Department of Biomedical Informatics, Columbia University, New York, New York, USA.
Department of Computing and Mathematical Sciences, University California Institute of Technology, Pasadena, California, USA.
J Am Med Inform Assoc. 2018 Oct 1;25(10):1392-1401. doi: 10.1093/jamia/ocy106.
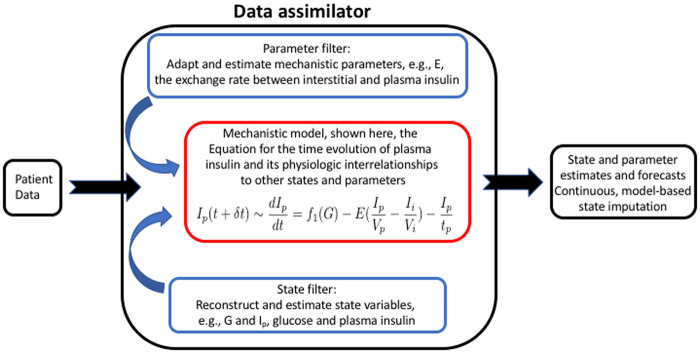
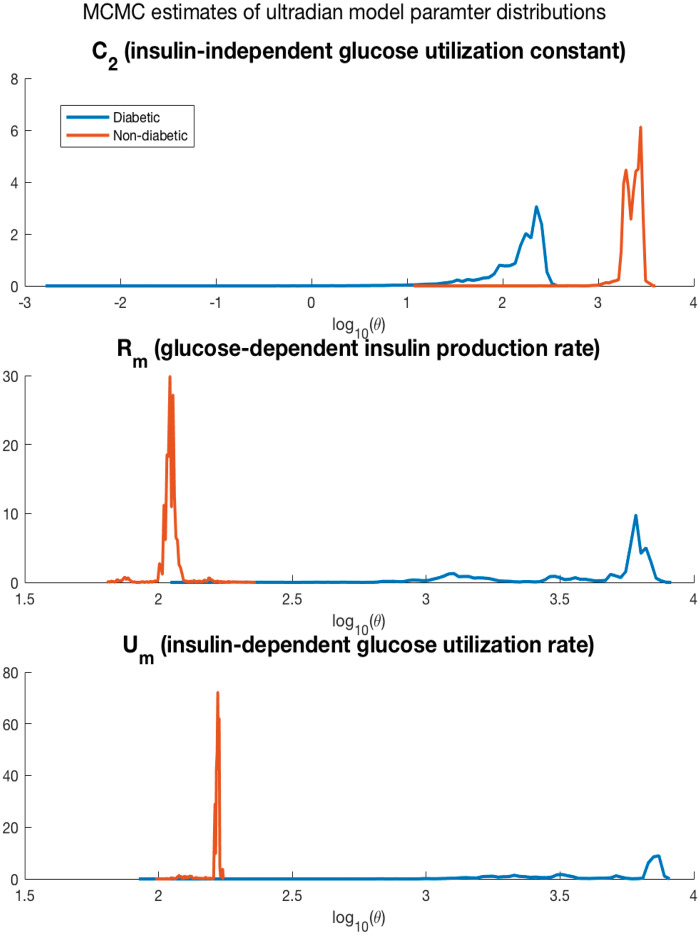
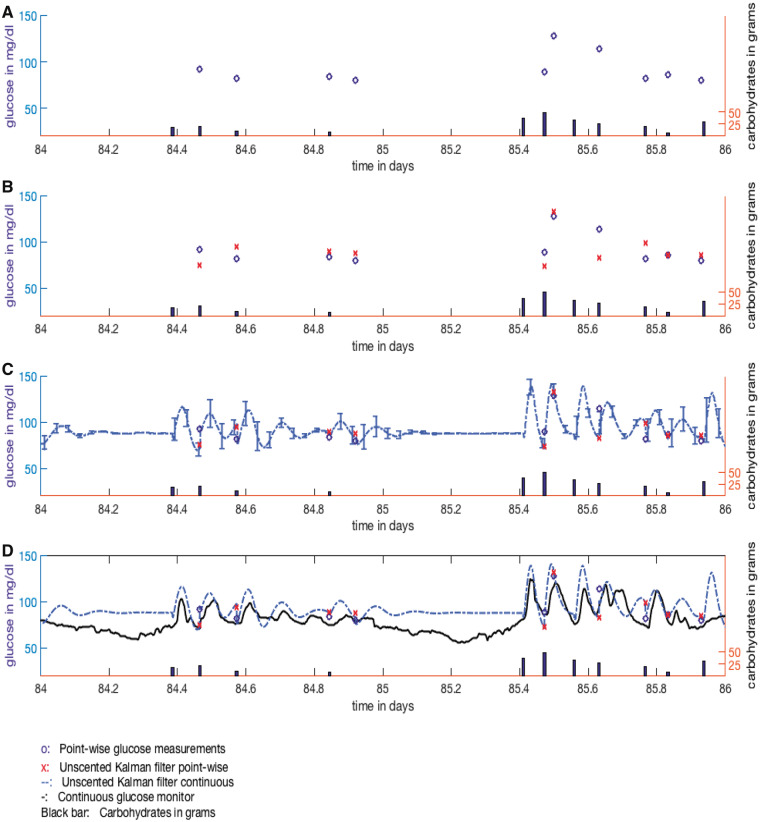
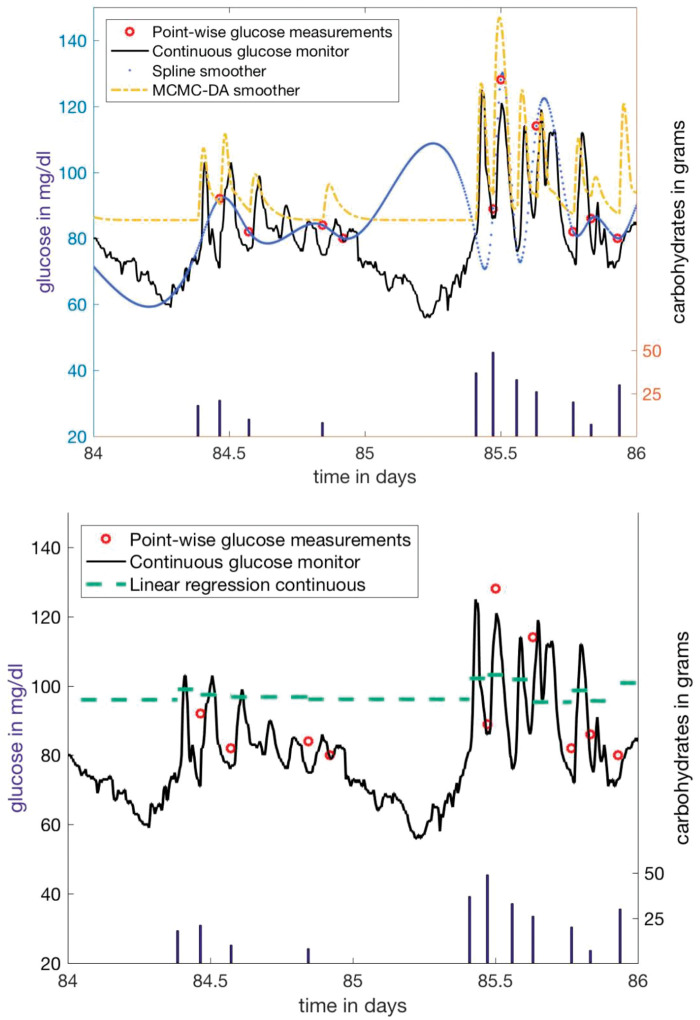
We introduce data assimilation as a computational method that uses machine learning to combine data with human knowledge in the form of mechanistic models in order to forecast future states, to impute missing data from the past by smoothing, and to infer measurable and unmeasurable quantities that represent clinically and scientifically important phenotypes. We demonstrate the advantages it affords in the context of type 2 diabetes by showing how data assimilation can be used to forecast future glucose values, to impute previously missing glucose values, and to infer type 2 diabetes phenotypes. At the heart of data assimilation is the mechanistic model, here an endocrine model. Such models can vary in complexity, contain testable hypotheses about important mechanics that govern the system (eg, nutrition's effect on glucose), and, as such, constrain the model space, allowing for accurate estimation using very little data.
我们介绍了数据同化,这是一种计算方法,它使用机器学习将数据与以机理模型形式呈现的人类知识相结合,以便预测未来状态,通过平滑来推断过去缺失的数据,并推断代表临床和科学上重要表型的可测量和不可测量的量。我们通过展示数据同化如何用于预测未来的葡萄糖值、推断以前缺失的葡萄糖值以及推断 2 型糖尿病表型,在 2 型糖尿病的背景下展示了它的优势。数据同化的核心是机理模型,这里是一个内分泌模型。这种模型可以在复杂性上有所不同,包含有关控制系统的重要力学的可测试假设(例如,营养对葡萄糖的影响),因此,限制了模型空间,允许使用非常少量的数据进行准确估计。