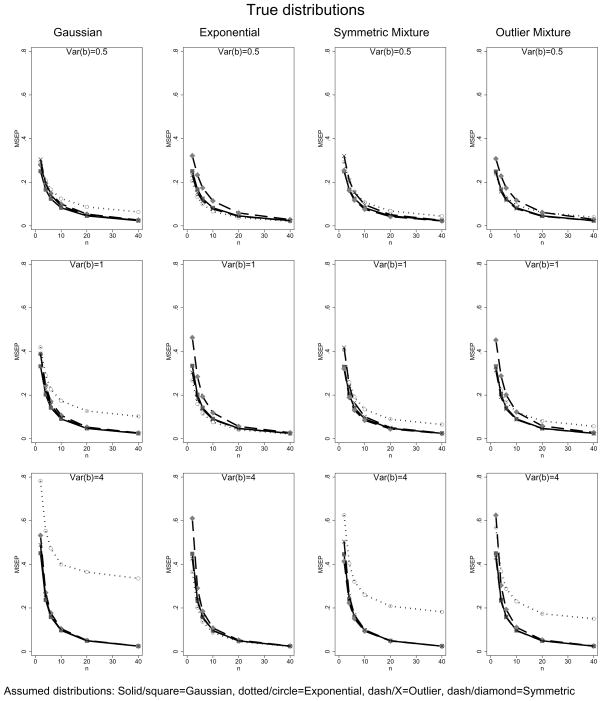
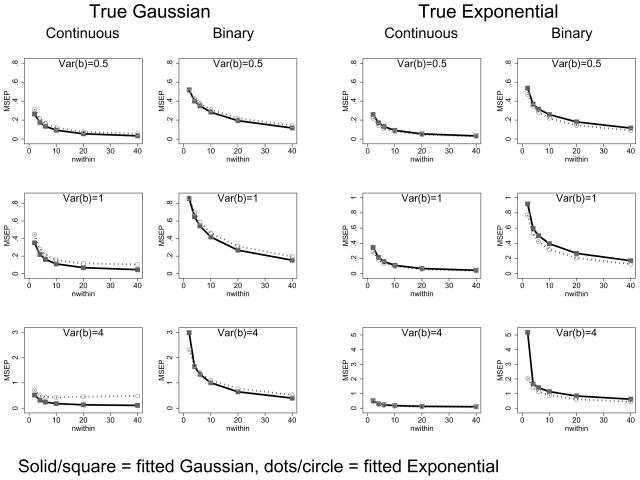
Statistical models that include random effects are commonly used to analyze longitudinal and correlated data, often with the assumption that the random effects follow a Gaussian distribution. Via theoretical and numerical calculations and simulation, we investigate the impact of misspecification of this distribution on both how well the predicted values recover the true underlying distribution and the accuracy of prediction of the realized values of the random effects. We show that, although the predicted values can vary with the assumed distribution, the prediction accuracy, as measured by mean square error, is little affected for mild-to-moderate violations of the assumptions. Thus, standard approaches, readily available in statistical software, will often suffice. The results are illustrated using data from the Heart and Estrogen/Progestin Replacement Study using models to predict future blood pressure values.
包含随机效应的统计模型通常用于分析纵向数据和相关数据,通常假定随机效应服从高斯分布。通过理论、数值计算和模拟,我们研究了这种分布的错误设定对预测值恢复真实潜在分布的程度以及随机效应实现值预测准确性的影响。我们表明,尽管预测值会随假定分布而变化,但对于轻度到中度违反假设的情况,以均方误差衡量的预测准确性受影响较小。因此,统计软件中常用的标准方法通常就足够了。使用心脏和雌激素/孕激素替代研究的数据,通过模型预测未来血压值来说明这些结果。