Information and Communication Technologies, Electronics and Applied Mathematics (ICTEAM), Université catholique de Louvain, B-1348, Louvain-la-Neuve, Belgium.
Department of Computing, Imperial College London, London, SW7 2AZ, UK.
Nat Commun. 2019 Jul 23;10(1):3069. doi: 10.1038/s41467-019-10933-3.
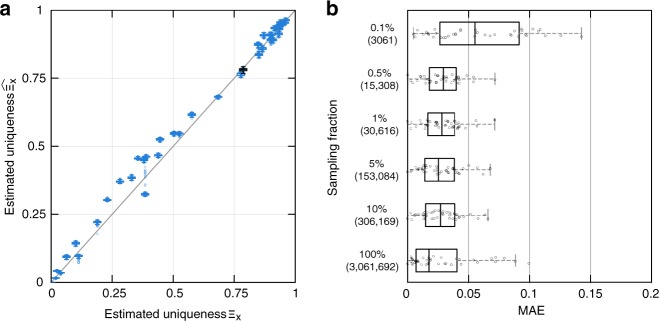
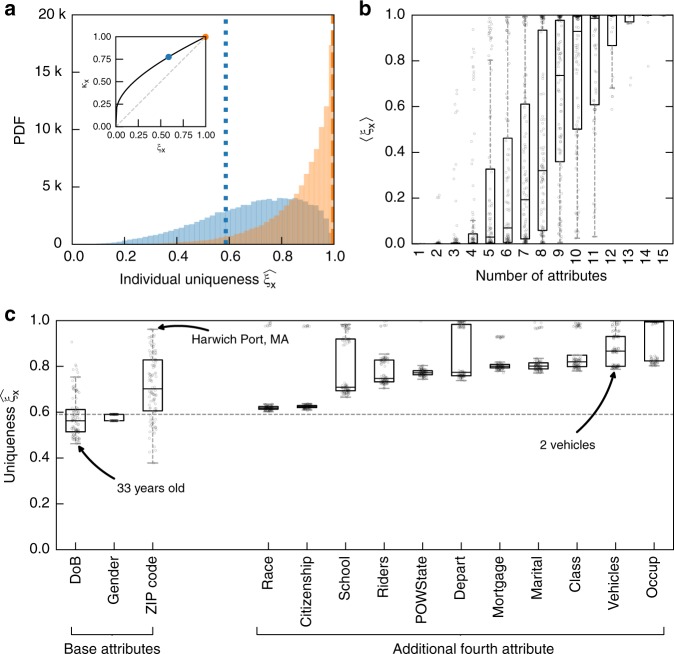
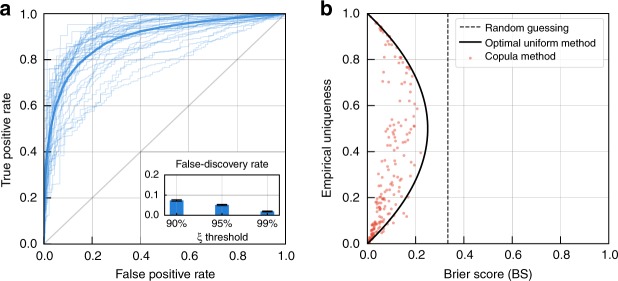
While rich medical, behavioral, and socio-demographic data are key to modern data-driven research, their collection and use raise legitimate privacy concerns. Anonymizing datasets through de-identification and sampling before sharing them has been the main tool used to address those concerns. We here propose a generative copula-based method that can accurately estimate the likelihood of a specific person to be correctly re-identified, even in a heavily incomplete dataset. On 210 populations, our method obtains AUC scores for predicting individual uniqueness ranging from 0.84 to 0.97, with low false-discovery rate. Using our model, we find that 99.98% of Americans would be correctly re-identified in any dataset using 15 demographic attributes. Our results suggest that even heavily sampled anonymized datasets are unlikely to satisfy the modern standards for anonymization set forth by GDPR and seriously challenge the technical and legal adequacy of the de-identification release-and-forget model.
虽然丰富的医学、行为和社会人口统计学数据是现代数据驱动研究的关键,但它们的收集和使用引发了合理的隐私担忧。在共享之前,通过去识别和抽样对数据集进行匿名化是解决这些问题的主要工具。我们在这里提出了一种基于生成式 Copula 的方法,可以准确估计特定个体被正确重新识别的可能性,即使在严重不完整的数据集也是如此。在 210 个人群中,我们的方法对于预测个体独特性的 AUC 得分从 0.84 到 0.97 不等,假阳性率很低。使用我们的模型,我们发现,在使用 15 个人口统计学属性的任何数据集,99.98%的美国人都可以被正确重新识别。我们的研究结果表明,即使是经过大量抽样的匿名化数据集,也不太可能满足 GDPR 规定的现代匿名化标准,并严重挑战去识别即发布和遗忘模型的技术和法律充分性。