The Wellcome Centre for Human Neuroimaging, UCL Queen Square Institute of Neurology, London, WC1N 3AR, UK.
Hear Res. 2021 Jan;399:107998. doi: 10.1016/j.heares.2020.107998. Epub 2020 May 20.
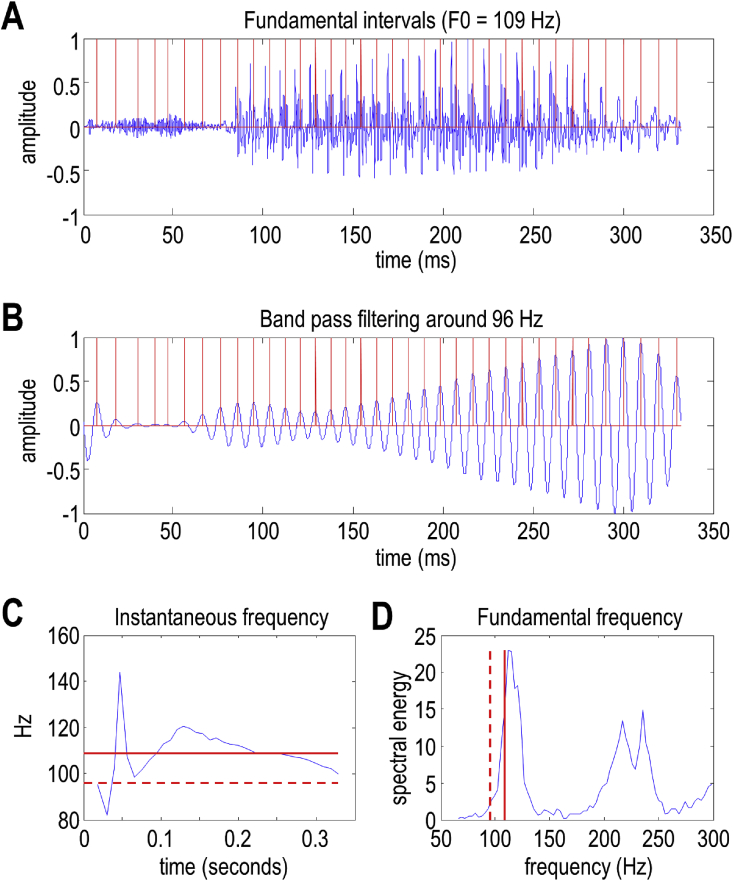
This paper introduces active listening, as a unified framework for synthesising and recognising speech. The notion of active listening inherits from active inference, which considers perception and action under one universal imperative: to maximise the evidence for our (generative) models of the world. First, we describe a generative model of spoken words that simulates (i) how discrete lexical, prosodic, and speaker attributes give rise to continuous acoustic signals; and conversely (ii) how continuous acoustic signals are recognised as words. The 'active' aspect involves (covertly) segmenting spoken sentences and borrows ideas from active vision. It casts speech segmentation as the selection of internal actions, corresponding to the placement of word boundaries. Practically, word boundaries are selected that maximise the evidence for an internal model of how individual words are generated. We establish face validity by simulating speech recognition and showing how the inferred content of a sentence depends on prior beliefs and background noise. Finally, we consider predictive validity by associating neuronal or physiological responses, such as the mismatch negativity and P300, with belief updating under active listening, which is greatest in the absence of accurate prior beliefs about what will be heard next.
本文介绍了主动倾听,作为一种将语音综合和识别的统一框架。主动倾听的概念源自主动推断,它将感知和行动置于一个普遍的准则之下:最大限度地提高我们对世界生成模型的证据。首先,我们描述了一个口语单词的生成模型,该模型模拟了(i)离散的词汇、韵律和说话人属性如何产生连续的声学信号;以及相反地(ii)如何将连续的声学信号识别为单词。“主动”方面涉及(隐蔽地)分割口语句子,并借鉴主动视觉的思想。它将语音分割看作是内部动作的选择,对应于单词边界的位置。实际上,选择的单词边界可以最大限度地提高关于单词生成方式的内部模型的证据。我们通过模拟语音识别来建立表面有效性,并展示句子的推断内容如何取决于先验信念和背景噪声。最后,我们通过将神经元或生理反应(如失匹配负波和 P300)与主动倾听下的信念更新相关联来考虑预测有效性,在缺乏对接下来会听到的内容的准确先验信念的情况下,这种更新最为强烈。