Cattell Liam, Platsch Günther, Pfeiffer Richie, Declerck Jérôme, Schnabel Julia A, Hutton Chloe
Institute of Biomedical Engineering, Department of Engineering Science, University of Oxford, UK.
Siemens Molecular Imaging, Oxford, UK.
Neuroimage Clin. 2016 May 10;12:990-1003. doi: 10.1016/j.nicl.2016.05.004. eCollection 2016.
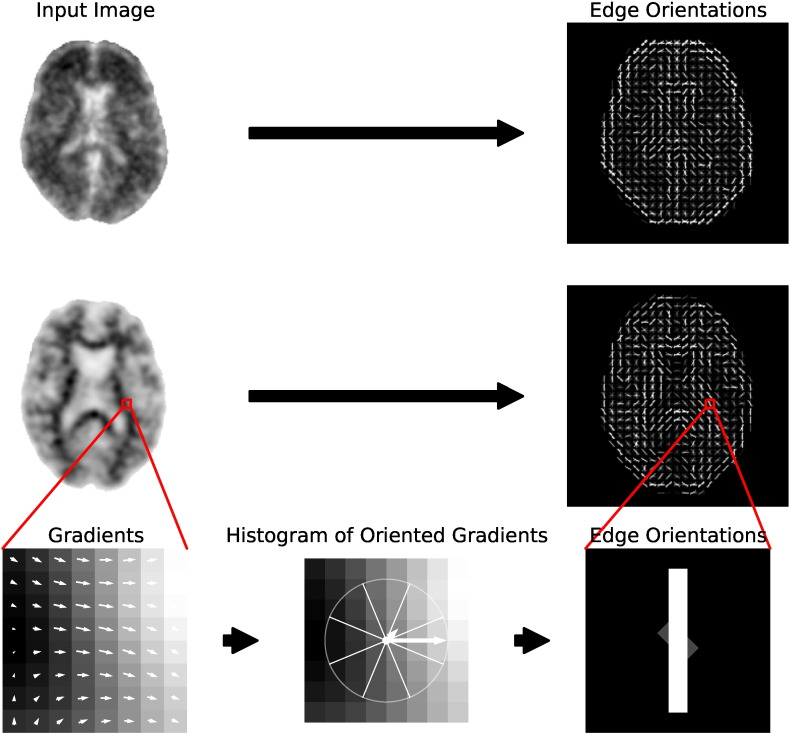
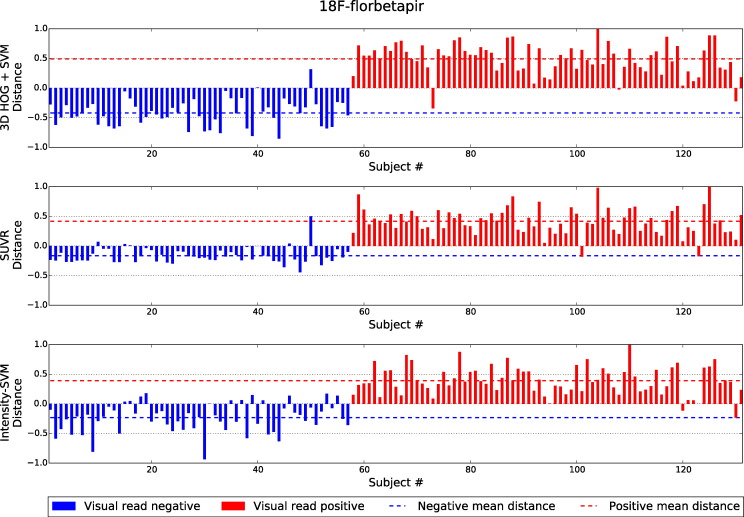
Brain amyloid burden may be quantitatively assessed from positron emission tomography imaging using standardised uptake value ratios. Using these ratios as an adjunct to visual image assessment has been shown to improve inter-reader reliability, however, the amyloid positivity threshold is dependent on the tracer and specific image regions used to calculate the uptake ratio. To address this problem, we propose a machine learning approach to amyloid status classification, which is independent of tracer and does not require a specific set of regions of interest. Our method extracts feature vectors from amyloid images, which are based on histograms of oriented three-dimensional gradients. We optimised our method on 133 F-florbetapir brain volumes, and applied it to a separate test set of 131 volumes. Using the same parameter settings, we then applied our method to 209 C-PiB images and 128 F-florbetaben images. We compared our method to classification results achieved using two other methods: standardised uptake value ratios and a machine learning method based on voxel intensities. Our method resulted in the largest mean distances between the subjects and the classification boundary, suggesting that it is less likely to make low-confidence classification decisions. Moreover, our method obtained the highest classification accuracy for all three tracers, and consistently achieved above 96% accuracy.
脑淀粉样蛋白负荷可通过使用标准化摄取值比率的正电子发射断层扫描成像进行定量评估。已证明将这些比率用作视觉图像评估的辅助手段可提高阅片者之间的可靠性,然而,淀粉样蛋白阳性阈值取决于用于计算摄取比率的示踪剂和特定图像区域。为了解决这个问题,我们提出了一种用于淀粉样蛋白状态分类的机器学习方法,该方法独立于示踪剂,并且不需要特定的感兴趣区域集。我们的方法从淀粉样蛋白图像中提取特征向量,这些特征向量基于定向三维梯度的直方图。我们在133个18F-氟比他班脑容积上对我们的方法进行了优化,并将其应用于131个容积的单独测试集。使用相同的参数设置,然后我们将我们的方法应用于209个11C-PiB图像和128个18F-氟贝他班图像。我们将我们的方法与使用其他两种方法获得的分类结果进行了比较:标准化摄取值比率和基于体素强度的机器学习方法。我们的方法在受试者与分类边界之间产生了最大的平均距离,这表明它做出低置信度分类决策的可能性较小。此外,我们的方法在所有三种示踪剂上都获得了最高的分类准确率,并且始终达到96%以上的准确率。