Department of Information Science, University of Arkansas at Little Rock, 2801 S, University Ave, Little Rock, AR 72204-1099, USA.
BMC Bioinformatics. 2011 Oct 18;12 Suppl 10(Suppl 10):S11. doi: 10.1186/1471-2105-12-S10-S11.
The Food and Drug Administration (FDA) approved drug labels contain a broad array of information, ranging from adverse drug reactions (ADRs) to drug efficacy, risk-benefit consideration, and more. However, the labeling language used to describe these information is free text often containing ambiguous semantic descriptions, which poses a great challenge in retrieving useful information from the labeling text in a consistent and accurate fashion for comparative analysis across drugs. Consequently, this task has largely relied on the manual reading of the full text by experts, which is time consuming and labor intensive.
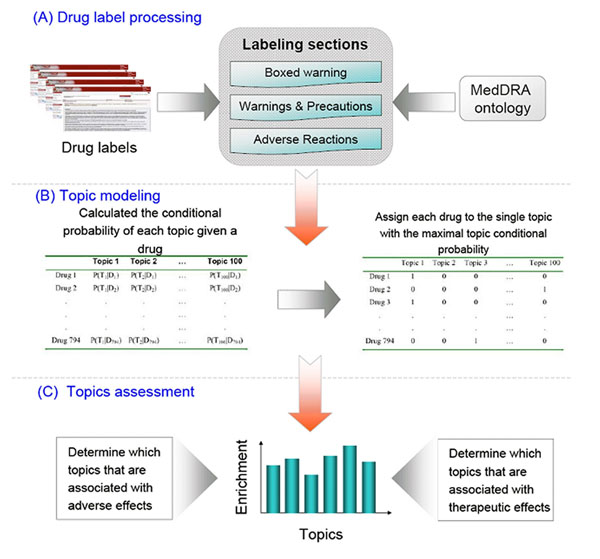
In this study, a novel text mining method with unsupervised learning in nature, called topic modeling, was applied to the drug labeling with a goal of discovering "topics" that group drugs with similar safety concerns and/or therapeutic uses together. A total of 794 FDA-approved drug labels were used in this study. First, the three labeling sections (i.e., Boxed Warning, Warnings and Precautions, Adverse Reactions) of each drug label were processed by the Medical Dictionary for Regulatory Activities (MedDRA) to convert the free text of each label to the standard ADR terms. Next, the topic modeling approach with latent Dirichlet allocation (LDA) was applied to generate 100 topics, each associated with a set of drugs grouped together based on the probability analysis. Lastly, the efficacy of the topic modeling was evaluated based on known information about the therapeutic uses and safety data of drugs.
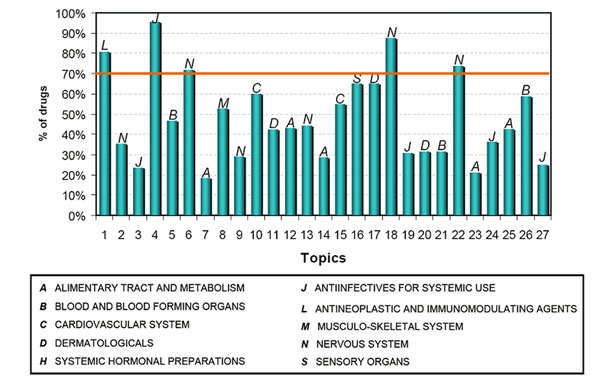
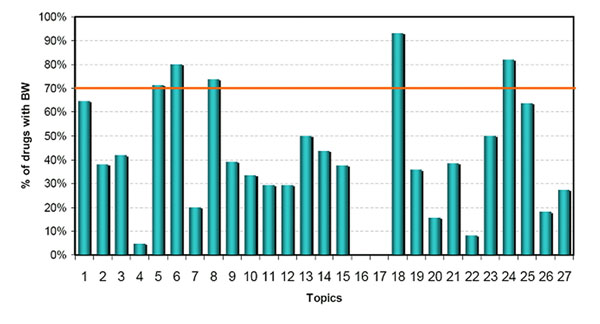
The results demonstrate that drugs grouped by topics are associated with the same safety concerns and/or therapeutic uses with statistical significance (P<0.05). The identified topics have distinct context that can be directly linked to specific adverse events (e.g., liver injury or kidney injury) or therapeutic application (e.g., antiinfectives for systemic use). We were also able to identify potential adverse events that might arise from specific medications via topics.
The successful application of topic modeling on the FDA drug labeling demonstrates its potential utility as a hypothesis generation means to infer hidden relationships of concepts such as, in this study, drug safety and therapeutic use in the study of biomedical documents.
美国食品和药物管理局(FDA)批准的药品标签包含广泛的信息,从药物不良反应(ADR)到药物疗效、风险效益考量等。然而,用于描述这些信息的标签语言是自由文本,其中常包含模糊的语义描述,这给从标签文本中以一致和准确的方式检索有用信息带来了很大的挑战,以便在药物之间进行比较分析。因此,这项任务在很大程度上依赖于专家对全文的人工阅读,既费时又费力。
本研究应用一种具有自然无监督学习性质的新型文本挖掘方法,即主题建模,用于药品标签,旨在发现将具有相似安全性问题和/或治疗用途的药物分组在一起的“主题”。本研究共使用了 794 份 FDA 批准的药品标签。首先,通过医疗保健监管活动专用医学词典(MedDRA)处理每个药品标签的三个标签部分(即盒装警告、警告和注意事项、不良反应),将每个标签的自由文本转换为标准的药物不良反应术语。接下来,应用具有潜在狄利克雷分配(LDA)的主题建模方法生成 100 个主题,每个主题都与一组基于概率分析分组在一起的药物相关联。最后,根据药物治疗用途和安全性数据的已知信息评估主题建模的效果。
结果表明,根据主题分组的药物与相同的安全性问题和/或治疗用途相关,具有统计学意义(P<0.05)。所识别的主题具有独特的上下文,可以直接与特定的不良反应(例如肝损伤或肾损伤)或治疗应用(例如全身性抗感染药物)相关联。我们还能够通过主题识别出可能由特定药物引起的潜在不良反应。
主题建模在 FDA 药品标签上的成功应用证明了其作为一种假设生成手段的潜力,可以推断出隐藏的概念关系,例如,在本研究中,药物安全性和治疗用途在生物医学文献研究中的关系。