Antonelli Joseph, Claggett Brian L, Henglin Mir, Kim Andy, Ovsak Gavin, Kim Nicole, Deng Katherine, Rao Kevin, Tyagi Octavia, Watrous Jeramie D, Lagerborg Kim A, Hushcha Pavel V, Demler Olga V, Mora Samia, Niiranen Teemu J, Pereira Alexandre C, Jain Mohit, Cheng Susan
Department of Statistics, University of Florida, Gainesville, FL 32611, USA.
Cardiovascular Division, Brigham and Women's Hospital, Harvard Medical School, Boston, MA 02115, USA.
Metabolites. 2019 Jul 12;9(7):143. doi: 10.3390/metabo9070143.
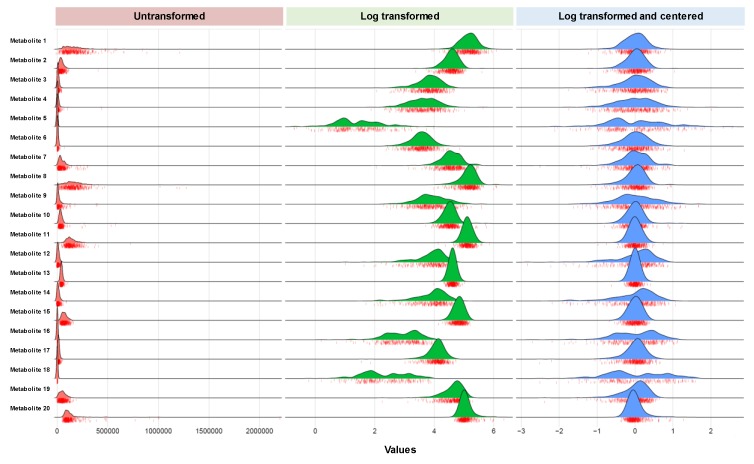
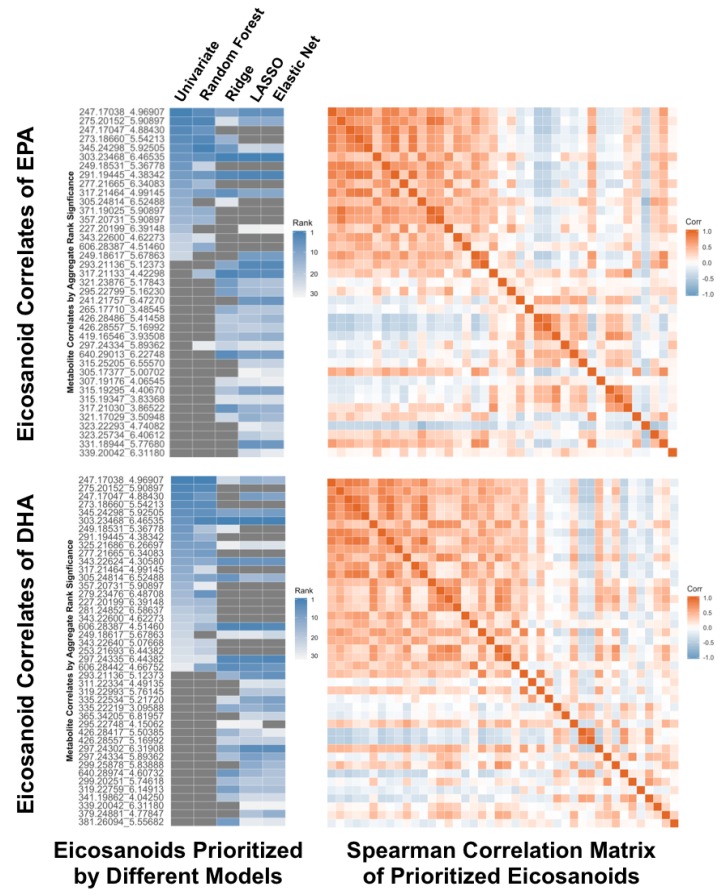
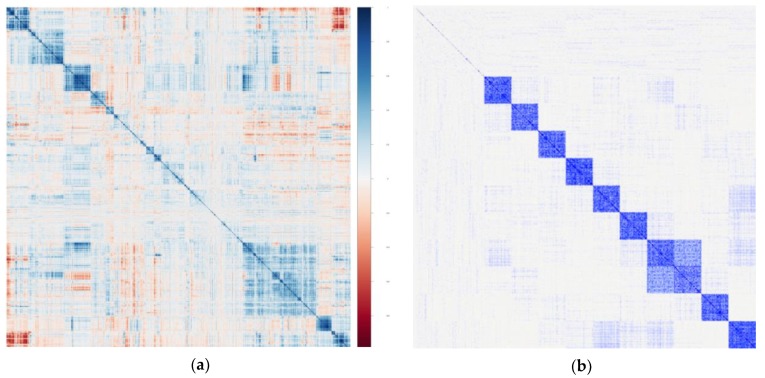
High-throughput metabolomics investigations, when conducted in large human cohorts, represent a potentially powerful tool for elucidating the biochemical diversity underlying human health and disease. Large-scale metabolomics data sources, generated using either targeted or nontargeted platforms, are becoming more common. Appropriate statistical analysis of these complex high-dimensional data will be critical for extracting meaningful results from such large-scale human metabolomics studies. Therefore, we consider the statistical analytical approaches that have been employed in prior human metabolomics studies. Based on the lessons learned and collective experience to date in the field, we offer a step-by-step framework for pursuing statistical analyses of cohort-based human metabolomics data, with a focus on feature selection. We discuss the range of options and approaches that may be employed at each stage of data management, analysis, and interpretation and offer guidance on the analytical decisions that need to be considered over the course of implementing a data analysis workflow. Certain pervasive analytical challenges facing the field warrant ongoing focused research. Addressing these challenges, particularly those related to analyzing human metabolomics data, will allow for more standardization of as well as advances in how research in the field is practiced. In turn, such major analytical advances will lead to substantial improvements in the overall contributions of human metabolomics investigations.
高通量代谢组学研究在大规模人类队列中进行时,是阐明人类健康和疾病背后生化多样性的一种潜在有力工具。使用靶向或非靶向平台生成的大规模代谢组学数据源正变得越来越普遍。对这些复杂的高维数据进行适当的统计分析,对于从此类大规模人类代谢组学研究中提取有意义的结果至关重要。因此,我们考虑了先前人类代谢组学研究中采用的统计分析方法。基于该领域迄今吸取的经验教训和集体经验,我们提供了一个逐步框架,用于对基于队列的人类代谢组学数据进行统计分析,重点是特征选择。我们讨论了在数据管理、分析和解释的每个阶段可能采用的选项和方法范围,并就实施数据分析工作流程过程中需要考虑的分析决策提供指导。该领域面临的某些普遍分析挑战需要持续的重点研究。应对这些挑战,尤其是与分析人类代谢组学数据相关的挑战,将使该领域的研究实践更加标准化,并取得进展。反过来,这种重大的分析进展将导致人类代谢组学研究的总体贡献大幅提高。