Department of Oral & Maxillofacial Surgery, Special Dental Care, and Orthodontics, Erasmus MC University Medical Center Rotterdam, Rotterdam, 3015 CE, The Netherlands.
Department of Medical Statistics and Bioinformatics, Leiden University Medical Center, Leiden, 2333 ZC, The Netherlands.
Sci Rep. 2018 Jan 8;8(1):12. doi: 10.1038/s41598-017-18294-x.
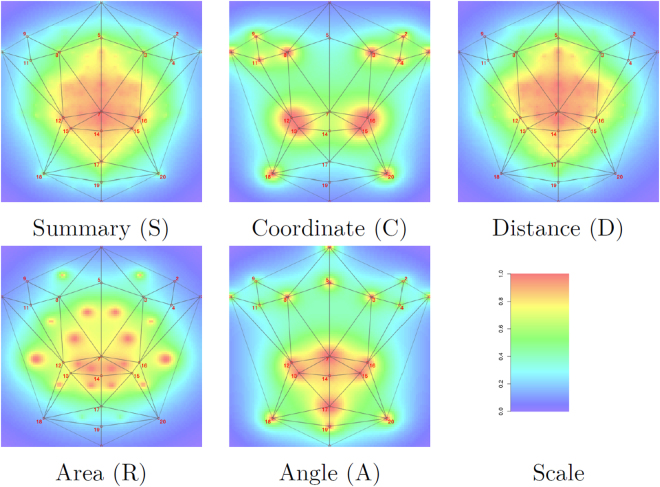
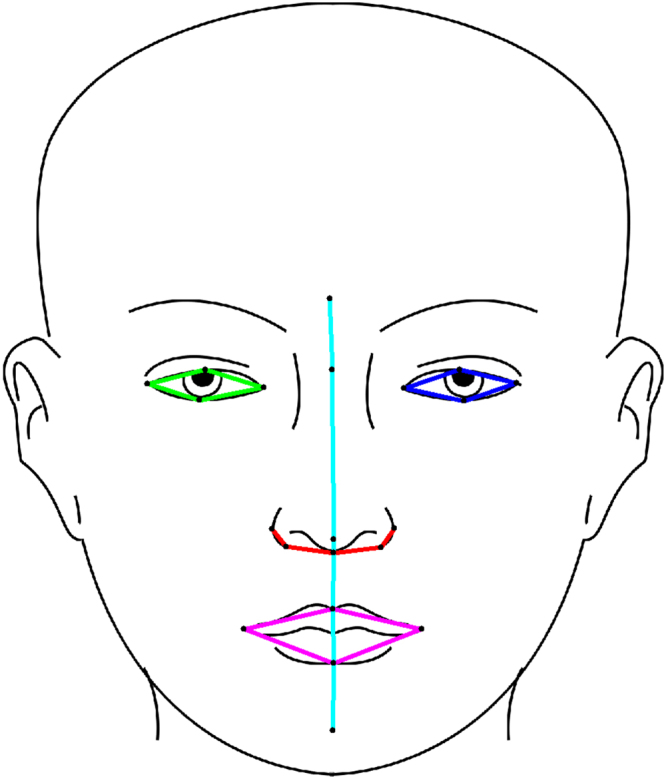
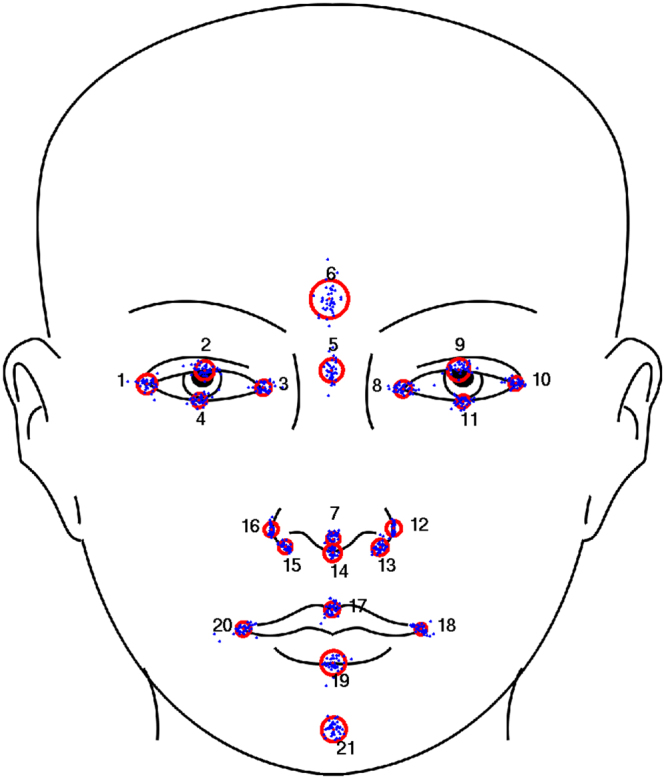
Landmarking of 3D facial surface scans is an important analysis step in medical and biological applications, such as genome-wide association studies (GWAS). Manual landmarking is often employed with considerable cost and rater dependent variability. Landmarking automatically with minimal training is therefore desirable. We apply statistical ensemble methods to improve automated landmarking of 3D facial surface scans. Base landmarking algorithms using features derived from 3D surface scans are combined using either bagging or stacking. A focus is on low training complexity of maximal 40 training samples with template based landmarking algorithms that have proved successful in such applications. Additionally, we use correlations between landmark coordinates by introducing a search strategy guided by principal components (PCs) of training landmarks. We found that bagging has no useful impact, while stacking strongly improves accuracy to an average error of 1.7 mm across all 21 landmarks in this study, a 22% improvement as compared to a previous, comparable algorithm. Heritability estimates in twin pairs also show improvements when using facial distances from landmarks. Ensemble methods allow improvement of automatic, accurate landmarking of 3D facial images with minimal training which is advantageous in large cohort studies for GWAS and when landmarking needs change or data quality varies.
3D 面部表面扫描的标志定位是医学和生物学应用(如全基因组关联研究(GWAS))中的一个重要分析步骤。手动标志定位通常需要大量的成本和评分者的差异性。因此,需要最小化训练的自动标志定位。我们应用统计集成方法来改进 3D 面部表面扫描的自动标志定位。使用源自 3D 表面扫描的特征的基础标志定位算法通过装袋或堆叠进行组合。重点是使用基于模板的标志定位算法,这些算法在这些应用中已经被证明是成功的,其训练复杂度最高可达 40 个训练样本。此外,我们通过引入基于训练标志主成分(PC)的搜索策略来利用标志坐标之间的相关性。我们发现装袋没有有用的影响,而堆叠则大大提高了准确性,在这项研究的所有 21 个标志中平均误差为 1.7mm,与以前的、可比的算法相比提高了 22%。当使用来自标志的面部距离时,双胞胎的遗传估计也有所提高。集成方法允许使用最小的训练来改进 3D 面部图像的自动、准确标志定位,这在 GWAS 的大型队列研究中以及标志定位需求发生变化或数据质量变化时非常有利。