Manavalan Balachandran, Lee Juyong, Lee Jooyoung
Center for In Silico Protein Science, School of Computational Sciences, Korea Institute for Advanced Study, Seoul, Korea.
PLoS One. 2014 Sep 15;9(9):e106542. doi: 10.1371/journal.pone.0106542. eCollection 2014.
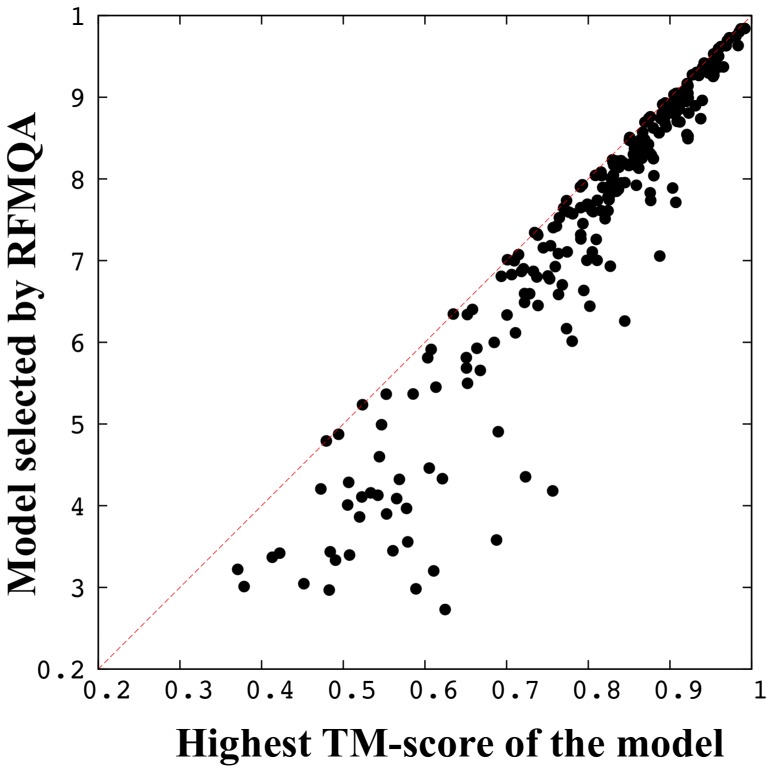
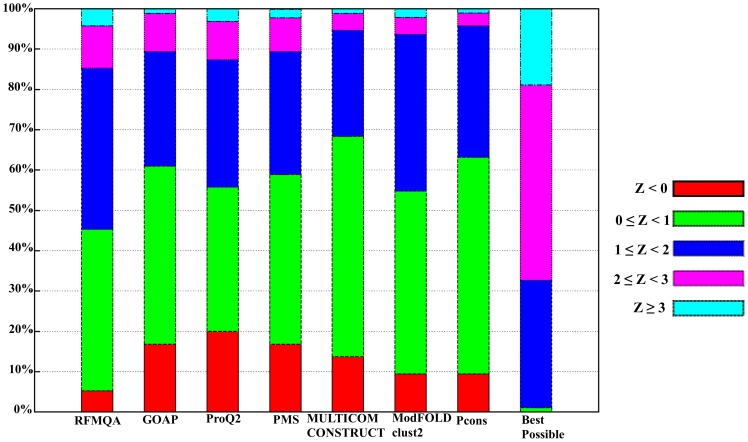
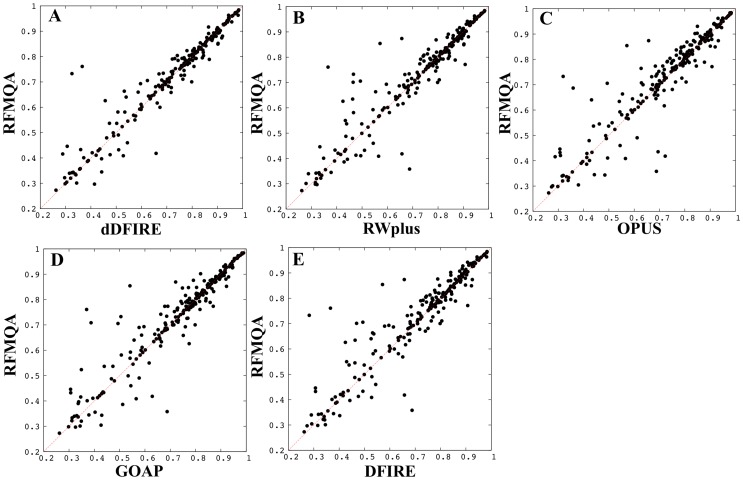
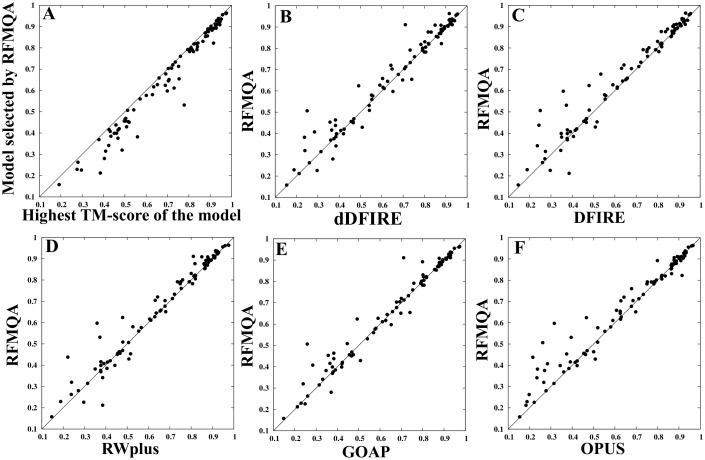
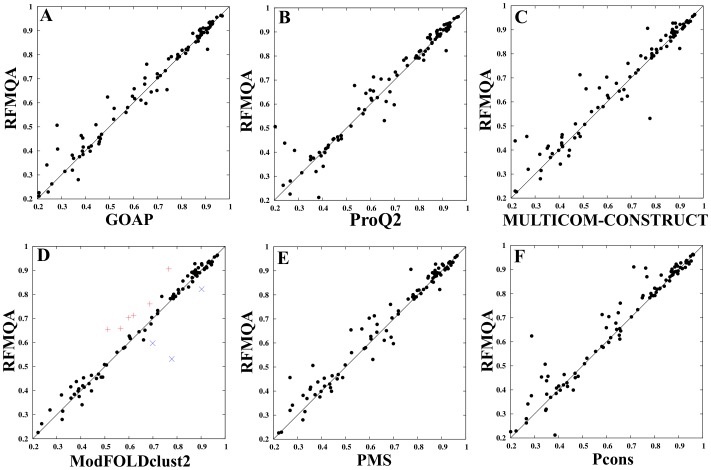
Recently, predicting proteins three-dimensional (3D) structure from its sequence information has made a significant progress due to the advances in computational techniques and the growth of experimental structures. However, selecting good models from a structural model pool is an important and challenging task in protein structure prediction. In this study, we present the first application of random forest based model quality assessment (RFMQA) to rank protein models using its structural features and knowledge-based potential energy terms. The method predicts a relative score of a model by using its secondary structure, solvent accessibility and knowledge-based potential energy terms. We trained and tested the RFMQA method on CASP8 and CASP9 targets using 5-fold cross-validation. The correlation coefficient between the TM-score of the model selected by RFMQA (TMRF) and the best server model (TMbest) is 0.945. We benchmarked our method on recent CASP10 targets by using CASP8 and 9 server models as a training set. The correlation coefficient and average difference between TMRF and TMbest over 95 CASP10 targets are 0.984 and 0.0385, respectively. The test results show that our method works better in selecting top models when compared with other top performing methods. RFMQA is available for download from http://lee.kias.re.kr/RFMQA/RFMQA_eval.tar.gz.
近年来,由于计算技术的进步和实验结构数量的增加,根据蛋白质序列信息预测其三维(3D)结构取得了重大进展。然而,在蛋白质结构预测中,从结构模型库中选择良好的模型是一项重要且具有挑战性的任务。在本研究中,我们首次应用基于随机森林的模型质量评估(RFMQA),利用蛋白质模型的结构特征和基于知识的势能项对其进行排序。该方法通过模型的二级结构、溶剂可及性和基于知识的势能项来预测模型的相对得分。我们使用5折交叉验证在CASP8和CASP9目标上对RFMQA方法进行了训练和测试。RFMQA选择的模型(TMRF)与最佳服务器模型(TMbest)的TM得分之间的相关系数为0.945。我们以CASP8和9服务器模型作为训练集,在最近的CASP10目标上对我们的方法进行了基准测试。在95个CASP10目标上,TMRF与TMbest之间的相关系数和平均差异分别为0.984和0.0385。测试结果表明,与其他表现最佳的方法相比,我们的方法在选择顶级模型方面表现更好。RFMQA可从http://lee.kias.re.kr/RFMQA/RFMQA_eval.tar.gz下载。