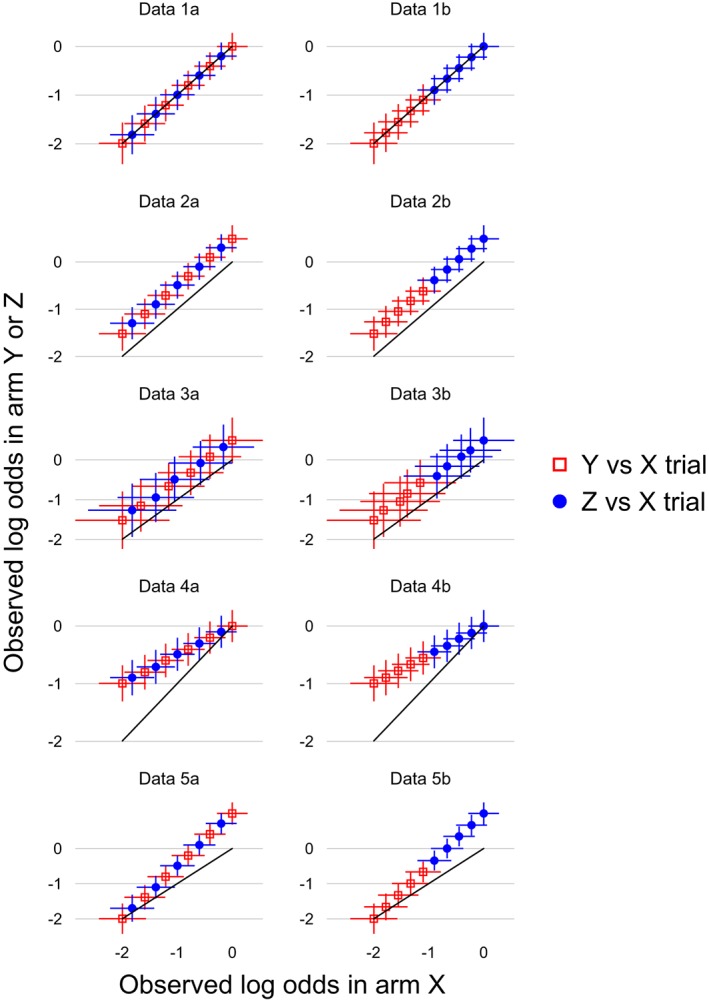
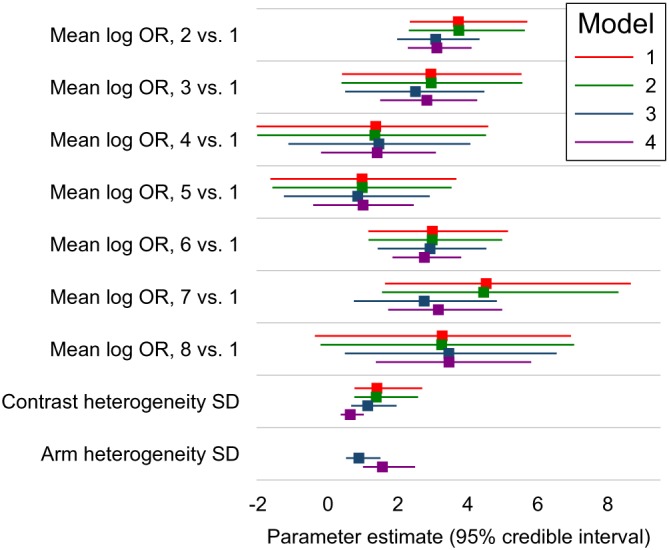
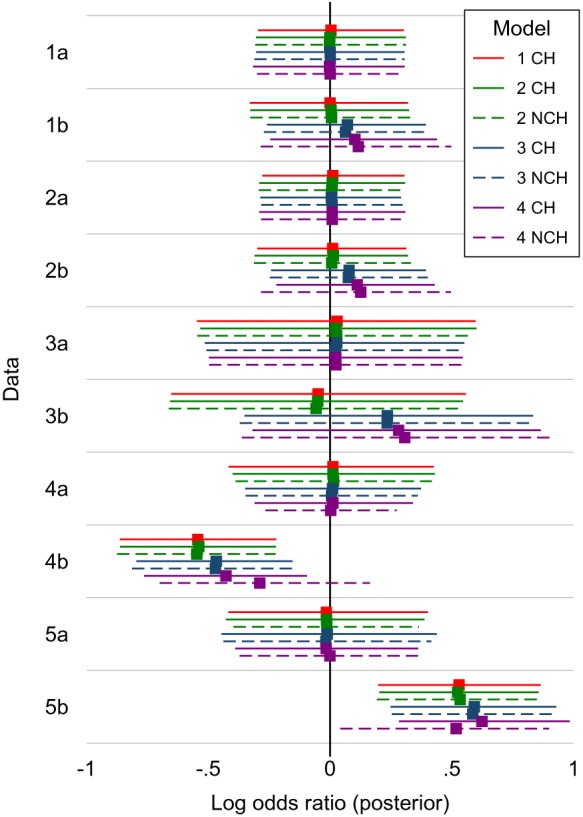
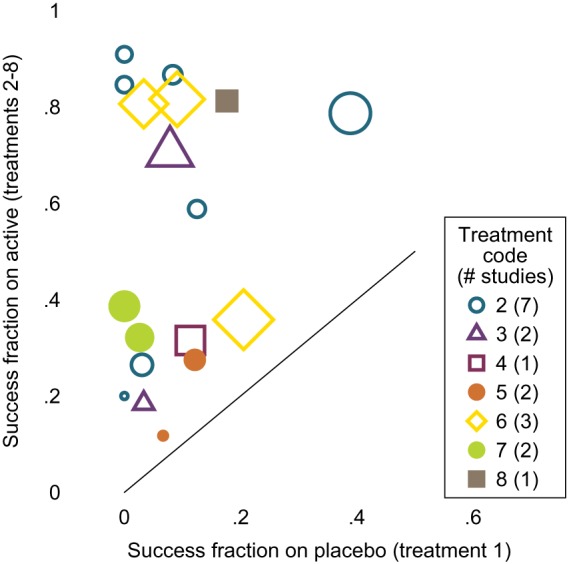
White Ian R, Turner Rebecca M, Karahalios Amalia, Salanti Georgia
MRC Clinical Trials Unit at UCL, Institute of Clinical Trials and Methodology, London, UK.
School of Public Health and Preventive Medicine, Monash University, Melbourne, Australia.
Stat Med. 2019 Nov 30;38(27):5197-5213. doi: 10.1002/sim.8360. Epub 2019 Oct 3.
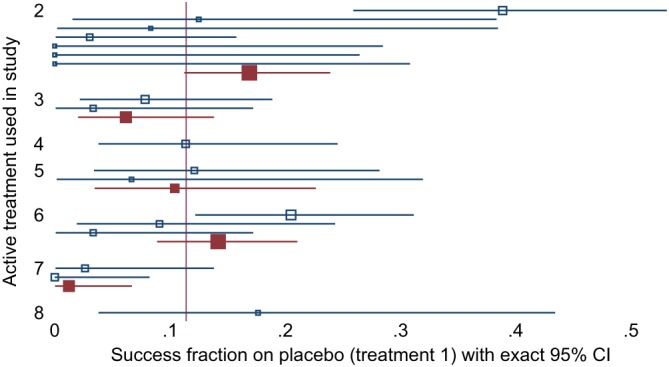
Differences between arm-based (AB) and contrast-based (CB) models for network meta-analysis (NMA) are controversial. We compare the CB model of Lu and Ades (2006), the AB model of Hong et al(2016), and two intermediate models, using hypothetical data and a selected real data set. Differences between models arise primarily from study intercepts being fixed effects in the Lu-Ades model but random effects in the Hong model, and we identify four key difference. (1) If study intercepts are fixed effects then only within-study information is used, but if they are random effects then between-study information is also used and can cause important bias. (2) Models with random study intercepts are suitable for deriving a wider range of estimands, eg, the marginal risk difference, when underlying risk is derived from the NMA data; but underlying risk is usually best derived from external data, and then models with fixed intercepts are equally good. (3) The Hong model allows treatment effects to be related to study intercepts, but the Lu-Ades model does not. (4) The Hong model is valid under a more relaxed missing data assumption, that arms (rather than contrasts) are missing at random, but this does not appear to reduce bias. We also describe an AB model with fixed study intercepts and a CB model with random study intercepts. We conclude that both AB and CB models are suitable for the analysis of NMA data, but using random study intercepts requires a strong rationale such as relating treatment effects to study intercepts.
用于网络荟萃分析(NMA)的基于臂(AB)的模型和基于对比(CB)的模型之间的差异存在争议。我们使用假设数据和一个选定的真实数据集,比较了Lu和Ades(2006年)的CB模型、Hong等人(2016年)的AB模型以及两个中间模型。模型之间的差异主要源于在Lu-Ades模型中研究截距是固定效应,而在Hong模型中是随机效应,并且我们确定了四个关键差异。(1)如果研究截距是固定效应,那么仅使用研究内信息,但如果它们是随机效应,那么也使用研究间信息,这可能会导致重要偏差。(2)具有随机研究截距的模型适用于推导更广泛的估计量,例如,当潜在风险从NMA数据中得出时的边际风险差异;但潜在风险通常最好从外部数据中得出,然后具有固定截距的模型同样适用。(3)Hong模型允许治疗效应与研究截距相关,但Lu-Ades模型不允许。(4)Hong模型在更宽松的缺失数据假设下有效,即臂(而非对比)随机缺失,但这似乎并没有减少偏差。我们还描述了一个具有固定研究截距的AB模型和一个具有随机研究截距的CB模型。我们得出结论,AB模型和CB模型都适用于NMA数据的分析,但使用随机研究截距需要强有力的理由,例如将治疗效应与研究截距相关联。