Petch Jeremy, Batt Jane, Murray Joshua, Mamdani Muhammad
Institute of Health Policy, Management and Evaluation, Dalla Lana School of Public Health, University of Toronto, Toronto, ON, Canada.
Centre for Data Science and Digital Health, Hamilton Health Sciences, Hamilton, ON, Canada.
JMIR Med Inform. 2019 Nov 1;7(4):e12575. doi: 10.2196/12575.
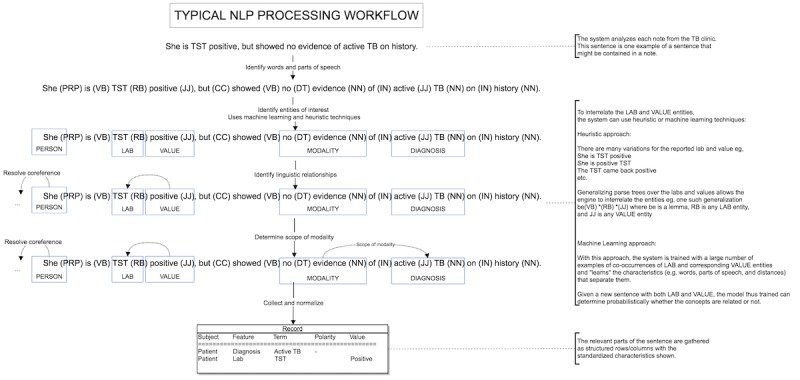
The increasing adoption of electronic health records (EHRs) in clinical practice holds the promise of improving care and advancing research by serving as a rich source of data, but most EHRs allow clinicians to enter data in a text format without much structure. Natural language processing (NLP) may reduce reliance on manual abstraction of these text data by extracting clinical features directly from unstructured clinical digital text data and converting them into structured data.
This study aimed to assess the performance of a commercially available NLP tool for extracting clinical features from free-text consult notes.
We conducted a pilot, retrospective, cross-sectional study of the accuracy of NLP from dictated consult notes from our tuberculosis clinic with manual chart abstraction as the reference standard. Consult notes for 130 patients were extracted and processed using NLP. We extracted 15 clinical features from these consult notes and grouped them a priori into categories of simple, moderate, and complex for analysis.
For the primary outcome of overall accuracy, NLP performed best for features classified as simple, achieving an overall accuracy of 96% (95% CI 94.3-97.6). Performance was slightly lower for features of moderate clinical and linguistic complexity at 93% (95% CI 91.1-94.4), and lowest for complex features at 91% (95% CI 87.3-93.1).
The findings of this study support the use of NLP for extracting clinical features from dictated consult notes in the setting of a tuberculosis clinic. Further research is needed to fully establish the validity of NLP for this and other purposes.
临床实践中电子健康记录(EHR)的使用日益增加,有望通过作为丰富的数据来源来改善医疗服务并推进研究,但大多数电子健康记录允许临床医生以文本格式输入数据,结构较少。自然语言处理(NLP)可以通过直接从非结构化临床数字文本数据中提取临床特征并将其转换为结构化数据,减少对这些文本数据人工提取的依赖。
本研究旨在评估一种商用自然语言处理工具从自由文本会诊记录中提取临床特征的性能。
我们进行了一项试点、回顾性横断面研究,以人工图表提取为参考标准,评估自然语言处理从我们结核病诊所的口述会诊记录中提取信息的准确性。使用自然语言处理提取并处理了130名患者的会诊记录。我们从这些会诊记录中提取了15个临床特征,并将它们预先分为简单、中等和复杂三类进行分析。
对于总体准确性这一主要结果,自然语言处理在分类为简单的特征上表现最佳,总体准确率达到96%(95%可信区间94.3 - 97.6)。对于临床和语言复杂性中等的特征,性能略低,为93%(95%可信区间91.1 - 94.4),而对于复杂特征最低,为91%(95%可信区间87.3 - 93.1)。
本研究结果支持在结核病诊所环境中使用自然语言处理从口述会诊记录中提取临床特征。需要进一步研究以充分确立自然语言处理在此及其他目的方面的有效性。